

DeepSeek launched two new models on 12/2, namely DeepSeek-V3.2 and DeepSeek-V3.2-Speciale, which focuses on mathematical reasoning. The official statement indicates that these two models continue the initial experimental direction, aiming for a comprehensive upgrade in reasoning ability, tool usage, and long-term thinking capacity. DeepSeek also emphasizes that the official version V3.2 has shown performance in various reasoning tests that is comparable to GPT-5 and Gemini-3 Pro, and the Speciale version has achieved international gold medal standards in mathematics and information competitions.
The experimental version leads the way, and the official version V3.2 takes over.
DeepSeek positioned V3.2-Exp as an experimental platform for the next generation of AI when it was launched in September. The officially released version DeepSeek-V3.2 is no longer labeled with 'Exp', symbolizing more mature features.
The official explanation states that the new version V3.2 performs similarly to GPT-5 and Gemini-3 Pro in multiple reasoning tests, and it particularly emphasizes that this is their first model that tightly integrates 'thinking modes' with 'tool applications', supporting both thinking and non-thinking modes simultaneously. The following image illustrates:
DeepSeek-V3.2 has proven its tool capabilities through benchmark testing, now standing alongside top models like GPT-5 and Gemini-3 Pro.

The reasoning ability has been upgraded again, with tool integration becoming the biggest highlight.
DeepSeek states that the major highlight of V3.2 is its ability to combine the reasoning process with tool usage. In other words, while the model is contemplating something, it can also call upon external tools such as search engines, calculators, and code execution environments, making the entire task processing more complete, more autonomous, and closer to the way humans solve problems.
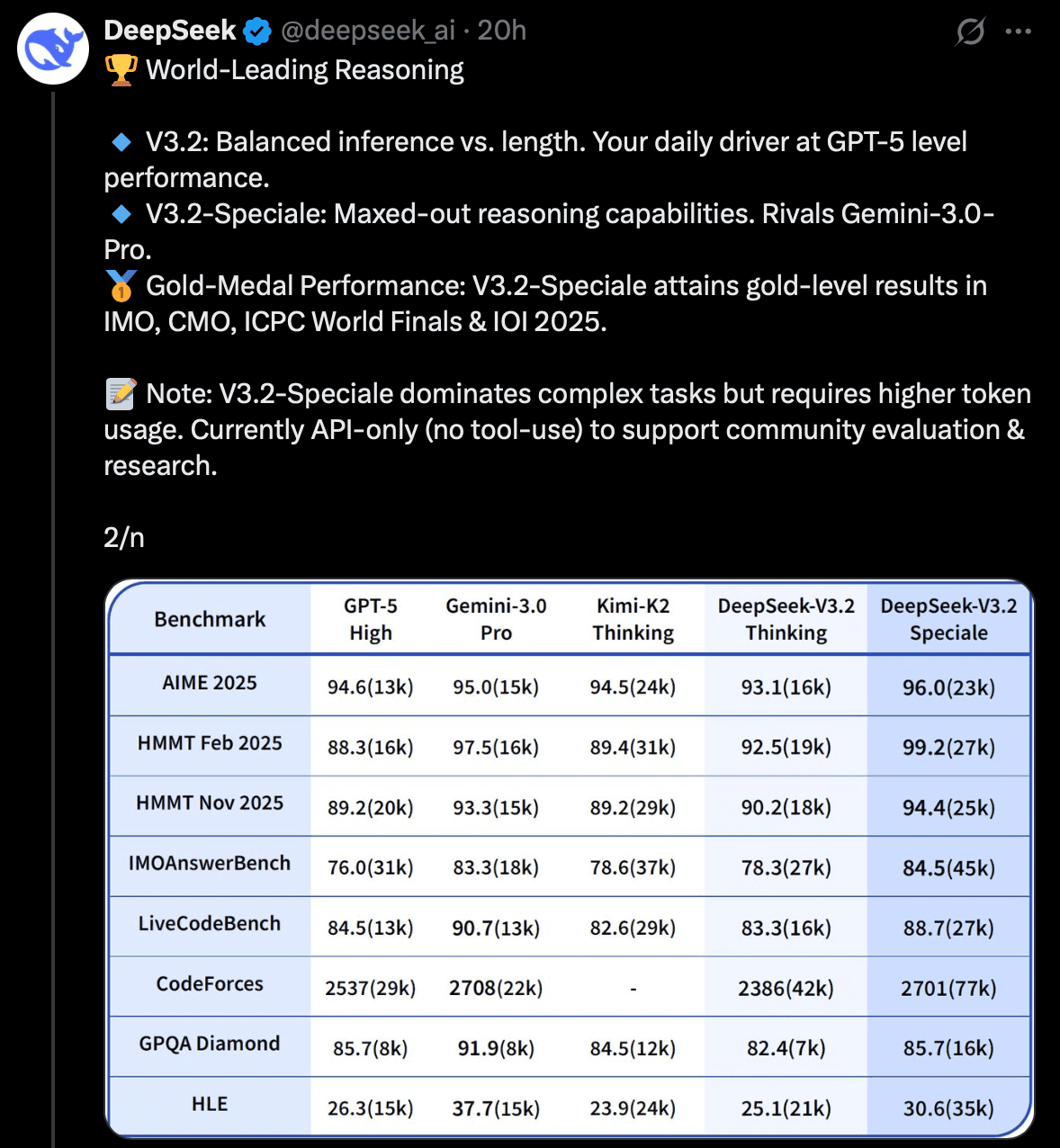
Speciale focuses on long reasoning, achieving gold medal level in mathematics.
In addition to the standard version V3.2, DeepSeek has also launched another version, DeepSeek-V3.2-Speciale. This version is specifically designed for high difficulty mathematical reasoning and long-duration thinking.
The official positioning aims to explore the limits of open-source model reasoning capabilities and even see what boundaries the model itself can reach. In terms of results, Speciale has achieved gold medal level in international mathematics Olympiads (IMO), international informatics Olympiads (IOI), and other competitive tests, with reasoning performance comparable to Google's latest Gemini-3 Pro. The following image illustrates:
The reasoning capability of DeepSeek-V3.2-Speciale has reached gold medal standards in international mathematics and information competitions, outperforming or matching GPT-5, Gemini-3 Pro, and Kimi-K2 in multiple reasoning and programming competition benchmark tests.
New training methods revealed, further enhancing AI agent capabilities.
Beyond the model, DeepSeek has also publicly announced a new research achievement, which is that they have established new methods to train AI agents. These agents can interact with external environments, analyze data, and make judgments without continuous human instructions.
DeepSeek emphasizes that this is the foundational technology they designed to make AI more efficient and responsive.
Continuing the momentum from January, the R&D pace continues to accelerate.
DeepSeek drew global attention in January this year due to a groundbreaking model. The V3.2 series is their latest achievement in continuing research momentum after that success. Just before launching V3.2, DeepSeek released DeepSeekMath-V2 last week, an open-source model focused on mathematical theorem proving, showing that they are continuously strengthening in reasoning and mathematics.
The technical report has been released, stating that the reasoning power of V3.2 is close to that of GPT-5 and Kimi.
DeepSeek has also simultaneously released a technical report (DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models), indicating that V3.2 performs similarly to GPT-5 and Kimi-k2-thinking in multiple reasoning benchmark tests.
This report also emphasizes that the competitiveness of local Chinese open-source models in the field of reasoning remains on par with international top models.
This article about DeepSeek's new V3.2 and Speciale, with reasoning and performance closely approaching GPT-5 and Gemini 3, first appeared in Chain News ABMedia.