
————————————————————
Native Rollups can be viewed as a return to sharding, but quite different from past attempts. Below, I will explain in seven parts:
1) Sharding
2) What are Native Rollups?
3) EXECUTE Precompile
4) What are the benefits of Native Rollups?
5) What is 're-execution'?
6) Moving towards 'real-time proofs'
7) Delayed 'state root'
8) Delayed execution
1) Sharding 🔻
Was a hot topic between 2017-2020, during which multiple teams, including Harmony, Zilliqa, and Elrond, implemented sharding in their respective blockchains.
The basic idea of sharding is to divide the network into multiple smaller, parallel-running chains (Shards) that can process transactions simultaneously. This is a simple method to scale distributed systems. In the Ethereum 2.0 era, sharding was also a serious topic of discussion within the community. However, Ethereum ultimately decided not to implement sharding directly in L1, mainly based on the following four key challenges:
1️⃣ Traditional sharding models require the protocol to mandate a specific number of shards from the top down. Each shard is a monolithic chain, following a predefined template, lacking programmability, essentially replicating multiple identical L1s.
2️⃣ At the time, zero-knowledge proof (ZK) technology was not mature, and the security of sharding mainly relied on optimistic proofs, which required systematic management of fraud proof logic, adding complexity.
3️⃣ Direct implementation of sharding at the L1 level will significantly increase protocol complexity, particularly in managing fast preconfirmation and slow final confirmation mechanisms, as well as coordination between shards with different security levels.
4️⃣ Promoting large-scale expansion at the L1 level will increase centralization risks. If sharding is directly implemented in the underlying protocol, any potential issues will affect the entire network, unlike the current L2 solutions where risks can be contained within a single Rollup.
2) What is Native Rollup? 🔻
We need to clarify that Rollup has three modules: data, ordering, and execution. Native Rollup runs its execution module directly in Ethereum's own execution environment. Simply put, they can be viewed as programmable execution shards on the first layer (L1).
To enable Rollup to utilize L1's execution capabilities sounds a bit convoluted. In simple terms, it means running another EVM within the Ethereum EVM. This way, L1 can be aware of the state changes in each block of the Native Rollup. To achieve this, a precompile is needed to help turn this idea into reality.
What is EXECUTE precompile?
The EXECUTE precompile establishes a mechanism that allows one EVM environment to check the execution results of another EVM environment while maintaining the same execution rules and state transition logic.
EXECUTE requires three inputs:
🔹pre_state: State root before execution (32 bytes)
🔹post_state: State root after execution (32 bytes)
🔹witness_trace: Execution trajectory, containing proofs of transactions and state access.
The precompile will make an assertion: it will check whether starting from the 'pre-state root', running through the execution trajectory can ultimately yield the 'post-state root'. If the state transition function is correct, it returns 'true'.
This trajectory needs to allow validators to access it (for example, through data blocks or calling data) so that they can run it again themselves and confirm that the state transition is correct. Note that this precompile does not take proofs as input, meaning the protocol does not strictly require a specific proof system; proofs are transmitted through P2P gossip channels, and each proof type can start a new topic.
How is gas calculated?
Ethereum resources are limited, and gas is used to quantify these resources. The EXECUTE precompile also has its own gas model to manage computational resources:
——Base fee: The precompile charges a fixed fee (EXECUTE_GAS_COST), plus the gas amount used for the execution trajectory multiplied by the gas price.
——Cumulative gas limit: A mechanism similar to EIP-1559 is used to measure and price the total gas consumption of all EXECUTE calls within an L1 block, specifically:
🔹EXECUTE_CUMULATIVE_GAS_LIMIT:
The maximum amount of gas that all EXECUTE calls can use in a single block.
🔹EXECUTE_CUMULATIVE_GAS_TARGET:
Target gas usage for reasonable pricing.
This can be seen as a 'limit-target' gas model, somewhat similar to the DA pricing method for data blocks (blobs).
