
Original title: (Data as Assets: DataFi is Opening a New Blue Ocean)
Original author: anci_hu49074, core contributor of Biteye.
"We are in an era where the world is competing to build the best foundational models. While computing power and model architecture are important, the real moat is the training data."
——Sandeep Chinchali, Chief AI Officer of Story.
Starting from Scale AI, let's talk about the potential of the AI Data track.
If there is one piece of gossip in the AI circle this month, it is about Meta showcasing its cash abilities, with Zuckerberg recruiting talents everywhere to build a luxury Meta AI team mainly composed of Chinese research talents. The leader is Alexander Wang, who is only 28 years old and created Scale AI. He single-handedly established Scale AI, which is currently valued at 29 billion USD, serving not only the US military but also covering multiple competing AI giants like OpenAI, Anthropic, and Meta, all relying on Scale AI for data services, and the core business of Scale AI is to provide a large amount of accurate labeled data.
Why can Scale AI stand out among a crowd of unicorns?
The reason lies in its early recognition of the importance of data in the AI industry.
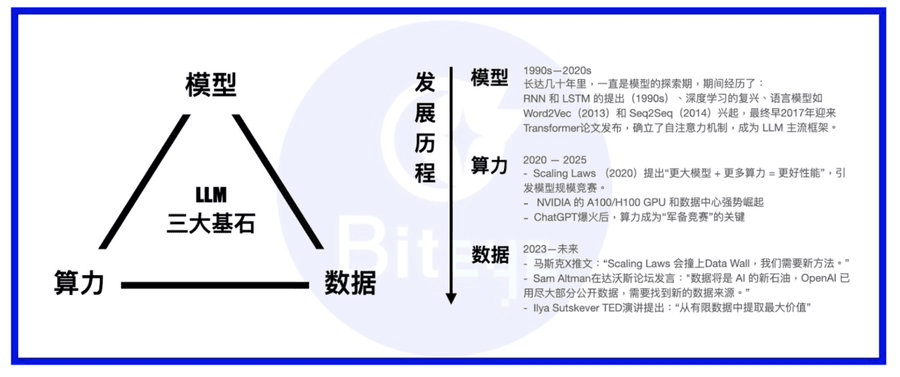
Computing power, models, and data are the three pillars of AI models. If we compare a large model to a person, then the model is the body, computing power is food, and data is knowledge/information.
In the years since LLM has emerged and developed, the industry's focus has shifted from models to computing power. Nowadays, most models have established transformers as their framework, occasionally innovating with MoE or MoRe; major players either build Super Clusters to complete the computing power wall or sign long-term agreements with powerful cloud services like AWS; once the basic needs for computing power are met, the importance of data gradually comes to the forefront.
Unlike traditional To B big data companies like Palantir, which have a prominent reputation in the secondary market, Scale AI, as its name suggests, is dedicated to building a solid data foundation for AI models. Its business goes beyond mining existing data—it is also looking towards long-term data generation businesses and is attempting to form AI trainer teams composed of human experts from various fields to provide higher quality training data for AI models.
If you are skeptical about this business, let's first look at how the model is trained.
Model training is divided into two parts—pre-training and fine-tuning.
The pre-training part is somewhat like the process of a human baby gradually learning to speak. What we usually need is to feed the AI model a large amount of text, code, and other information obtained from web crawlers. The model learns these contents through self-learning and learns to communicate in human language (academically called natural language), gaining basic communication skills.
The fine-tuning part is similar to going to school, which usually has clear right and wrong answers and directions. Schools will cultivate students into different talents based on their respective positions. Similarly, we will train the model using some pre-processed, targeted datasets to equip the model with the abilities we expect.

At this point, the clever you may have already understood that the data we need can be divided into two parts.
· Some data does not need extensive processing; having enough is sufficient, usually sourced from large UGC platforms like Reddit, Twitter, GitHub, etc., crawler data, public literature databases, private enterprise databases, and so on.
