Pour être honnête, l'intelligence générale est utile, mais la connaissance locale est là où se cache une grande partie de la vraie valeur.
Ça sonne un peu banal, mais ça compte.
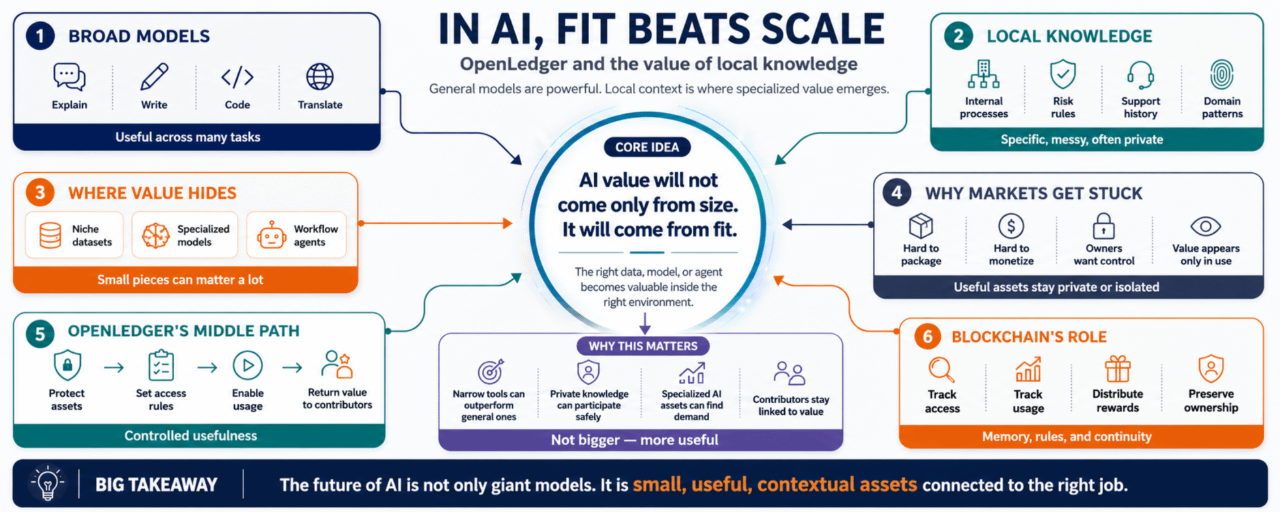
Un grand modèle peut répondre à beaucoup de choses. Il peut expliquer, résumer, écrire, traduire, coder et raisonner sur des sujets variés. C'est impressionnant. Mais quand le travail devient spécifique, le modèle a souvent besoin de quelque chose d'autre.
Il a besoin de contexte.
Pas n'importe quel contexte.
Le bon contexte.
Le processus interne d'une entreprise.
Le flux de patients d'un hôpital.
Les règles de risque d'un trader.
Les tickets passés d'une équipe de support.
Les petits retards d'un réseau logistique.
Les modèles de documents d'une équipe juridique.
Les habitudes de code d'une équipe de développeurs.
Ce ne sont pas toujours des choses que l'internet ouvert peut bien enseigner.
Ils sont locaux.
Spécifiques.
Désordonnés.
Souvent privés.
Et c'est là que l'IA commence à devenir plus intéressante.
Parce que l'avenir ne sera peut-être pas seulement une question de qui a le plus grand modèle. Cela pourrait également être une question de qui peut connecter des modèles utiles aux connaissances locales les plus pertinentes sans en perdre le contrôle.
@OpenLedger s'inscrit dans cette pensée.
Pas comme une promesse bruyante sur l'IA et la blockchain. Plus comme un système essayant de donner aux actifs IA locaux un moyen d'exister dans un marché plus large.
Les données, les modèles et les agents ne sont pas tous les mêmes. Mais ils ont une chose en commun : ils deviennent plus précieux lorsqu'ils sont connectés au bon cas d'utilisation.
Un ensemble de données d'une entreprise peut sembler ennuyeux de l'extérieur.
Un petit modèle entraîné sur une tâche étroite peut ne pas sembler important.
Un agent conçu pour un flux de travail peut ne pas sembler être un gros produit.$PORTAL
Mais dans le bon environnement, ces choses peuvent avoir beaucoup d'importance.
On peut généralement le dire après avoir vu l'IA en action. La réponse générique est souvent seulement le début. La réponse utile vient après que le système a compris le contexte. Les termes que les gens utilisent. Les raccourcis qu'ils prennent. Les risques qu'ils évitent. Les motifs qui se répètent discrètement au fil du temps.
