Ich interessiere mich normalerweise nicht für Projekte, die sich als "die Lösung für das Problem des Datenbesitzes im Bereich KI" positionieren. Nicht weil das Problem nicht real ist, sondern weil die Erzählungen so oft wiederholt wurden, dass sie anfangen, im Hintergrundrauschen unterzugehen. Jeder Zyklus bringt einen neuen Versuch, "Daten neu zu strukturieren", "Besitz neu zu definieren" oder "den Wertfluss von KI freizuschalten", und die meisten von ihnen scheitern unter dem gleichen Gewicht: Sie überschätzen, wie sehr der Markt sich für Fairness interessiert, wenn Geschwindigkeit das Einzige ist, was bewertet wird.
Als ich zum ersten Mal auf OpenLedger stieß, war die Reaktion nicht Neugier. Es war Zögern. Nicht die skeptische Art, die alles sofort abschaltet – sondern die müde Art. Die Art, die geprägt ist von der Beobachtung, dass zu viele vielversprechende Frameworks in Dashboards zerfallen, die niemand benutzt.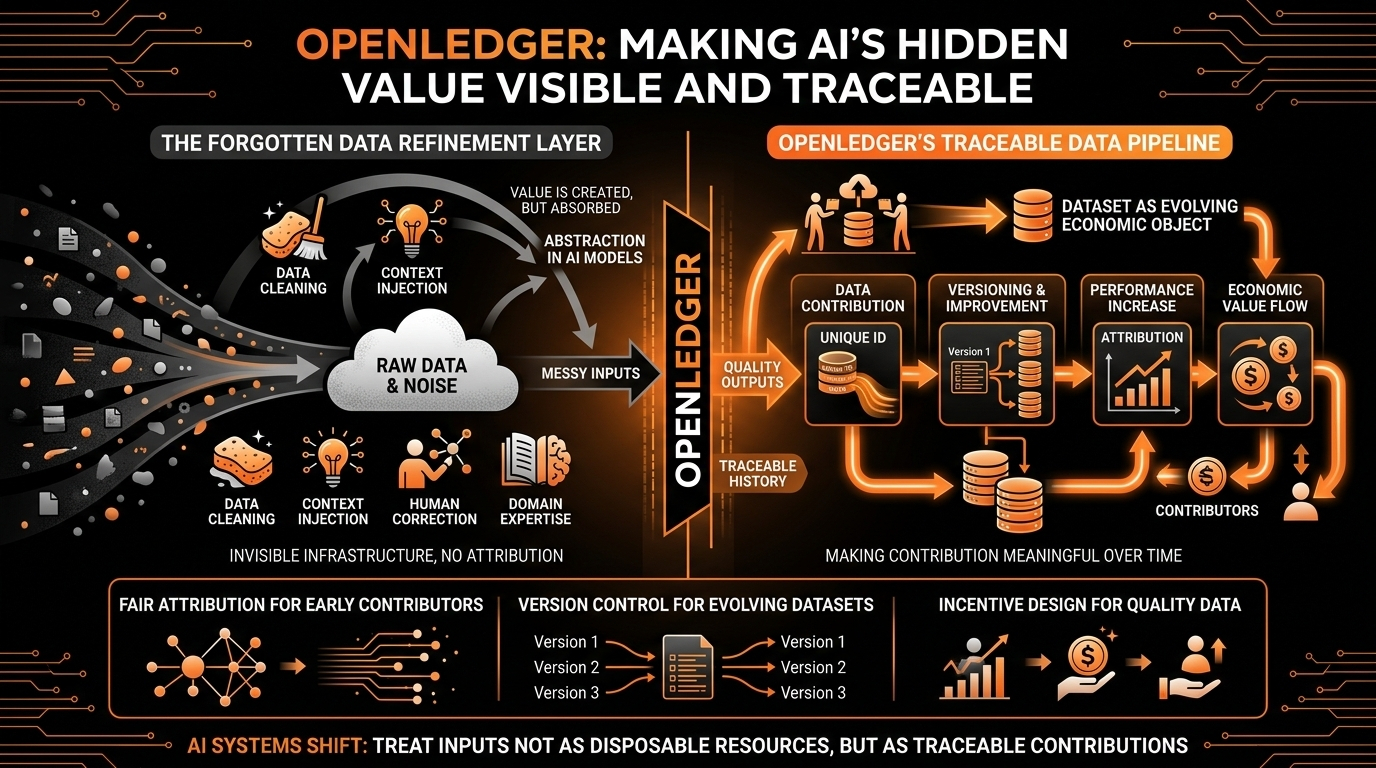
Aber die Idee ließ sich nicht leicht los, und das bedeutet normalerweise, dass darunter etwas Wertvolles steckt.
