Having been in the cryptocurrency world for 10 years, when I first entered, I suffered significant losses. There were ups and downs along the way, but now I rely on the cryptocurrency world to support my family 🛫
I summarized my experiences and shared them with everyone, hoping to help you. As long as you can do it, it's hard to lose! For reference only!
If you were to define the cryptocurrency world, how would you describe it? Everyone might have different answers, but no one can prove whether their definition is right or wrong. Every statement has its conditions of rationality, and every statement also has situations where it cannot be applied—this is the essence of 'chaos.'
In a chaotic market, many people always try to see everything clearly. However, the longer one survives in the market, the more one can appreciate that the market itself is disordered. 'Simplicity is the ultimate sophistication' may be the most effective principle when facing the market.
So how can you excel in trading cryptocurrencies? Once a person enters the financial market, it's hard to turn back. If you are currently in a loss but still confused, and plan to treat cryptocurrency trading as a second profession, you must understand the 'DPO indicator strategy.' Understanding it thoroughly can help you avoid many detours. These are personal experiences and feelings. I suggest you keep this in mind and reflect on it repeatedly!
DPO = optimizing chosen - rejected
The calculation process of DPO is roughly as follows
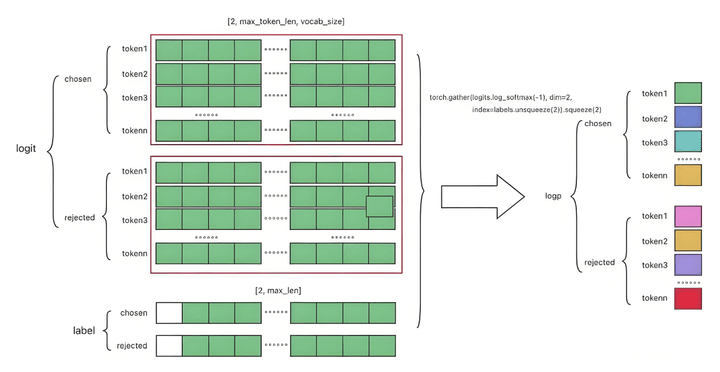
During the DPO optimization process, there is uncertainty in the optimization direction for chosen, as DPO optimization only guarantees an overall increase in margin, rather than solely increasing chosen probability.
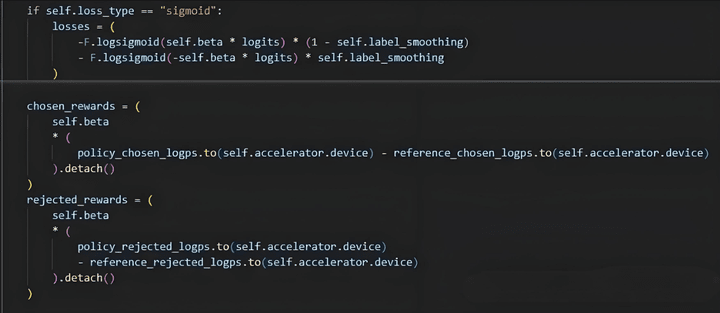
The loss and formulas for chosen and rejected are as follows.
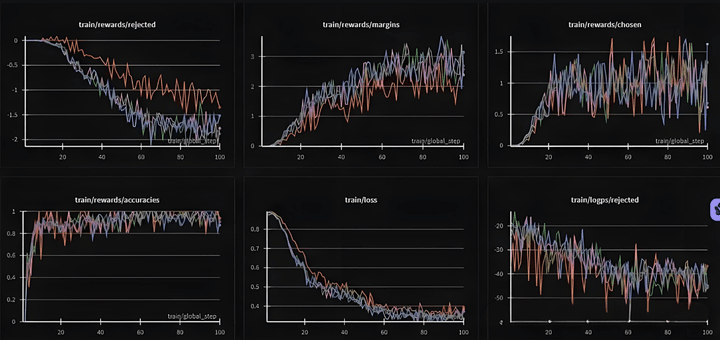
Here, the llama-factory's built-in dpo_en_demo dataset is used for DPO training, and both rejected and chosen are seen to be rising, with the margin also increasing.
