
Die meisten Krypto-Teams, die KI in ihre Apps implementieren, stoßen auf dasselbe Problem. Das Modell gibt Antworten aus, die Benutzeroberfläche sieht schick aus und die Nutzer finden es vielleicht sogar hilfreich. Aber sobald man fragt, woher diese Antwort kommt, welche Daten tatsächlich den Unterschied gemacht haben oder wer den guten Kram beigesteuert hat, verwandelt sich alles schnell in eine Black Box. $OPEN #OpenLedger @OpenLedger
Genau deshalb ist OpenLedger einen Blick wert. Für Builder ist es heutzutage nicht mehr die große Herausforderung, ein weiteres LLM anzuschließen. Die echte Herausforderung besteht darin, KI-Produkte zu entwickeln, bei denen die Datenebene nicht völlig intransparent ist, bei denen die Mitwirkenden nicht unsichtbar sind und bei denen man tatsächlich nachvollziehen kann, wie das Endergebnis zustande kam. In der Krypto-Welt ist das wichtiger als in regulären Verbraucher-Apps. Trader, Forscher und Institutionen wollen nicht nur schnelle Antworten — sie wollen wissen, dass die Quellen solide sind, dass das System überprüfbar ist und dass es echte Verantwortlichkeit gibt, wenn die Dinge schiefgehen.
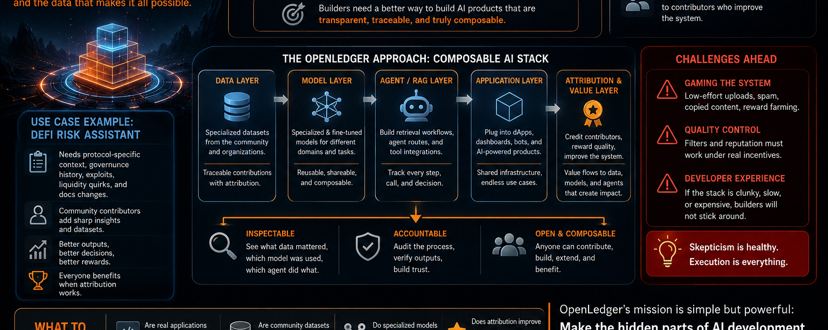
Was mir an OpenLedger's Ansatz gefällt, ist, dass es Daten, Modelle und Agenten als zusammensetzbare Teile eines Stacks behandelt, anstatt als ein abgeschlossenes Produkt. Als Entwickler solltest du in der Lage sein, spezialisierte Datensätze einzubinden, sie mit den richtigen Modellen zu verbinden, Abruf-Workflows oder Agenten-Routen zu erstellen und tatsächlich zu sehen, was Wert hinzufügt. Das trifft auf eine der größten Schwächen von KI derzeit zu: Attribution. Denk an einen DeFi-Risikoassistenten. Ein generisches Modell kann Liquidationen oder Stablecoins in allgemeinen Begriffen erklären. Aber ernsthafte Nutzer brauchen protokollspezifischen Kontext, alte Governance-Debatten, Liquiditätsquirks, Ausnutzungsgeschichte und Dokumentationsänderungen, die nicht in den Schlagzeilen erscheinen. Wenn jemand scharfe Notizen zu einem Protokoll beisteuert oder ein Datensatz die Ergebnisse erheblich verbessert, willst du das wissen – und idealerweise belohnen.
Ohne diese Nachvollziehbarkeit baust du nur eine weitere schicke Oberfläche über mysteriöses Zeug. Dieselbe Logik gilt für RAG-Setups und agentenbasierte Apps. Immer mehr Teams bauen Systeme, die nicht nur Fragen beantworten, sondern auch Kontext abrufen, Tools aufrufen und Aufgaben weiterleiten. Im Kryptobereich ist es wertvoll, diesen Prozess zu dokumentieren für Forschung, Compliance, Treasury-Management und Trading-Tools.
OpenLedger versucht, sich von dem alten Modell zu entfernen, in dem ein Team die Daten hortet, leise feinjustiert und ein geschlossenes Produkt ausliefert. Stattdessen können Datensätze zu gemeinsamen Vermögenswerten werden, Modelle können spezialisiert und wiederverwendbar sein, und Agenten können sich in verschiedene Anwendungen einfügen. Wenn Attribution tatsächlich funktioniert, kann der Wert besser zu den Personen und Daten fließen, die das System verbessern. Natürlich ist Skepsis hier gesund. Attribution klingt großartig, bis du echte Anreize einführst. Dann wirst du überlistet – mit geringem Aufwand hochgeladene Daten, Spam-Datensätze, kopierte Inhalte und Leute, die Belohnungen farmen. Das ist kein geringes Risiko; so passiert es normalerweise. OpenLedger muss beweisen, dass ihre Qualitätsfilter und Reputationsmechanismen echter wirtschaftlicher Aktivität standhalten können, nicht nur netten Demos.
Die Entwicklererfahrung wird ebenfalls entscheidend sein. Egal wie elegant die Vision ist, wenn der Stack klobig, langsam, schlecht dokumentiert oder teuer ist, werden die Entwickler abspringen. Krypto bewegt sich schnell, und die Leute bleiben nicht allein wegen der Ideologie. Die Signale, die ich beobachte, sind klar:
• Werden echte Anwendungen entwickelt oder nur Kampagnen-artige Demos?
• Sind Community-Datensätze tatsächlich nützlich genug, dass andere Teams sie verwenden wollen?
• Verbessern spezialisierte Modelle und Agenten die Workflows sinnvoll?
• Am wichtigsten, verbessert die Attributionsebene die Datenqualität oder pumpt sie nur das Beitragsvolumen?
Die echte Chance von OpenLedger besteht darin, die verborgenen Teile der KI-Entwicklung inspectierbar zu machen: Welche Daten waren tatsächlich wichtig, wer hat sie eingebracht, welcher Agent hat die Arbeit gemacht und wie floss der Wert. Es geht nicht darum, KI cooler klingen zu lassen. Es geht darum, Infrastruktur zu schaffen, die benutzerfreundlicher, verantwortlicher und wirklich offen für Beiträge ist.
Die große Frage ist, ob es nachvollziehbare Daten und zusammensetzbare KI-Teile in etwas verwandeln kann, auf das Entwickler im Alltag tatsächlich angewiesen sind, oder ob es eine überzeugende Idee bleibt, die auf eine echte Produkt-Markt-Anpassung wartet.$OPEN #OpenLedger  @OpenLedger
@OpenLedger