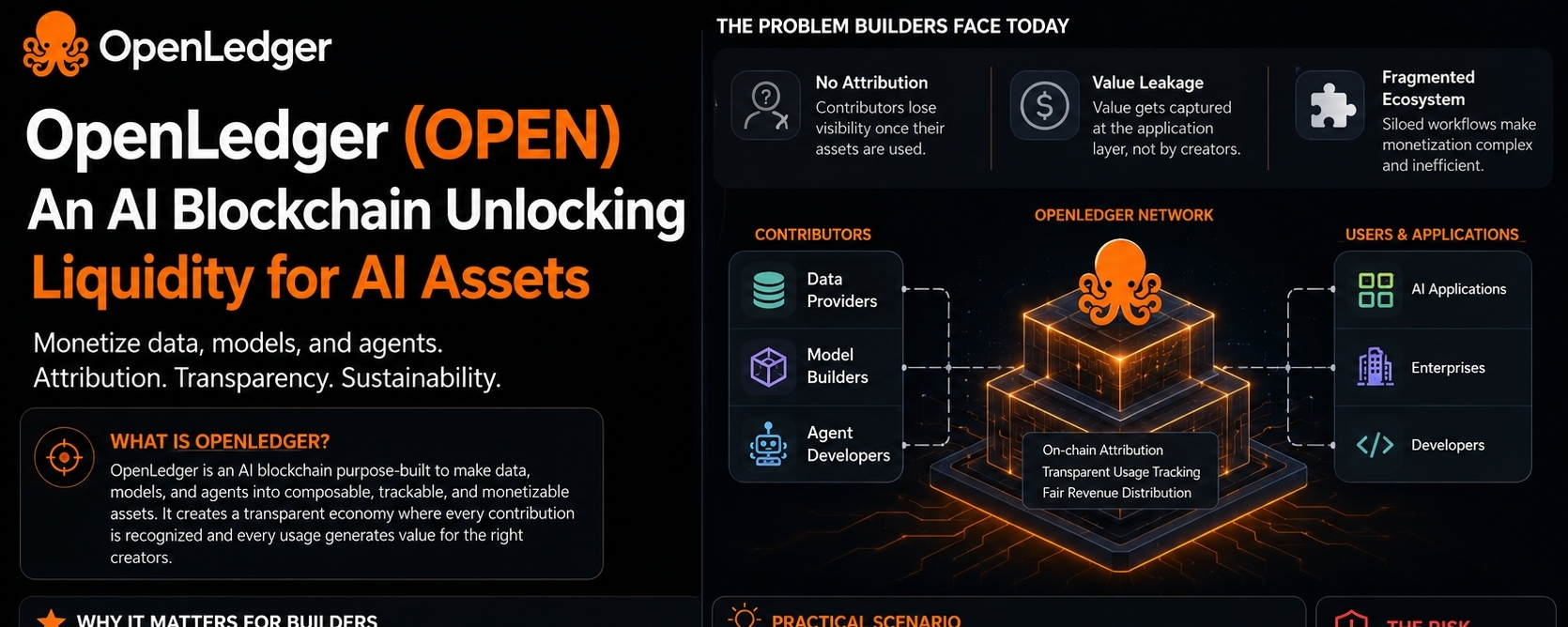
Les créateurs d'IA ont un problème qui n'attire pas souvent suffisamment d'attention.
La plupart des produits d'IA dépendent des données, des modèles, et de plus en plus, des agents spécialisés. Pourtant, les personnes qui créent ces ressources ont souvent du mal à capturer de la valeur. Un développeur peut passer des mois à collecter des données spécifiques à un domaine, à peaufiner un modèle ou à construire un workflow d'agent, pour finalement découvrir que la monétisation reste fragmentée et difficile.
C'est la tension du côté des créateurs qui me frappe quand je regarde OpenLedger.
Beaucoup de gens voient OpenLedger comme une simple blockchain axée sur l'IA. Cette interprétation rate la question plus intéressante : comment les créateurs sont-ils rémunérés pour les ressources qui rendent les systèmes d'IA utiles en premier lieu ?
Le véritable défi n'est pas de créer un autre modèle.
Le défi consiste à créer un système où les contributeurs de données, les builders de modèles et les développeurs d'agents peuvent participer au même flux de valeur sans s'appuyer sur des accords isolés, des plateformes centralisées ou des intégrations personnalisées chaque fois qu'ils souhaitent distribuer leur travail.
Aujourd'hui, le workflow est souvent inefficace.
