Hello everyone, I am Azu. Today I want to speak more harshly: In DEX and perpetual contracts, the most terrifying data anomaly is never "the price is slightly wrong," but rather "the price does not update at critical moments, updates too slowly, or is distorted by someone in a short period of time," because losses in trading protocols are magnified instantaneously. The liquidation line for lending is a one-size-fits-all, while DEX and perpetuals are more like highways—if you give it an expired road condition, it doesn't slow down; it crashes directly: slippage suddenly goes out of control, execution prices deviate from expectations, limit orders/stop-loss orders trigger logic misalignment, funding rates are distorted, and even lead to chain liquidations and systemic insolvency.
First, let's clarify what DEX fears the most. Many people mistakenly believe that DEX pricing relies solely on AMM pools; in fact, once you enter more complex trading forms—aggregator routing, RFQ quotes, protected limit/stop-loss orders, dynamic fees, or even cross-chain trading—you will find that "reference price" is crucial. If there is a delay in the reference price, the most direct consequence is that you think you are making a normal transaction, but the actual transaction price has long lagged behind the market, distorting slippage expectations. Users are not just "paying a little more"; they are "paying a lot more," and may also experience transaction rollbacks due to triggered protection parameters. A more hidden anomaly is the "instant spike": short-term erroneous quotes can cause routing algorithms to choose the wrong path and misjudge risk control thresholds. What users see is not price fluctuations, but rather "suddenly getting burned." In such scenarios, the oracle's task is not to replace the market, but to provide a more real-time anchor point for transactions, especially in extreme market conditions. The more delayed the anchor point, the more easily the system can be driven by noise.

Perpetual contracts are more extreme because they almost treat "oracle input" as a lifeline. Perpetuals require a reliable spot price (usually an aggregated index price from multiple trading venues) for clearing, funding rates, and risk control; if this price is manipulated or expires, clearing will become "executed based on erroneous facts," and losses could be multiplied several times due to leverage. Academic research has written this very plainly: perpetual exchanges need a price oracle from the spot market and often aggregate multiple trading venues to improve overall liquidity representation, thereby increasing manipulation costs. You can translate this sentence into a more colloquial style: perpetuals are not about who can design the best UI, but about who can get "the price that's harder to manipulate" during the most chaotic times.
So today's main focus is on "Why Data Pull / Pull Oracle is more suitable for trading." The biggest fear of trading protocols is that "the pace of your updates cannot keep up with the pace of market changes." Traditional push updates (Data Push) usually upload data to the chain based on thresholds or time intervals, saving costs in normal times, but during high volatility, it is easy to encounter the situation of "I need the latest price, but the chain hasn't updated yet." ZetaChain's APRO introduction clearly explains this difference: Data Pull is on-demand access, characterized by high-frequency updates and low latency, especially suitable for DeFi protocols and DEXs that require quick data but do not want to continuously bear the cost of on-chain updates. APRO's own documentation positions Data Pull as "on-demand, real-time Price Feed," emphasizing high frequency, low latency, and cost efficiency, adapting to the demand structure of trading protocols that only need the freshest price at the moment of need. The logic behind this is actually quite simple: trading does not require you to write prices on the chain every second of every hour; it only needs the latest price at the moment of transaction, clearing, and matching—binding updates to the occurrence of the transaction aligns better with the real trade-offs of cost and timeliness.
You can use Pyth's pull model as an intuitive comparison: it explicitly explains in its developer documentation that pull oracles can update more frequently than push oracles, and provides examples showing that price sources can achieve updates at the 400ms level, and high-frequency updates also mean lower latency data availability. I'm not saying all systems need to operate at this magnitude; I want you to understand that "the time scale of the trading battlefield" has changed: when the market completes a large candlestick within tens of seconds, minute-level updates become a critical flaw, especially for perpetuals, where an expired price is not just an error, but a risk exposure.
This also brings about the rule changes you asked me to clarify: trading protocols may prefer on-demand data when selecting oracles. In the past, project parties would use slogans like "covering multiple assets, fast updates" to gloss over the issue; in the future, it will be more akin to audit-style selection—can you provide verifiable latest prices when a trade occurs, how is your update triggered, how do you handle spikes and anomalies, can you increase manipulation costs, and can you compress the "delay window" to be sufficiently small during high volatility? ZetaChain directly writes Data Pull as the ideal solution for DEX/DeFi, which is effectively institutionalizing the requirement of "on-demand high-frequency low-latency" rather than just an engineer's personal preference.