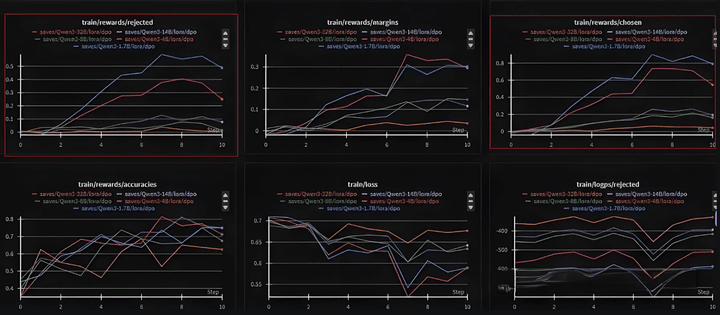
The ideal situation is for chosen to increase and rejected to decrease. However, when the data is poor or parameter settings are unreasonable, situations where chosen/rejected rise or fall simultaneously may occur.
Below, we switch to the Qwen2.5 model for DPO training, where both chosen and rejected are seen to be decreasing.
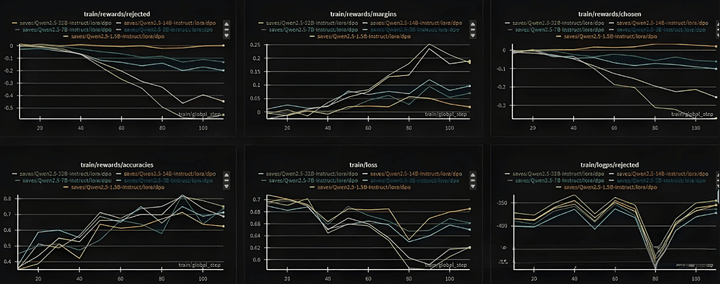
Below are the pairs obtained using actual business data to train SFT's Qwen2.5, with weights applied to some SFT losses to ensure that model weight results do not deviate too much from the original model.
The reason why chosen and rejected may rise or fall simultaneously can be referenced:
Little Winter Melon AIGC: Why do the probabilities of Chosen and Rejected decline simultaneously in DPO???
ChenShawn: [Unreliable] A hypothesis regarding why the rewards for chosen and rejected decline together during DPO training.
Sonsii: DPO and its derivative algorithm XX-ODPO training process shows a decline in chosen reward.
From a theoretical analysis, chosen_reward is model_chosen_logp - ref_chosen_logp, and since logp is the logits probability of each next token. An increase in chosen_reward indicates that compared to the original model, the updated model has a higher probability of outputting next token = chosen token, which means the model's output is getting closer to the chosen sample. The same logic applies to rejected.
Conversely, if chosen_reward decreases, it indicates that after model updates, it moves further away from the chosen sample. The same applies to rejected.
Therefore, good training results mean an increase in chosen_reward (output logits closer) and a decrease in rejected_rewards (output logits further from bad). Besides, this indicates that the training data pairs do not have sufficient discernibility for the model. (In summary, the reward score is the change direction between update_model and ref_model under the same sample, whether approaching or being consistent.)
The loss score is the change in the difference between the success of the update_model and the success of the ref_model.
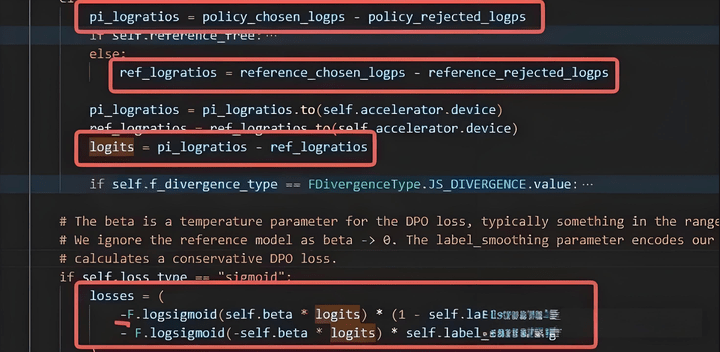
A smaller loss indicates larger logits; if ref_logratios remain unchanged, it means the difference in performance between update_model becomes larger. If we further assume that policy_rejected_logps remain unchanged, it means coming closer to chosen outputs policy_chosen_logps.
Usually, during DPO training, the rejected samples are the model's outputs, while chosen are optimized by a better model. Therefore, there’s a question: is rejected output by the current model, and how does it affect training effectiveness?
Based on the above analysis, considering that ref_logratios remain unchanged, the loss update will cause the update_model to be closer to chosen or further from rejected, or both (it will definitely be both). No matter the sample, getting closer to chosen is definitely okay. However, if rejected is not produced by the SFT model, moving away from a rejected that would not be output anyway (like lowering the probability of an event that has a probability of 0) is not very meaningful; this part of the effect will be lost, thus diminishing the overall DPO effect.
More intuitively, it can be explained as: margin = chosen - rejected = 0.5 - (-0.3) = 0.8. Now this -0.3 of learning is meaningless; only 0.5 of 0.8 is real and effective.