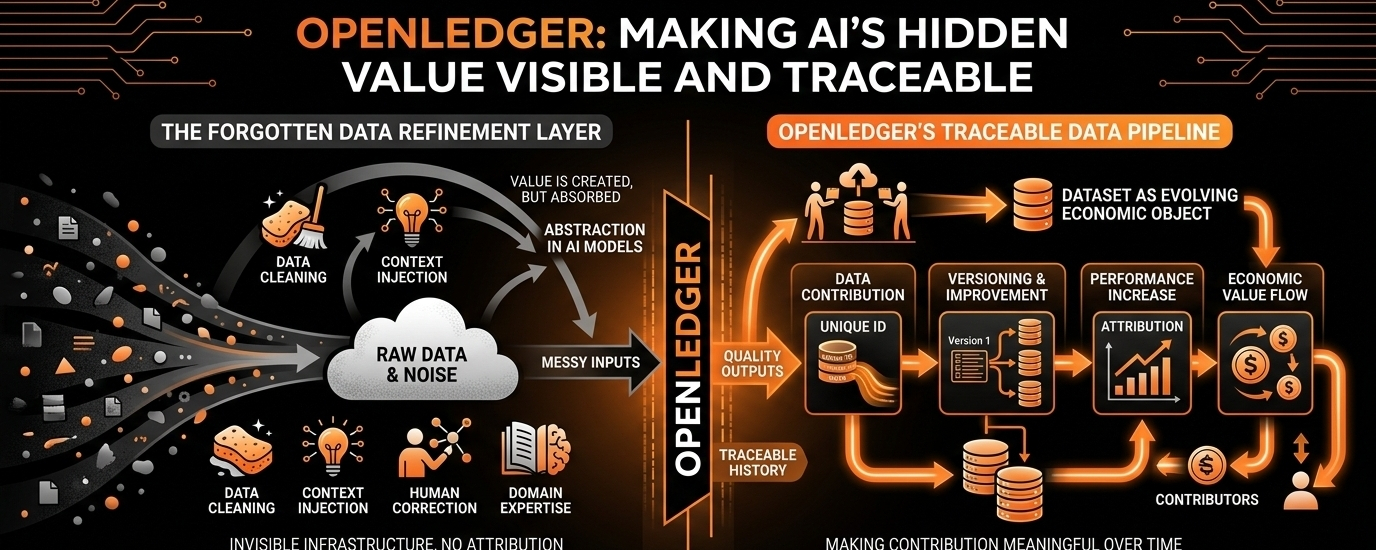
Die meisten Menschen betrachten KI als ein fertiges Produkt: ein Modell, einen Agenten, eine Schnittstelle, eine Antwort. Was ignoriert wird, ist alles, was diesen Output möglich macht. Datenbereinigung, Kontextinjektion, menschliche Korrektur, Fachwissen, Feedback-Schleifen und Handhabung von Ausnahmefällen. Die langsame und unglamouröse Arbeit, rohes Rauschen in etwas zu verwandeln, das sich wie Intelligenz verhält.
Diese Schicht taucht nicht in Demos auf. Sie trendet nicht in Zeitlinien. Sie wird nicht in Investorenpräsentationen verpackt, so wie es Modelle tun. Aber ohne sie funktioniert das System nicht.
Und hier beginnt das Muster, vertraut zu wirken – insbesondere wenn du auch Zeit im Kryptobereich verbracht hast. In sowohl KI- als auch Krypto-Systemen gibt es immer eine versteckte Gruppe von Mitwirkenden, die die grundlegende Arbeit leisten. Sie sind frühe Nutzer, frühe Tester, frühe Datenanbieter, frühe Community-Bauer. Sie schaffen Wert lange bevor Wert sichtbar wird. Und dann, wenn das System reift, verschwinden sie normalerweise von der Wertkarte – nicht weil sie nicht mehr existieren, sondern weil das System aufhört, sie zu verfolgen.