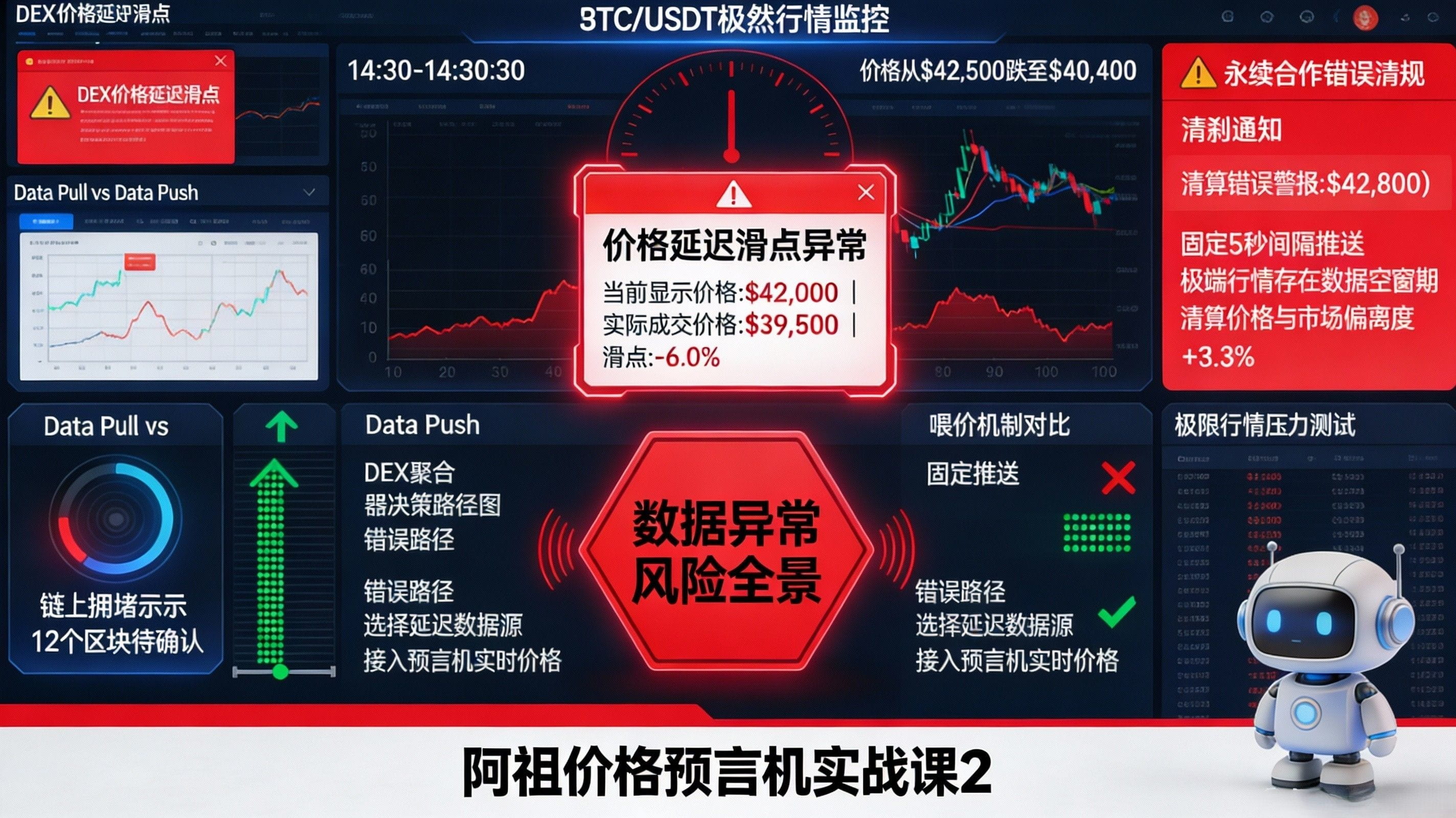
Regarding user impact, I suggest you understand it as "the explainability of trading experience and slippage expectations will improve." The slippage you see on DEX often isn't because you set it too small, but rather because the reference price anchor is not fresh or stable enough; the anomalies you encounter in perpetuals aren't always because you made the wrong directional call, but because the system used a price that wasn't timely or was distorted in the short term to adjudicate your position. When the protocol employs a price feeding system that is closer to real-time and harder to manipulate, the explanation space for users about "why the transaction was executed here, why the stop loss was here, and why this time there was no abnormal spike" will expand, making trading feel more like "controllable risk" rather than "hoping the network doesn't glitch."