KTO: DPO -> Unilateral Learning
KTO: Model Alignment as Prospect Theoretic Optimization LLM RLHF 2024 Paper (8) KTO
Considering that the loss of DPO is optimizing margin, which is the difference between chosen and rejected, it is possible for both sides to rise or fall simultaneously while the margin still increases. Therefore, if one side is fixed, the effect of optimizing the other part can be enhanced. For instance, if rejected is set to 0, then optimizing margin becomes optimizing chosen, and the same logic applies to fixing chosen.

At this point, the reward optimization method changes to a method similar to SFT (no longer requiring preference data). Because it approaches the SFT method, KTO training can be done directly on the base model. However, compared to SFT, KTO requires a reference model.
Set kto_tag; if true, the chosen data remains unchanged and rejected_logits is set to 0, and vice versa. This allows independent processing of both types of data to achieve SFT effects, enabling training on imbalanced positive and negative sample data.
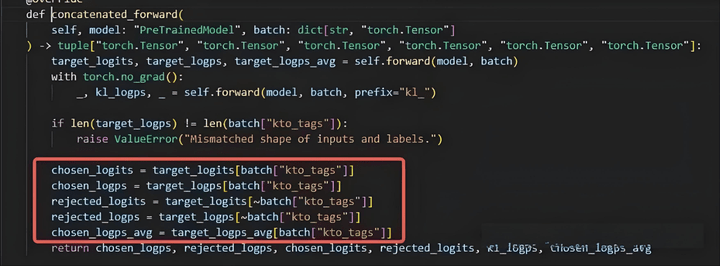
The HALO method mentioned in the paper can actually be disregarded.
Comparison of KTO and SFT: SFT data can only be good cases, while KTO data can be bad cases. KTO requires a reference model.
Comparison between DPO and KTO: DPO may encounter the problem of decreased chosen_reward leading to poor effectiveness, while KTO can ensure that the model is closer to chosen. DPO is suitable for pair data where chosen is clearly better than rejected.
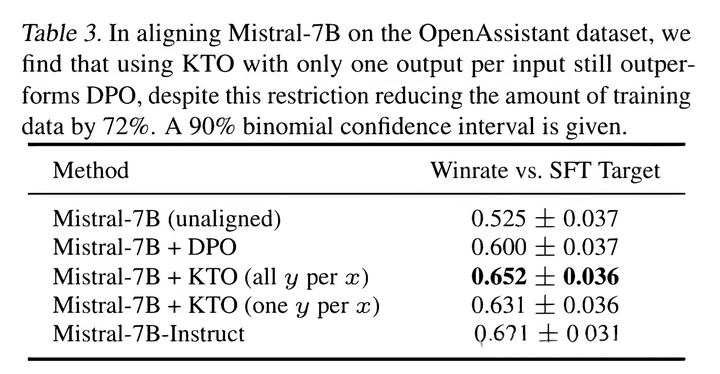
The paper states that KTO's effects are generally stronger than those of DPO. Actual results still depend on data quality (currently, my personal testing shows DPO to be slightly better).
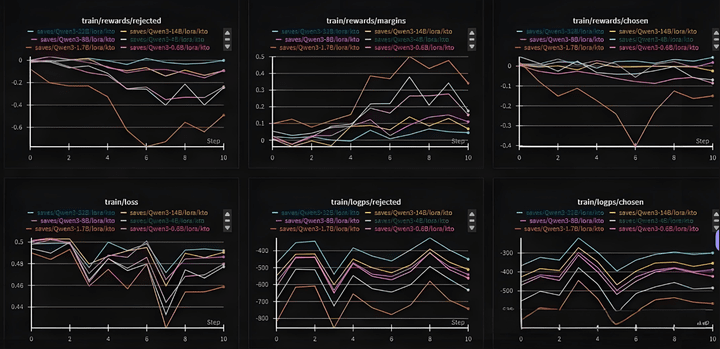
In actual testing, chosen still slightly declines.
ORPO: SFT + k*RL
ORPO: Monolithic Preference Optimization without Reference Model Can't afford the big model's PPO, DPO preference optimization algorithms? Then I suggest you look at ORPO (more cost-effective!)
ORPO builds on DPO, removing the reference model and adding loss based on odds ratio. It also combines SFT loss, merging the SFT and RLHF processes into one.
