
Avant que les organisations de droits de performance n'existent, les stations de radio diffusaient de la musique en continu. Les chansons circulaient dans les ondes, les audiences grandissaient, les revenus publicitaires suivaient. La chaîne de valeur était évidente pour tous ceux qui regardaient. Ce qui était moins évident, c'était comment cette valeur revenait aux personnes qui avaient créé la musique en premier lieu.
Ça a surtout pas marché.
Pas parce que l’industrie était particulièrement corrompue. Mais parce que le mécanisme pour suivre les contributions à grande échelle n’existait tout simplement pas encore. Sans un système qui pourrait dire de manière crédible que cette chanson a été jouée ce nombre de fois et qu’en conséquence ce montant est dû à cet artiste, l’économie revenait à qui contrôlait la distribution. Ça a été vrai jusqu’à ce que l’infrastructure rattrape le problème.
L'IA est là, à cet instant précis.
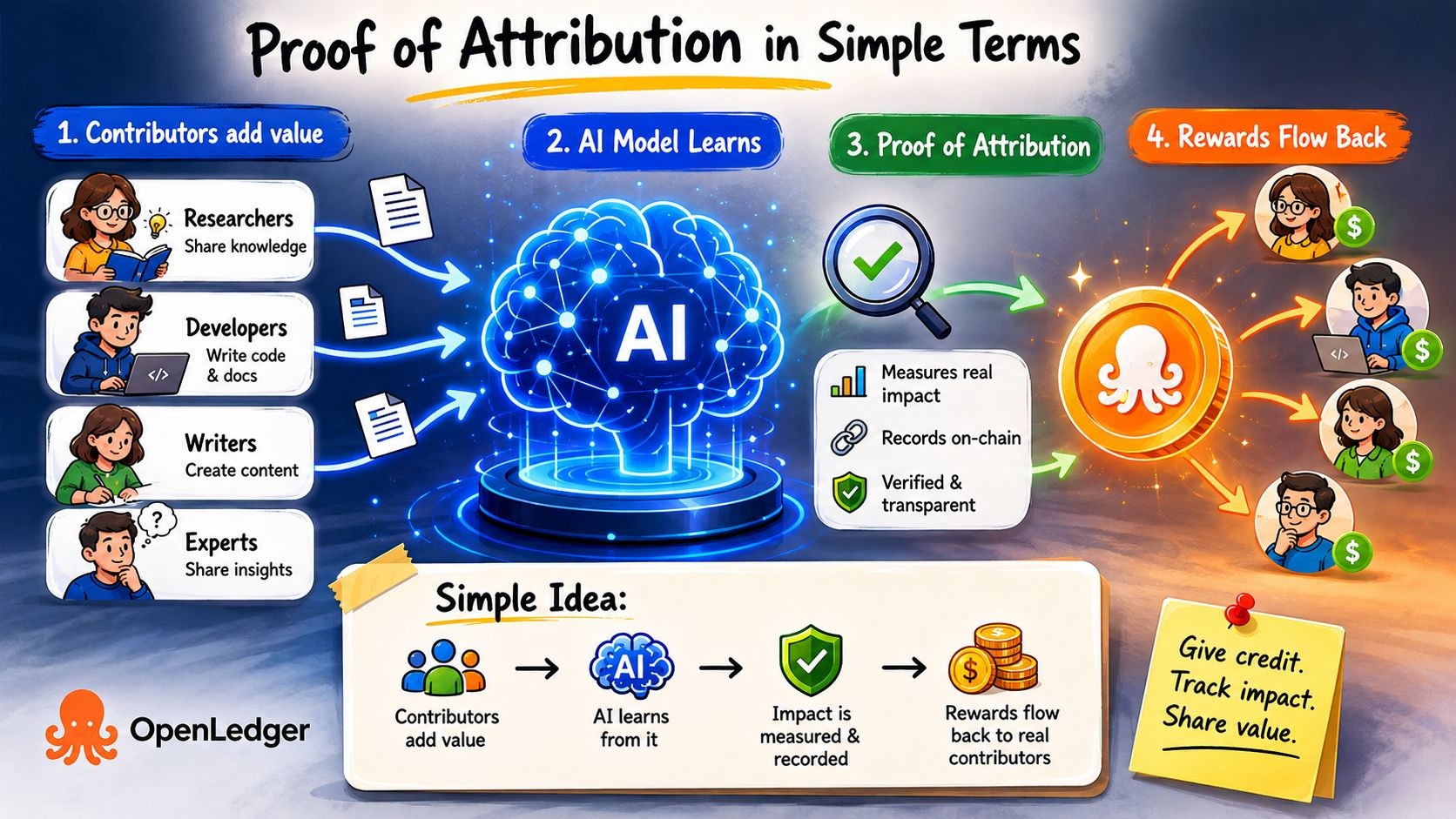