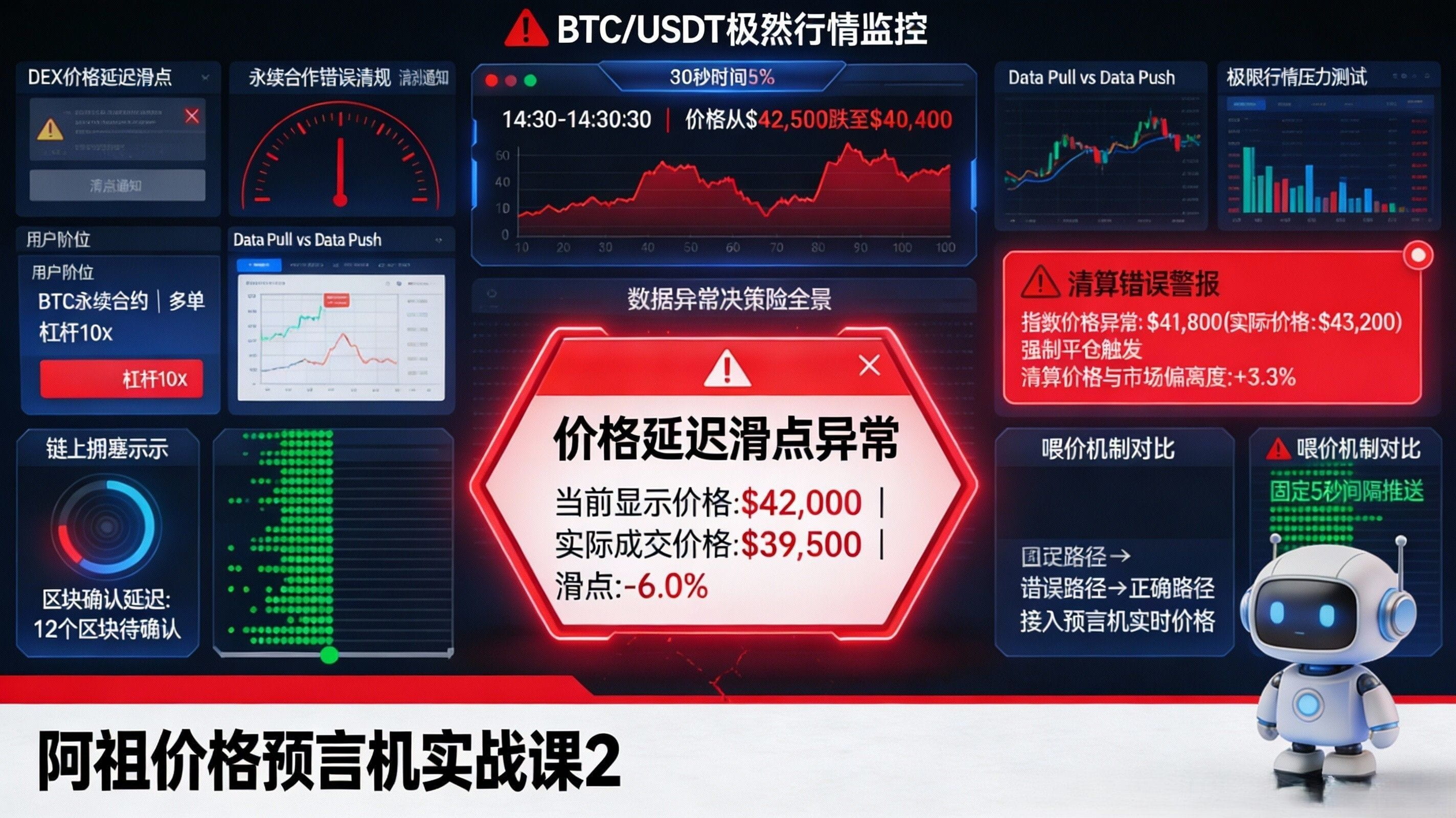
Finally, as per your request, here is a "stress test scenario for extreme market conditions of popular trading pairs" that you can directly use as interactive content. Let's use BTC/USDT (or ETH/USDT, which your fans are most familiar with) as an example: assume a sudden fluctuation of 5% within 30 seconds, while the chain is congested, DEX aggregator routing needs to make quick path judgments, and perpetual clearing bots are trying to get ahead. If the oracle is a slow-updating push, the on-chain price may lag behind the spot by several steps, leading to sudden expansion of slippage on the DEX side and frequent rollbacks of transaction protections; on the perpetual side, funding rates and index prices may be misaligned for a short time, making the clearing trigger point unreliable. In contrast, if the protocol adopts an on-demand pull model, binding price updates to the transaction itself, you should ask three more "risk control-like" questions: can this update get the latest price within the same transaction, is there filtering for abnormal spikes or confidence interval constraints, and does aggregation from multiple sources increase manipulation costs and have fallback/pause mechanisms in conflicts? You throw these three questions at the readers, and they will realize for the first time: what is known as "trading experience" is often not about UI details, but whether the data system remains credible under extreme conditions.