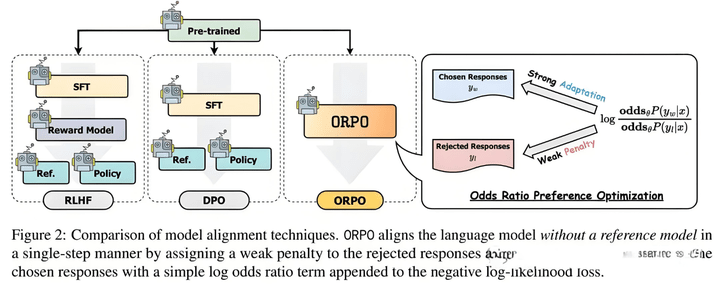
The loss is defined as follows: first, define odds, which means increasing the original probability (accelerating model updates). Then define OR loss, which is finally combined with SFT loss.
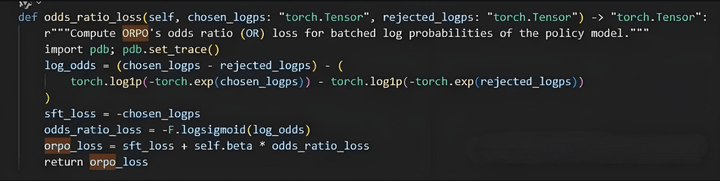
Essentially, ORPO and DPO are addressing the same problem: increasing the distance between positive and negative samples, allowing the model to better distinguish between them.
Here is a weighting coefficient; in experiments, it is usually set to 0.1, which means that the main effect still comes from SFT. In other words, a bit of contrast loss is introduced on top of SFT.
Difference between ORPO and DPO:
1. ORPO does not have a reference model, while DPO does.
2. ORPO's weighting is usually pair_loss * 0.1, which can be seen as adding a bit of contrast learning effect during SFT training. DPO is sft_loss * 0.1, which introduces a bit of SFT effect in contrast learning to prevent the model from deviating too much. If ORPO removes sft_loss, it becomes an aggressive RL method that removes the reference model, making it easier to drift.
Disadvantages of ORPO: Generally, the SFT stage requires tens of thousands to hundreds of thousands of datasets, while the RL stage requires thousands to tens of thousands of pair data. It is well known that pair data is more difficult to obtain than SFT data. ORPO is a combination of SFT and RL phases, requiring a large amount of pair data.
SimPO: Simplified DPO
SimPO: Simple Preference Optimization with a Reference-Free Reward

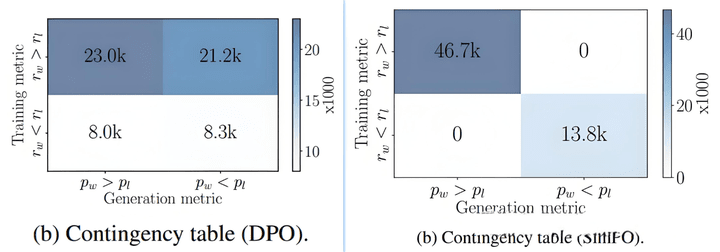
It can be seen that in the training results of DPO, half of them do not meet the requirements of the reasoning goal.
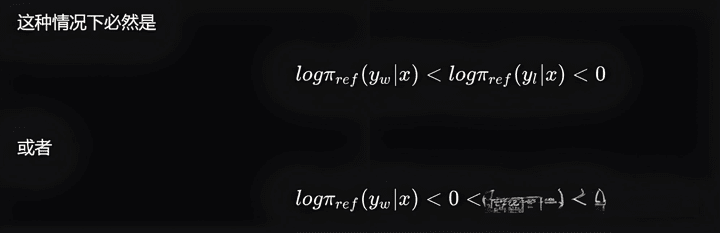
This means that the original SFT model finds it difficult to generate chosen data in pair data; in contrast, it is easier to generate rejected.
In actual projects, DPO training data usually looks like this; rejected refers to bad cases generated by the SFT model (with a higher probability of generation), while chosen refers to those generated by other better models (with a very low generation probability from the SFT model).
SimPO has optimized this. From the reward function, it can be seen that compared to DPO, SimPO lacks a reference model. It consumes less training memory and adds a length normalization term to address the issue of the RL model's output length increasing due to chosen usually being longer than rejected.

A simple reasoning process can be understood as

SimPO does not have KL divergence constraints and simply constrains model deviation by reducing learning rate.

SimPO vs DPO:
In summary, DPO optimizes (current model closer to chosen than ref model - current model further from rejected than ref model), the goal is too complex, and the optimization result may not be the best reasoning result.
SimPO optimizes (current model generates chosen - current model generates rejected), with a clear and straightforward goal.
Disadvantages: No reference model, no KL divergence added, prone to drifting... The actual effect is average.