Ce genre de connaissance est difficile à emballer.
Et encore plus difficile à monétiser.
Si une entreprise a des données locales utiles, elle peut ne pas vouloir les vendre. Si un développeur a un modèle affiné pour une industrie, il peut ne pas vouloir qu'il soit absorbé par une plateforme plus grande. Si un agent fonctionne bien dans un flux de travail spécifique, sa valeur peut ne pas être évidente jusqu'à ce que quelqu'un l'utilise réellement.
Donc, le marché se retrouve bloqué.
La connaissance utile reste privée.
Les modèles utiles restent isolés.
Les agents utiles restent petits.
#OpenLedger semble essayer de créer un chemin intermédiaire pour cela.
Un moyen pour les actifs IA d'être utilisables sans être complètement détachés de leur source. Un moyen pour la connaissance locale de voyager sous des règles. Un moyen pour la valeur de revenir si cette connaissance aide quelqu'un à construire quelque chose d'utile.
C'est une idée subtile.
Ce n'est pas la même chose que de rendre tout ouvert. Certaines connaissances ne devraient pas être ouvertes. Certaines données ont besoin de limites. Certains agents ne devraient opérer que dans certaines conditions.
Mais la connaissance fermée a aussi un problème. Si elle ne se connecte jamais à quoi que ce soit, sa valeur reste piégée.
Donc, peut-être que la vraie question n'est pas ouverte contre fermée.
C'est l'utilité contrôlée.
Un actif peut-il rester protégé et participer quand même ?
Un modèle peut-il être spécialisé et trouver une demande ?
Un agent peut-il être étroit et gagner de l'argent grâce à un vrai travail ?
La connaissance locale peut-elle devenir partie intégrante de l'IA sans être complètement avalée ?
C'est là que la blockchain peut avoir un rôle, si elle est utilisée avec précaution.
Un registre peut aider à suivre l'accès, l'utilisation et les récompenses. Il peut donner aux actifs IA une certaine continuité. Il peut rendre la relation entre contributeur et utilisateur moins dépendante de la confiance privée. Pas parfaitement, bien sûr. Mais peut-être assez pour rendre possibles de nouveaux types de partage.$PLAY
Et cela compte parce que l'IA devient de plus en plus contextuelle.
Le modèle large n'est qu'une couche. Autour de lui, il y aura des ensembles de données plus petits, des mémoires privées, des modèles spécialisés, des flux de travail, et des agents qui comprennent un domaine mieux qu'un système général ne peut le faire.
Cela ne les rend pas plus grands.
Cela les rend utiles.
Il y a une différence.
Un petit agent qui gère bien un processus commercial peut créer plus de valeur réelle qu'un outil général qui fait beaucoup de choses à moitié. Un ensemble de données d'un domaine de niche peut avoir plus d'importance qu'un énorme ensemble de données publiques lorsque la tâche est étroite. Un modèle entraîné pour un flux de travail peut devenir précieux parce qu'il réduit les erreurs à cet endroit précis.#StrategyHintsNewBTCBuy
Après un certain temps, il devient évident que la valeur de l'IA ne viendra pas seulement de l'échelle.
Elle viendra de l'adéquation.
L'accent d'OpenLedger sur les données, les modèles et les agents semble s'articuler autour de ce changement. Il donne un cadre aux pièces qui rendent l'IA adaptée à un environnement spécifique. Ces pièces ont besoin de propriété, de règles d'accès et d'un chemin vers la monétisation.
Sans cela, la connaissance locale reste enfermée, ou elle est absorbée par des plateformes plus grandes sans beaucoup de visibilité.
Aucun des résultats ne semble complet.
Le chemin le plus équilibré est plus difficile. Cela signifie laisser les actifs IA utiles se déplacer, mais avec mémoire. Avec des règles. Avec un moyen pour les contributeurs de rester connectés à la valeur qu'ils ont aidé à créer.
OpenLedger essaie de travailler quelque part dans cet espace.
Pas autour de la version la plus bruyante de l'IA.
Autour de la version plus silencieuse.
Celle où un petit morceau de connaissance, au bon endroit, peut avoir plus d'importance qu'un très grand modèle essayant de tout savoir.
@OpenLedger #OpenLedger $OPEN
Article
Plus l'IA grandit, plus une chose devient claire.
Avertissement : ce contenu inclut des opinions de tiers. Il ne constitue pas un conseil. Binance Ai peut être utilisée, sans garantie de résultat. Consultez les CG.