Chaque grand modèle de langage en production aujourd'hui a été façonné par la contribution humaine. Pas dans un sens abstrait. Spécifiquement. Le travail publié d'un chercheur médical. La documentation open-source d'un programmeur. L'explication d'un expert de domaine sur un forum écrite à 2h du matin parce qu'il connaissait la réponse et voulait aider. Tout cela est entré dans des pipelines d'entraînement, a façonné le comportement du modèle, et est devenu intégré dans des sorties qui génèrent maintenant de la valeur commerciale à grande échelle.
Le modèle a appris de ces contributions.
La question est de savoir s'il a jamais été conçu pour se souvenir de cela.
Dans presque tous les cas, la réponse est non. Pas parce que les développeurs de modèles sont particulièrement négligents. Mais parce que l'infrastructure pour suivre les contributions au niveau des entrées individuelles, à travers des milliards de points de données, via des processus d'entraînement complexes qui floutent et combinent les influences de manière non linéaire, n'existait pas sous une forme économiquement utile.
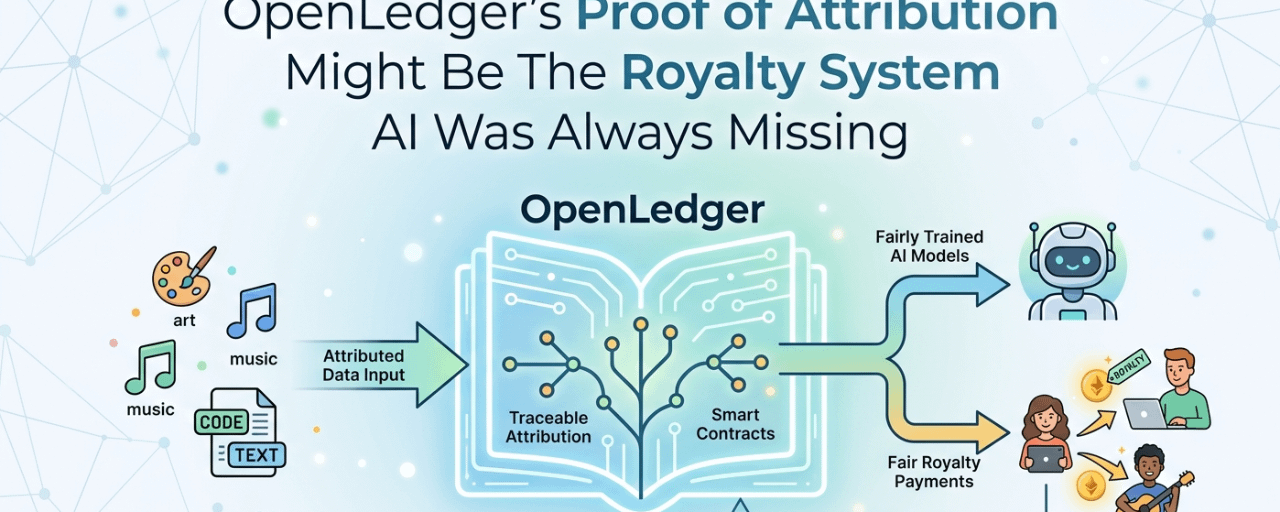
C'est le problème spécifique @OpenLedger qui construit la preuve d'attribution autour.