3) What are the benefits of Native Rollups? 🔻
——Stronger security:
Current Rollup designs require a 'security committee' to update the chain because there may be vulnerabilities in the code. Native Rollups do not have to worry about this; they rely on Ethereum's 'social consensus' (collective decision-making) for management. Operators of native Rollups do not need to fix bugs themselves because the Ethereum community will handle it for you.
——Easier interaction with Layer 1:
Ordinary Rollups are very close to synchronizing operations with L1, but there is one condition: the blocks of L1 and L2 must be packaged simultaneously by the same 'builder'. Native Rollup does not require this condition; it can directly use a tool called 'EXECUTE' to check the state of another native Rollup without extra trust. If it only needs to 'read' data, for instance, if Rollup A wants to see the latest state of Rollup B, it can directly reference B's 'state root' and provide a proof to confirm the data is correct.
——Strong compatibility:
With the upgrade of the Ethereum mainnet's EVM, native Rollups can automatically inherit all improvements without having to adapt by themselves. This ensures that they can align with Ethereum's plans in the long term.
4) What is 're-execution'? 🔻
In native Rollups, 're-execution' is the first step of implementation. Simply put, it is where validators run through the transaction records themselves to confirm that the state changes are correct, rather than relying on some complex SNARK proof. As long as a reasonable 'EXECUTE_CUMULATIVE_GAS_LIMIT' (total gas limit for execution) is set, validators can handle this re-execution.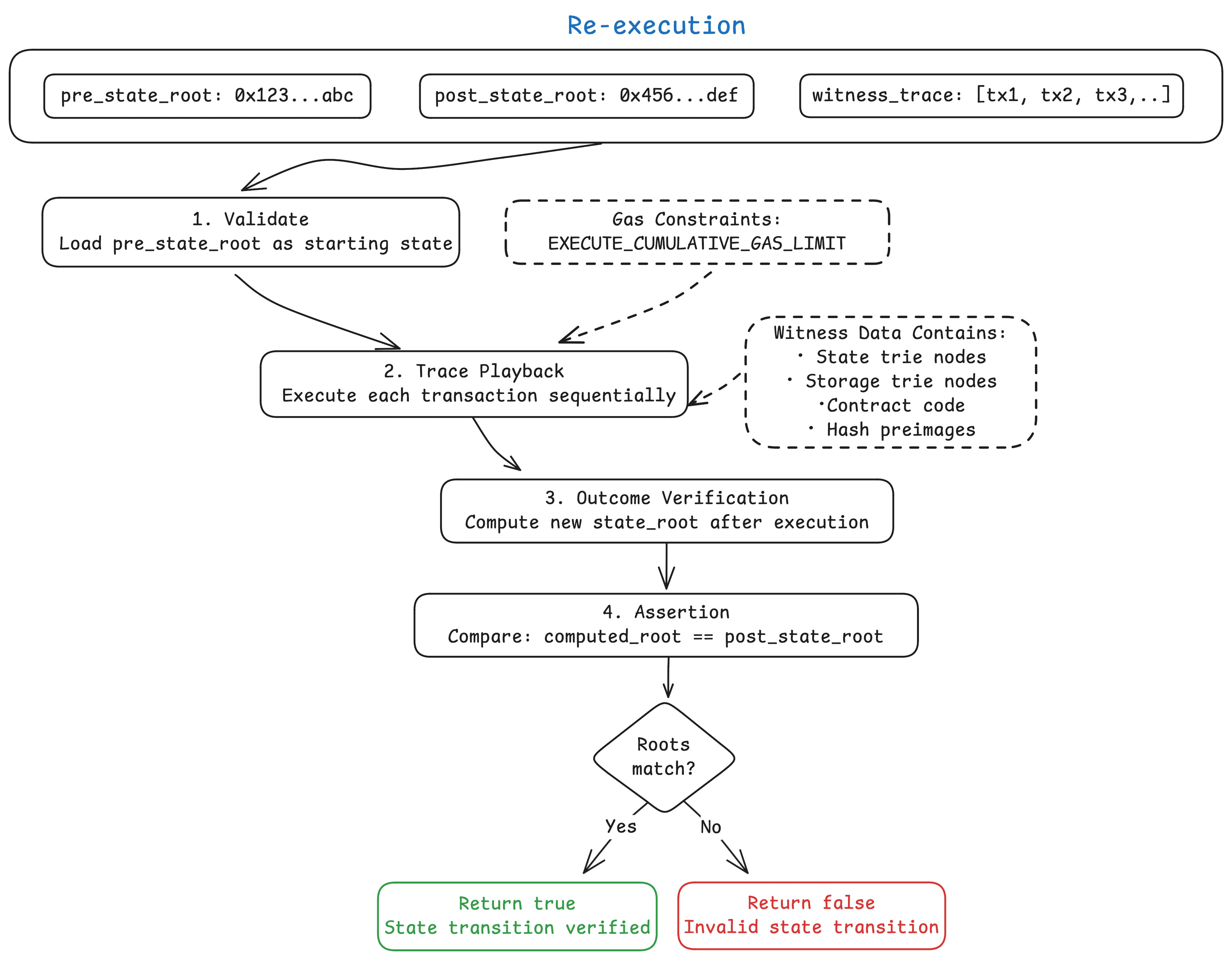
5) Moving towards 'real-time proofs' 🔻
With 're-execution', validators have to handle all transactions themselves, which will limit throughput (processing speed) due to the 'EXECUTE_CUMULATIVE_GAS_LIMIT' cap. If using 'real-time proofs', validators only need to check the proof without re-running the transactions themselves, significantly relaxing the limit.
The current trend is toward 'real-time proofs', so we need to secure more 'proof time' for native Rollups. To squeeze out more time, adjustments need to be made to Ethereum's current block processing structure.
The current structure is as follows:
After a block (Block N) proposes a transaction, validators must complete the following steps within 12 seconds (divided into three 4-second phases) before moving to the next block:
🔹Execute all transactions
🔹Calculate state changes
🔹Calculate the 'state root'
🔹Calculate receipts and logs
Only after all this is resolved can blocks be verified and confirmed. According to the current process, to synchronize with L1, proofs must be completed within 4 seconds. However, the current ZK (zero-knowledge proof) technology is not yet mature enough to prove an Ethereum block within 4 seconds, so some flexibility must be allowed for proofs.
6) Delayed 'state root' 🔻
Each block header contains a state root, representing the state after all transactions have been executed. This is a performance bottleneck because builders and validators must first calculate this 'state root' before proposing or validating the block. This calculation is intensive, taking up 40-50% of the builder's time, and in some client implementations, it can account for 70% of the time spent processing blocks.
Someone (Resnick and Noyes) proposed moving the 'state root' calculation away from the critical path to be done during client idle time. This means that block N no longer contains its own 'state root' after transactions but instead includes the 'state root' after transactions from the previous block (N-1). This will delay it by one block, but it can reduce chain latency and secure an entire time slot for proof.
7) Delayed execution 🔻
'Delayed execution' is more thorough than merely delaying the 'state root'. With this, block verification and confirmation do not need to wait for the re-execution of transactions.
First, perform 'static verification', only checking basic things like transaction format and signature correctness. Once consensus is reached (validation + confirmation), then execute the transaction and calculate the 'state root'.
This has several advantages:
➡️High consensus efficiency: Validate blocks earlier.
➡️More proof time: The entire confirmation period plus idle time can be used to generate proofs.
➡️Low latency: Shorten critical paths.
However, this upgrade will change the entire structure of the chain and will affect other upgrades (such as FOCIL). Details will not be discussed here; potential conflicts can be viewed here.
🔹Original compilation link: https://taiko.mirror.xyz/Mr5Fl0epl7ooCr5199yVrmGXWUV-IdYBHHtAwLXrp58