· The other part is like professional textbooks, requiring meticulous design and selection to ensure that they can cultivate specific excellent qualities in models, which requires necessary data cleaning, filtering, labeling, and human feedback.
These two types of datasets constitute the main body of the AI Data track. Do not underestimate these seemingly low-tech datasets; the mainstream view is that as the advantages of computing power in Scaling laws gradually fade, data will become the most important pillar for different large model vendors to maintain their competitive edge.
As the capabilities of models continue to improve, various more refined and specialized training data will become key influencing variables for model capabilities. If we further compare model training to the development of martial arts masters, then high-quality datasets are the finest martial arts manuals (to complete this metaphor, we could also say that computing power is the elixir, and the model itself is the innate talent).
Longitudinally, AI Data is also a long-term track with snowball capabilities. With the accumulation of early work, data assets will also have compound capabilities, becoming more valuable over time.
Web3 DataFi: The Chosen AI Data Fertile Ground.
Compared to the hundreds of thousands of remote human labeling teams established by Scale AI in the Philippines, Venezuela, and other areas, Web3 has a natural advantage in the AI data field, and the new term DataFi has emerged.
In an ideal scenario, the advantages of Web3 DataFi are as follows:
1. Smart contracts guarantee data sovereignty, security, and privacy.
At the stage where existing public data is about to be fully exploited, how to further mine undisclosed data, even private data, is an important direction for obtaining and expanding data sources. This faces an important trust choice issue—do you choose a centralized big company's contract buyout system, selling the data you have; or do you choose the blockchain method, retaining the data IP in your hands while also understanding clearly through smart contracts: who, when, and for what your data is being used.
At the same time, for sensitive information, there are ways like zk and TEE to ensure that your private data is only handled by machines that keep secrets and will not be leaked.
2. Natural geographical arbitrage advantage: a free distributed architecture that attracts the most suitable workforce.
Maybe it's time to challenge traditional labor production relationships. Instead of searching for low-cost labor globally like Scale AI, why not leverage the distributed nature of blockchain and use publicly transparent incentive measures secured by smart contracts to allow dispersed labor around the world to participate in data contributions.
For labor-intensive tasks like data labeling and model evaluation, using the Web3 DataFi method is beneficial for participant diversity compared to the centralized approach of establishing data factories, which has long-term implications for avoiding data bias.
3. Clear incentive and settlement advantages of blockchain.
How to avoid tragedies like the "Jiangnan Leather Factory"? Naturally, by using a transparent incentive system with smart contracts to replace the darker sides of human nature.
In the inevitable backdrop of de-globalization, how can we continue to achieve low-cost geographical arbitrage? Setting up companies all over the world is evidently becoming more difficult, so why not bypass the barriers of the old world and embrace on-chain settlement instead?
4. Conducive to building a more efficient and open "one-stop" data market.
"Middlemen profit from the difference" is a perpetual pain for both supply and demand sides. Instead of letting a centralized data company act as a middleman, it's better to create a platform on-chain, allowing the supply and demand sides of data to connect more transparently and efficiently through a publicly accessible market, similar to Taobao.
With the growth of the on-chain AI ecosystem, the demand for on-chain data will become more vigorous, segmented, and diverse. Only a decentralized market can efficiently absorb this demand and turn it into ecological prosperity.
For retail investors, DataFi is also the most favorable decentralized AI project for ordinary investors to participate in.
Although the emergence of AI tools has lowered the learning threshold to some extent, the original intention of decentralized AI is also to break the current monopoly of giants in the AI business; however, it must be admitted that many current projects are not very participatory for retail investors without technical backgrounds—the participation in decentralized computing power network mining is often associated with expensive upfront hardware investments, and the technical barriers in the model market easily deter ordinary participants.
In contrast, this is one of the few opportunities for ordinary users to seize during the AI revolution—Web3 allows you to participate without signing a data factory contract; all you need is to log in to your wallet with a click of your mouse, and you can engage in various simple tasks, including: providing data, tagging based on human intuition and instinct, evaluating simple tasks, or further using AI tools for some simple creations and participating in data transactions. For seasoned users, the difficulty level is basically zero.