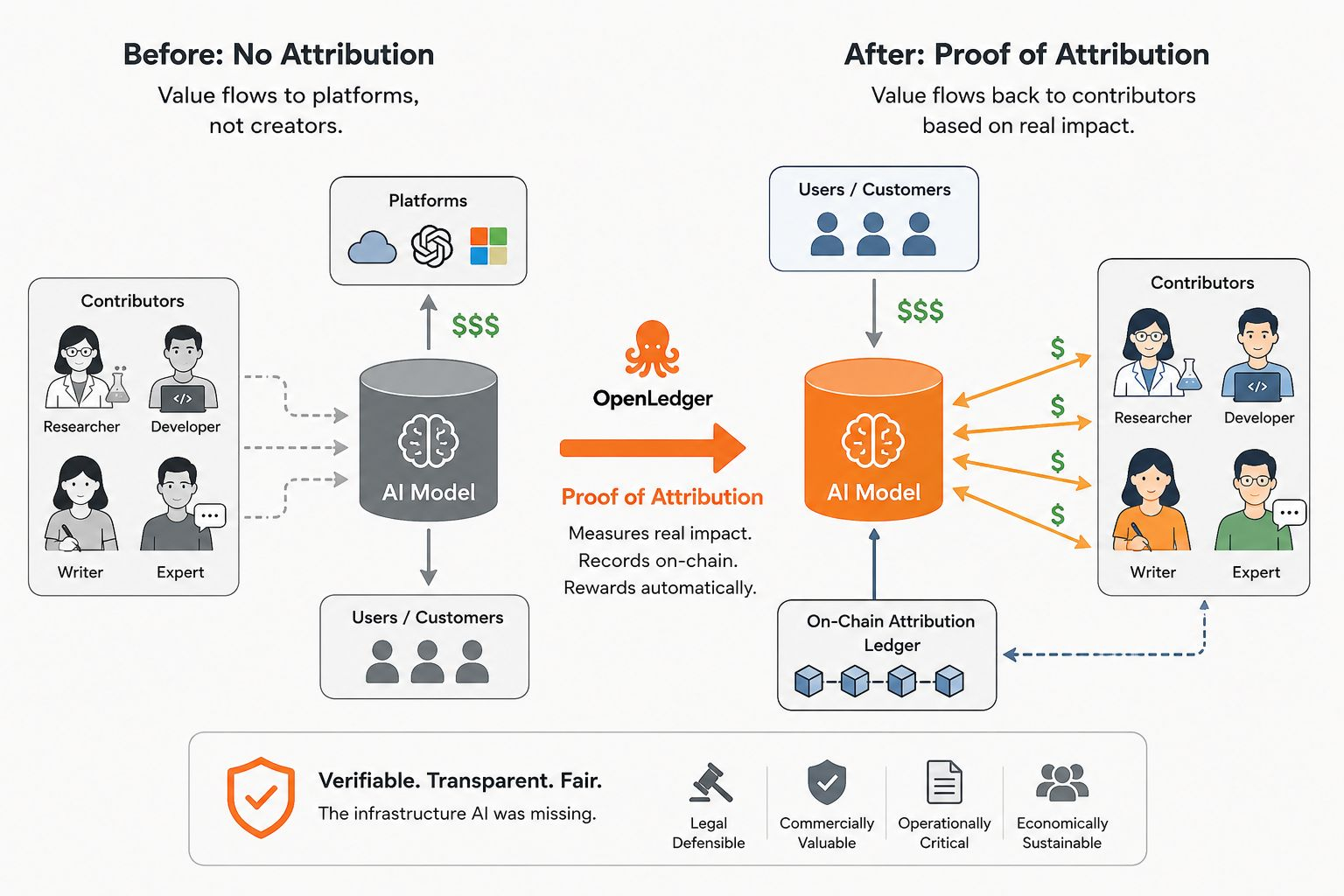
Le mécanisme fonctionne en mesurant combien chaque contribution de données a réellement influencé le comportement du modèle. Pas symboliquement. Mesurablement. Si la suppression d'un ensemble de données spécifique modifie significativement la performance du modèle sur des tâches réelles, cet ensemble de données avait une réelle valeur. La contribution est enregistrée sur la chaîne, liée au contributeur, et devient partie d'un système de distribution de récompenses automatisé qui s'active lorsque le modèle génère une sortie économique.