Un builder crée un ensemble de données et essaie de trouver des acheteurs.
Un développeur de modèles s'entraîne sur des données provenant de multiples sources et a du mal à suivre qui a contribué quoi.
Un créateur d'agents construit une automatisation sur des modèles existants mais a des moyens limités de partager les revenus avec les contributeurs en amont.
Chaque couche crée de la valeur, mais l'attribution et la monétisation deviennent déconnectées. Au fur et à mesure que les stacks d'IA deviennent plus complexes, ce problème de coordination s'aggrave.
C'est là que le mécanisme d'OpenLedger devient intéressant.
Au lieu de traiter les actifs IA comme des composants isolés, OpenLedger tente de faire des données, des modèles et des agents une partie d'un cadre économique partagé. L'idée est que les contributeurs peuvent enregistrer, suivre et monétiser ces actifs à travers une infrastructure basée sur la blockchain conçue spécifiquement pour l'activité IA.
Le point important n'est pas la blockchain elle-même.
Le point important est de créer une couche de propriété et d'attribution qui se situe sous le développement de l'IA.
Si cette couche fonctionne comme prévu, les builders passent moins de temps à négocier des arrangements personnalisés et plus de temps à construire des ressources qui peuvent être découvertes, intégrées et rémunérées via un système commun.
Cela réduit une forme spécifique de friction.
Les builders n'ont plus besoin de penser uniquement à créer des applications IA finies.
Ils peuvent se concentrer sur la création de composants précieux.
Un ensemble de données de niche, un modèle spécialisé ou un agent très efficace peut devenir un actif autonome plutôt qu'un élément caché d'infrastructure enfoui dans un produit plus large.
Cela compte parce que le développement de l'IA devient de plus en plus modulaire.
Très peu d'équipes construisent tout à partir de zéro maintenant.
La plupart des produits combinent des données externes, des modèles tiers, des frameworks d'agents et une logique propriétaire. À mesure que cette tendance se poursuit, l'attribution devient un problème plus important que beaucoup de builders ne le réalisent.
Le point de pression pour l'adoption est simple.
Les builders doivent réellement choisir d'enregistrer et de distribuer leurs actifs via le réseau.
La technologie seule ne résout pas les problèmes d'attribution.
Le réseau devient utile seulement lorsque suffisamment de fournisseurs de données, de créateurs de modèles et de développeurs d'agents participent au même système. Sans participation significative, les builders font toujours face aux mêmes défis de découverte et de monétisation qui existent aujourd'hui.
Considérons un exemple pratique.
Une petite équipe construit un agent IA axé sur l'analyse de documents juridiques.
L'agent dépend d'ensembles de données juridiques spécialisés et de modèles affûtés créés par d'autres contributeurs.
Dans une configuration traditionnelle, le suivi de la valeur à travers ces couches peut devenir compliqué. Les accords de licence, les rapports d'utilisation et l'allocation des revenus nécessitent souvent des processus séparés.
L'approche d'OpenLedger tente de placer ces composants dans un cadre où les contributions peuvent être identifiées et liées à l'activité économique. Au lieu que chaque équipe réinvente les systèmes d'attribution, elles peuvent potentiellement s'appuyer sur une infrastructure partagée.
Pour les builders, c'est l'idée centrale à laquelle il vaut la peine de prêter attention.
Pas de transactions plus rapides.
Pas de récits de tokens.
La possibilité de créer un marché plus structuré autour des blocs de construction de l'IA.
Il y a encore un risque.
Même si l'infrastructure est techniquement solide, le comportement des builders est difficile à changer. Les développeurs ont déjà des flux de travail établis, des fournisseurs de cloud existants et des canaux de distribution familiers. Si la participation reste limitée, la couche d'attribution devient moins précieuse car les actifs que les builders souhaitent ne sont pas disponibles dans le réseau.
C'est le défi auquel OpenLedger fait finalement face.
Ma thèse principale est simple : OpenLedger est mieux compris non pas comme une autre blockchain IA, mais comme une tentative de résoudre le problème de monétisation et d'attribution entourant les composants de l'IA. Si le développement de l'IA continue de se diriger vers des données, des modèles et des agents modulaires, alors les projets qui facilitent la propriété et la distribution de valeur pourraient devenir de plus en plus pertinents pour les builders. Le succès de cette vision, cependant, dépend moins de la technologie et plus de savoir si les builders décident que la couche de coordination vaut la peine d'être utilisée.