Potential projects of Web3 DataFi.
Where the money flows, the direction follows. Aside from Scale AI receiving 14.3 billion USD investment from Meta in the Web2 world and Palantir's stock skyrocketing more than 5 times within a year, the DataFi track also performs exceptionally well in Web3 financing. Here we provide a brief introduction to these projects.
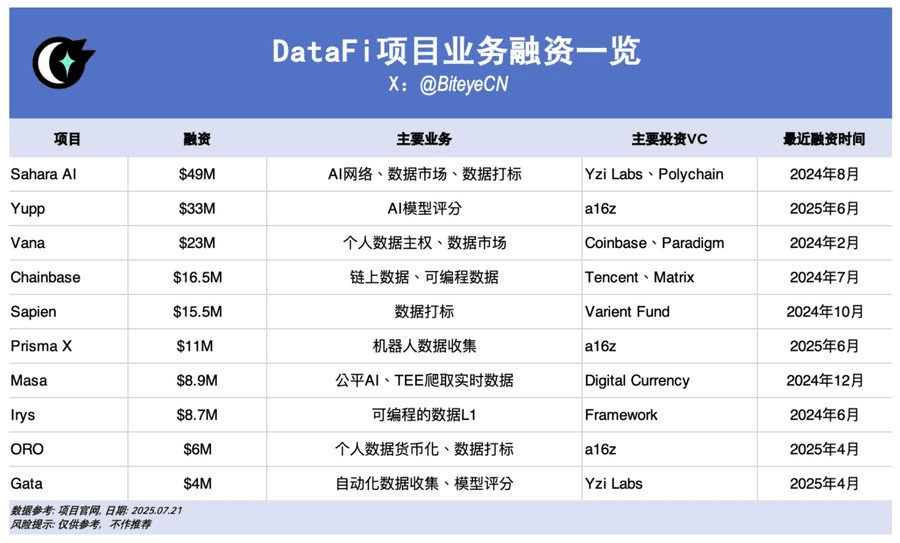
Sahara AI, @SaharaLabsAI, raised 49 million USD.
Sahara AI's ultimate goal is to build a decentralized AI super infrastructure and trading market, with the first trial being AI Data. Its DSP (Data Services Platform) public beta version will be launched on July 22, allowing users to earn token rewards by contributing data and participating in data labeling tasks.
Link: app.saharaai.com
Yupp, @yupp_ai, raised 33 million USD.
Yupp is a feedback platform for AI models, mainly collecting user feedback on the output content of models. The current main task is for users to compare the outputs of different models on the same prompt and select the one they think is better. Completing tasks can earn Yupp points, which can be further exchanged for stablecoins like USDC.
Link: https://yupp.ai/
Vana, @vana, raised 23 million USD.
Vana focuses on transforming users' personal data (such as social media activities, browsing history, etc.) into monetizable digital assets. Users can authorize their personal data to be uploaded to the corresponding data liquidity pools (DLP) in DataDAOs, and this data will be aggregated for AI model training and other tasks, with users receiving corresponding token rewards.
Link: https://www.vana.org/collectives
Chainbase, @ChainbaseHQ, raised 16.5 million USD.
Chainbase focuses on on-chain data and currently covers over 200 blockchains, transforming on-chain activities into structured, verifiable, and monetizable data assets for dApp development. Chainbase's business is mainly obtained through multi-chain indexing and processed through its Manuscript system and Theia AI model, with low current participation from ordinary users.
Sapien, @JoinSapien, raised 15.5 million USD.
Sapien's goal is to transform human knowledge into high-quality AI training data on a large scale. Anyone can engage in data labeling work on the platform and ensure data quality through peer validation. Users are also encouraged to build long-term credibility or make commitments through staking to earn more rewards.
Link: https://earn.sapien.io/#hiw
Prisma X, @PrismaXai, raised 11 million USD.