Cela semble technique jusqu'à ce que vous le compariez à ce qui l'a précédé.
Avant que l'infrastructure des droits de performance n'existe dans la musique, la valeur était contrôlée par ceux qui contrôlaient l'accès. Une fois qu'elle existait, la valeur pouvait circuler vers ceux qui créaient le contenu — pas parfaitement, pas sans disputes, mais structurellement. L'infrastructure a changé ce qui était économiquement possible.
La preuve d'attribution tente le même changement architectural pour l'IA.
La partie intéressante est ce que cela change au-delà des récompenses individuelles des contributeurs. Quand la contribution devient traçable et économiquement attachée aux sorties, tout le comportement du système change. Les contributeurs ont des raisons de soumettre des données de meilleure qualité parce que la qualité affecte combien leur contribution influence le modèle et donc combien ils gagnent. Les développeurs ont des raisons de maintenir une attribution précise parce que le règlement économique en dépend. Les entreprises utilisant des modèles construits sur des données vérifiées et attribuées ont quelque chose qu'elles n'ont actuellement pas : une réponse défendable à la question de ce qui a alimenté l'intelligence qu'elles déploient.
Cette dernière partie compte plus qu'elle ne reçoit actuellement de crédit.
La pression légale autour des données d'entraînement de l'IA n'est plus théorique. Les tribunaux dans plusieurs juridictions décident activement des obligations qui existent autour de la provenance des données. Un système d'IA capable de démontrer des données d'entraînement propres, vérifiables et attribuées est un actif structurellement différent de celui qui ne le peut pas. Pas seulement éthiquement. Commercialement. Contractuellement. Opérationnellement.
La preuve d'attribution ne résout pas un problème philosophique sur l'équité.
Elle construit la traçabilité papier dont les systèmes d'IA auront de toute façon besoin.
La question plus difficile est de savoir si l'infrastructure peut tenir à grande échelle. L'attribution dans l'IA est vraiment compliquée. Les contributions se chevauchent. Les poids du modèle mélangent les influences de manière à résister à une séparation claire. Attribuer des pourcentages économiques exacts aux entrées individuelles nécessite des décisions qui sont en partie arbitraires. Le jeu est inévitable une fois que les récompenses économiques deviennent visibles — des contributeurs de mauvaise qualité inondent les systèmes pour poursuivre des paiements tandis que la valeur réelle se dilue.
Tout cela ne rend pas la direction erronée. Cela la rend difficile.
Les redevances musicales sont encore constamment disputées. L'attribution dans les industries créatives n'a jamais été parfaitement claire. Mais l'existence d'une infrastructure d'attribution imparfaite est toujours économiquement préférable à l'absence d'infrastructure d'attribution. Les marchés ne nécessitent pas de certitude philosophique. Ils nécessitent des systèmes contre lesquels les gens sont prêts à se régler.
Cela peut être le cadrage le plus honnête pour ce que $OPEN évalue réellement.
Pas un problème résolu. Une couche d'infrastructure qui rend le problème non résolu économiquement abordable pour la première fois. Et dans un monde où les sorties de l'IA sont de plus en plus impliquées dans des décisions qui ont de vraies conséquences, la distance entre "nous ne pouvons pas tracer cela" et "nous pouvons tracer cela de manière crédible" n'est pas un petit écart.
C'est la différence entre un système sur lequel la prochaine décennie peut s'appuyer et un que celle-ci devra finalement reconstruire de zéro.