Summary
1. DPO is a simplified version of PPO, aimed at optimizing max(chosen-rejected). For data not generated by oneself, it's easy for chosen and rejected to rise and fall simultaneously, leading to unstable effects (although it's much better than PPO).
2. KTO changes the optimization goal of DPO from max(margin) to max(chosen) or max(-rejected), ensuring RL effectiveness. In cases of average dataset quality, its performance is better than DPO. However, its method's upper limit of capability is lower than DPO.
3. The core of ORPO is still SFT loss, while increasing the demand for pair data.
4. Compared to DPO, SimPO removes the reference model, does not add KL divergence, and is prone to drifting.
Overall, in the current dialogue project, DPO is still used more often, commonly used to correct model response content for specific problems, while the effectiveness for other task types is uncertain and requires specific analysis for each task.
When it comes to improving dialogue quality, it’s still quite challenging since it’s impossible to accurately define what constitutes high dialogue quality. The core task is to prompt and extract 'high-quality' data. The impact of data quality on results is much greater than the impact of RL methods.
Reference Articles
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Little Winter Melon AIGC: Why do the probabilities of Chosen and Rejected decline simultaneously in DPO???
Limitations of DPO
ChenShawn: [Unreliable] A hypothesis regarding why the rewards for chosen and rejected decline together during DPO training.
Sonsii: DPO and its derivative algorithm XX-O
The DPO mathematical principle that everyone can understand
KTO: Model Alignment as Prospect Theoretic Optimization
LLM RLHF 2024 Paper (8) KTO
Large model alignment technology includes various types such as O: PPO, DPO, SimPO, KTO, Step-DPO, MCTS-DPO, SPO.
2024 Large Model Alignment Preference Optimization Technology PPO, DPO, SimPO, KTO, Step-DPO, MCTS-DPO, SPO.
ORPO: Monolithic Preference Optimization without Reference Model
Can't afford the big model's PPO, DPO preference optimization algorithms? Then I suggest you look at ORPO (more cost-effective!)
SimPO: Simple Preference Optimization with a Reference-Free Reward
Finally, let's summarize a set of cryptocurrency trading insights:
Point one: Understand how to cut losses and take profits.
We trade cryptocurrencies for trading, for speculation, not to hold forever! When you are making money, you think about making more, and when you are losing, you are reluctant to sell. This mindset is definitely inadvisable. When the trend of your position goes wrong, you need to decisively sell.
Point two: Don't always think about buying low and selling high.
Because the market will only have lower and higher points. Ordinary people cannot achieve this mechanism, so do not pursue so-called highs and lows. What we really need to do is buy and sell in the bottom and top regions.
Point three: Quantity and price must perfectly match.
For positions that rise without volume or reach new highs without volume, we must be cautious. It is likely a signal of a main force unable to offload stock, leading to rising exhaustion. Never chase; it’s better to miss than to make a mistake.
Point four: Be quick to react.
When information arises, we must immediately find out which sectors and companies benefit from it. If you can't keep up with the first tier, we should promptly act; the second tier will also yield significant gains.
Point five: Learn to rest.
As the saying goes, three months to see the bottom, three days to see the top. This means that the main rising wave of a known cryptocurrency price increase cycle only lasts for a brief period. Therefore, we must learn to seize this main wave. Typically, the rest of the time is for resting.
Point six: The greatest benefit of the market is a crash, as after a crash, many greater opportunities often arise. When others are greedy, learn to be fearful; when others are fearful, we must learn to be greedy. Therefore, when the market crashes, do not fear; this is the time to choose quality positions and build them promptly.
These six points may sound simple, but very few can truly execute them. Why? If you cannot overcome the weaknesses of human nature, you will never earn your first five million in life.
Finally, those who have been rained on always want to hold an umbrella for others. Having experienced days of isolation, they empathize with others' losses. They want to lend a helping hand, to compensate for the regret of wanting to be pulled up back then, as if they are traveling through time to hold an umbrella for their past selves who were caught in the rain.
This is also the original intention of my sharing, hoping to help many retail investors avoid some detours!
To help everyone avoid detours, I am sharing my ten-year experience in cryptocurrency trading, hoping that those destined to see it will take it seriously. Whether you are a novice or an expert, regardless of your wealth or level, it will be helpful to you. If you find my sharing useful, please forward it to those around you, so more people can benefit!
No matter how diligent a fisherman is, they won't go out to fish in a stormy season. Instead, they carefully protect their boat. This season will pass, and a sunny day will come! Follow me, and I will teach you to fish and also how to fish. The cryptocurrency world is always open; following the trend is the only way to lead a successful life. Keep this in mind!