Ich habe dieses dynamische Muster genug oft gesehen, dass es fast strukturell statt zufällig erscheint. Ein System wächst, Mitwirkende strömen herein, Rauschen wird gefiltert, Wert beginnt sich zu bilden und irgendwo in diesem Übergang bricht die Zuordnung. Die frühen Inputs, die das System nützlich gemacht haben, werden nicht mehr nachvollziehbar. Die Personen, die das Verhalten des Modells, des Datensatzes oder des Netzwerks geprägt haben, sind nicht mehr Teil des Wertgesprächs. Sie werden zur unsichtbaren Infrastruktur.
KI macht das noch extremer, wegen der Art und Weise, wie Modelle tatsächlich lernen. Es gibt keine klare Linie zwischen "diese Daten verursachten jenes Ergebnis". Alles ist vermischt, abstrahiert und statistisch über Milliarden von Parametern verteilt. Selbst wenn der Beitrag essentiell ist, wird es analytisch unbequem, ihn zu verfolgen. Und Systeme neigen dazu, unbequeme Dinge zu vermeiden.
Das ist die Spannung, in der OpenLedger versucht, sich zu bewegen.
Ohne Branding versucht OpenLedger, Datenbeiträge über die Zeit nachvollziehbar und bedeutungsvoll zu machen. Nicht nur "du hast einen Datensatz hochgeladen", sondern was hat dieser Datensatz verbessert, wie hat er sich über Versionen entwickelt, welche Beiträge haben die Leistung gesteigert und wo ist tatsächlich Wert entstanden. Mit anderen Worten, es behandelt Datensätze weniger wie statische Dateien und mehr wie sich entwickelnde wirtschaftliche Objekte.
Dieser Wandel ist wichtiger, als er klingt. Denn im Moment verhalten sich die meisten KI-Datensätze wie tote Vermögenswerte. Sie werden konsumiert, absorbiert und vergessen. Sobald sie in die Trainingspipeline eingehen, verschwinden sie in der Abstraktion. OpenLedger versucht, dieses Verschwinden weniger absolut zu machen.
Es gibt etwas, was die Branche selten laut sagt: Gute KI-Daten sind zu Beginn nicht sauber. Sie sind chaotisch, unvollständig, inkonsistent und oft frustrierend zu bearbeiten. Der eigentliche Wert entsteht im Prozess der Verfeinerung – wenn jemand Rauschen entfernt, Labels korrigiert, fehlenden Kontext hinzufügt, schwache Einträge umstrukturiert und Daten an die reale Nutzung anpasst. Es ist langsame Arbeit, fast unsichtbare Arbeit, und sie wird selten als wirtschaftlich wichtig angesehen.
Aber wenn du jemals gesehen hast, wie ein Modell von "irgendwie nutzlos" zu "schockierend genau" wechselt, weißt du genau, woher dieser Wandel kommt. Es liegt nicht an der Modellarchitektur. Es ist die Datenqualitätsstufe. Auf dieser Ebene konzentriert sich OpenLedger.
Es gibt einen Grund, warum dieses Konzept immer wieder in kryptonativen KI-Diskussionen auftaucht. Krypto hat bereits ein ähnliches Muster in Finanzen und Netzwerken aufgedeckt: Frühe Mitwirkende erhalten selten proportionalen Nutzen, es sei denn, das System ist darauf ausgelegt, die Zuordnung zu bewahren. Nutzer bootstrappen Liquidität, Gemeinschaften bootstrappen Aufmerksamkeit, Bauherren bootstrappen Ökosysteme, und dann reift das System und frühe Mitwirkende werden oft zu "Wachstumsgeschichte"-Figuren, anstatt aktive Teilnehmer an der Wertverteilung zu sein.