Prisma X aims to create an open coordination layer for robots, with physical data collection being key. The project is currently in its early stages; according to a recently released white paper, participation may involve investing in robots to collect data, remotely operating robot data, and so on. Currently, a quiz activity based on the white paper is open for participation to earn points.
Link: https://app.prismax.ai/whitepaper
Masa, @getmasafi, raised 8.9 million USD.
Masa is one of the top subnet projects in the Bittensor ecosystem, currently operating data subnet number 42 and agent subnet number 59. The data subnet aims to provide real-time access to data, mainly through miners crawling real-time data on X/Twitter using TEE hardware; the participation difficulty and cost are relatively high for ordinary users.
Irys, @irys_xyz, raised 8.7 million USD.
Irys focuses on programmable data storage and computation, aiming to provide efficient, low-cost solutions for AI, decentralized applications (dApps), and other data-intensive applications. Currently, there are not many opportunities for ordinary users to participate in data contributions, but there are multiple activities available during the current testnet phase.
Link: https://bitomokx.irys.xyz/
ORO, @getoro_xyz, raised 6 million USD.
ORO aims to empower ordinary people to participate in AI contributions. Supported methods include: 1. Linking personal accounts to contribute personal data, including social accounts, health data, e-commerce finance, etc.; 2. Completing data tasks. The test network is now online and open for participation.
Link: app.getoro.xyz
Gata, @Gata_xyz, raised 4 million USD.
Positioned as a decentralized data layer, Gata has currently launched three key products for participation: 1. Data Agent: a series of AI agents that can automatically run and process data as soon as users open the webpage; 2. AII-in-one Chat: a mechanism similar to Yupp's model evaluation to earn rewards; 3. GPT-to-Earn: a browser plugin that collects user dialogue data on ChatGPT.
Link: https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
How to view these current projects?
Currently, the barriers to these projects are generally not high, but it must be acknowledged that once user accumulation and ecological stickiness are established, platform advantages will quickly accumulate. Therefore, early efforts should focus on incentive measures and user experience; only by attracting enough users can this big data business succeed.
However, as a labor-intensive project, these data platforms must consider how to manage human resources while attracting them, ensuring the quality of data output. After all, many Web3 projects suffer from a common issue—most users on the platform are merely ruthless profit seekers—they often sacrifice quality for short-term gains. If they are allowed to become the main users of the platform, it will inevitably lead to bad money driving out good, ultimately jeopardizing data quality and failing to attract buyers. Currently, we see projects like Sahara, Sapien, etc., emphasizing data quality and working hard to establish long-term healthy partnerships with the human resources on their platforms.
Additionally, insufficient transparency is another issue facing current on-chain projects. Indeed, the impossible triangle of blockchain has led many projects in the startup phase to only follow a "centralization promotes decentralization" path. But increasingly, many on-chain projects give the impression of being "old Web2 projects dressed in Web3 skin"—there is very little publicly traceable data available, and even the roadmap is hard to see any public, transparent long-term commitment. This is undoubtedly toxic to the long-term healthy development of Web3 DataFi, and we hope that more projects will stay true to their original intentions and speed up the pace of openness and transparency.
Finally, the path to mass adoption of DataFi can also be viewed in two parts: one part is to attract enough toC participants to join this network, forming a new force in data collection/generation projects and consumers of the AI economy, creating an ecological closed loop; the other part is to gain recognition from currently mainstream toB large companies, as they are indeed the main source of large data orders in the short term. In this regard, we also see that Sahara AI, Vana, and others have made good progress.
Conclusion
Fatalism aside, DataFi is about nurturing machine intelligence with human intelligence over the long term, while ensuring that human intelligence's labor yields returns through smart contracts and ultimately enjoys the feedback from machine intelligence.
If you are anxious about the uncertainties of the AI era and still hold blockchain ideals amidst the ups and downs of the crypto world, then following the footsteps of many capital tycoons and joining DataFi is a good choice.
This article comes from a submission and does not represent BlockBeats' views.