OpenLedger wendet im Grunde dieselbe Kritik auf KI-Datenpipelines an, nicht auf philosophische Weise, sondern auf strukturelle. Wenn Daten Intelligenz schaffen und Intelligenz Wert schafft, dann ist es nicht nur unfair, sondern auch unvollständige Buchführung, die Herkunft der Daten zu ignorieren.
Das Problem ist, dass die Verfolgung von Beiträgen in der KI nicht nur schwierig ist, sondern auch mit der Art und Weise, wie moderne KI-Systeme gestaltet sind, in Konflikt steht. KI-Systeme bevorzugen Abstraktion über Nachvollziehbarkeit, Leistung über Transparenz und Output über Abstammung, weil Nachvollziehbarkeit Reibung einführt. Und Reibung verlangsamt die Akzeptanz.
OpenLedger bewegt sich absichtlich in die entgegengesetzte Richtung. Es führt Gedächtnis in einen Raum ein, der historisch alles vergessen hat, außer dem Endergebnis. Das ist sowohl die Stärke als auch das Risiko, denn sobald du Verantwortlichkeit in ein auf Skalierung optimiertes System einführst, exponierst du sofort Ineffizienzen, die zuvor verborgen waren.
Der schwierigste Teil ist nicht die Idee – es ist alles, was danach kommt. Wie misst man Beiträge fair? Wie verhindert man die Zucht von minderwertigen Ergebnissen? Wie vermeidet man, das Belohnungssystem zu manipulieren? Wie verfolgt man Einfluss, wenn Modelle nicht linear lernen? Wie verhindert man gefälschte Beitragsinflation? Das sind keine Randfälle; das sind Kernrisiken des Systems.
Jedes offene Beitragssystem zieht Rauschen an. Wenn Belohnungen existieren, optimieren die Leute für Belohnungen. Und wenn die Optimierung nicht mehr mit Qualität übereinstimmt, verschlechtert sich das System. Die eigentliche Frage ist also nicht, ob die Vision von OpenLedger logisch ist - die Idee ist klar genug. Es geht darum, ob das Anreizdesign den Kontakt mit den Nutzern übersteht.
Was jetzt zählt, ist nicht Theorie, sondern Verhalten. Filtert die Überprüfungsebene tatsächlich Qualität effektiv? Verbessert die Versionierung die Datensätze in der Praxis oder existiert sie nur als Konzept? Bevorzugen Bauherren tatsächlich diese Datensätze gegenüber Alternativen? Bleiben Mitwirkende, weil das System Qualität und nicht Aktivität belohnt? Überträgt sich die Zuordnung in etwas wirtschaftlich Bedeutungsvolles?
Denn wenn das alles nicht funktioniert, spielt es keine Rolle, wie elegant die Erzählung ist. Es wird nur eine weitere Schicht der Abstraktion über dasselbe Problem.
Wenn OpenLedger erfolgreich ist – sogar nur teilweise – wird der Wandel nicht dramatisch aussehen. Es wird keine "neue KI-Ära" sein. Es wird operativ aussehen. Sogar langweilig. Strukturiertere Datensätze. Bessere Zuordnung. Sauberere Feedback-Schleifen. Leicht transparentere Wertflüsse. Eine langsame Migration der Bauherren zu qualitativ hochwertigeren Datenquellen.
Und im Laufe der Zeit eine leise Änderung, wie KI-Systeme ihre Inputs behandeln – nicht als wegwerfbare Ressourcen, sondern als nachvollziehbare Beiträge.
Der Großteil des KI-Marktes ist immer noch besessen von dem, was man sehen kann: Modelle, Agenten, Schnittstellen, Ausgaben, Demos – die Dinge, die schnell vorankommen und beeindruckend aussehen. OpenLedger zeigt auf etwas weniger Sichtbares, auf die Ebene, wo Intelligenz tatsächlich zu entstehen beginnt, bevor sie zu etwas wird, das man screenshotten oder kommerzialisieren kann.
Diese Schicht hat immer existiert. Sie wurde nur nie richtig verfolgt, bewertet oder anerkannt. Ob OpenLedger das löst, ist noch eine offene Frage. Aber das Problem, auf das es hinweist, wird nicht verschwinden, und in diesem Markt allein ist das oft Grund genug, aufmerksam zu sein.
@OpenLedger #OpenLedger #openledger $OPEN
