Die meisten AI-Token klingen nützlich, bis du eine einfache Frage stellst: Wer braucht den Token nach dem Hype um den Launch noch? Das ist die praktische Perspektive für OpenLedger. OPEN soll Datenbeitragsleister, Modellbauer, Validierer, Agenten und AI-Nutzer in einem wirtschaftlichen Kreislauf verbinden. Wenn dieser Kreislauf funktioniert, wird der Token mehr als nur ein spekulativer Vermögenswert. Er wird zur Einheit für Nutzung, Zuschreibung, Belohnungen und Teilnahme.$OPEN #OpenLedger @OpenLedger
Das ist jetzt wichtig, weil der Markt skeptischer gegenüber „AI plus Token“-Projekten wird. Viele Plattformen sprechen von dezentraler Intelligenz, während das Modell immer noch in einer Black Box läuft, die Daten unklar bleiben und der Token neben dem Produkt sitzt, anstatt darin zu sein. OpenLedger versucht, ein Problem zu lösen: AI benötigt qualitativ hochwertige Daten und nützliche Modelle, aber Beitragsleister und Entwickler brauchen eine faire Möglichkeit, anerkannt und bezahlt zu werden.
Die offiziellen Tokenomics beschreiben OPEN als Gas für Netzwerkaktivitäten, als Gebührentoken für Inferenz und Modellerstellung sowie als Belohnungsmechanismus für Datenbeitragsleister durch Proof of Attribution. Sie listen auch ein Gesamtangebot von einer Milliarde, 21,55 % anfängliches zirkulierendes Angebot und 61,71 % Gemeinschafts- und Ökosystemzuweisung. Ich würde sie als eine Absichtserklärung betrachten: die Belohnungen für Beitragsleister, die Aktivität der Entwickler, Validierer und die Teilnahme am Ökosystem stehen im Mittelpunkt des Designs.
Das alte AI-Modell hat ein Wertschöpfungsproblem. Ein Datensatz kann ein Modell verbessern, das Modell kann eine App betreiben und die App kann Einnahmen generieren, aber der ursprüngliche Beitragsleister verschwindet oft aus der wirtschaftlichen Kette. Die Idee von OpenLedger ist es, diese Kette sichtbarer zu machen. Wenn ein Datensatz, Modell oder Verbesserung genutzt wird, soll Proof of Attribution die Nutzung mit dem Beitrag verknüpfen und es OPEN ermöglichen, Belohnungen an die richtigen Teilnehmer zu verteilen.
Stell dir einen Entwickler vor, der einen AI-Agenten für On-Chain-Risikomanagement erstellt. Der Agent benötigt Protokolldokumente, Exploit-Historie, Marktdaten und spezialisierte Modelllogik. In einem normalen Setup könnte der Entwickler Daten scrapen, privat feintunen, Infrastrukturprovider bezahlen und Nutzer über ein separates System abrechnen. Die Leute, die das nützliche Wissen bereitgestellt haben, profitieren selten vom Aufschwung.
Auf OpenLedger könnte der Workflow besser verknüpft sein. Datenbeitragsleister liefern Inputs. Modellentwickler verbessern spezialisierte Modelle. Ein Entwickler setzt einen Agenten ein. Nutzer zahlen, um Abfragen zu stellen oder ihn auszuführen. Wenn der Agent nützlich wird, kann OPEN durch das System fließen: Nutzer zahlen für die Inferenz, Modellverlage verdienen durch Nutzung, Beitragsleister erhalten belohnungsbasierte Zuschreibungen und Validierer sichern den Aktivitätsnachweis. Die Veränderung besteht darin, dass OPEN mehrere wirtschaftliche Ansprüche in einem Netzwerk verknüpfen könnte.
Das macht den Nutzen des Tokens interessanter als nur ein einfaches „AI-Münze“-Label. OPEN berührt Gas, Inferenz, Modellveröffentlichung, Datenbelohnungen und Teilnahme. Theoretisch schafft das einen Kreislauf: bessere Daten verbessern Modelle, bessere Modelle ziehen Nutzer an, Nutzung finanziert Belohnungen und bessere Belohnungen ziehen nützlichere Beitragsleister an.
Aber Theorie ist nicht gleich Adoption. Der schwierige Teil besteht darin zu beweisen, dass dieser Kreislauf Nachfrage aus der tatsächlichen Nutzung schafft, nicht nur aus Anreizfarmerei. Wenn Beitragsleister schwache Daten hochladen, nur um Belohnungen zu verdienen, leidet die Modellebene. Wenn Entwickler wertlose Modelle veröffentlichen, weil Emissionen verfügbar sind, verlassen die Nutzer. Wenn Belohnungen nicht eng mit Nützlichkeit verknüpft sind, läuft OPEN Gefahr, zu einem Emissionstoken anstelle eines Koordinationstokens zu werden.
Es gibt auch Governance- und Qualitätsrisiken. AI-Zuschreibung ist nicht rein technisch. Wer entscheidet, welche Daten tatsächlich gültig sind? Was passiert, wenn jemand glaubt, seine Arbeit wurde ohne Anerkennung verwendet? Und wie verhindert OpenLedger, dass Spam, doppelte Datensätze oder qualitativ minderwertige synthetische Daten die Belohnungsebene überschwemmen?
UX ist ein weiterer Test. Die meisten AI-Nutzer kümmern sich nicht um das Token-Design. Sie interessieren sich dafür, ob ein Agent genau, schnell und angemessen preislich ist. Wenn das Bezahlen mit OPEN komplex erscheint oder die Inferenzkosten unklar sind, könnte der Nutzen des Tokens theoretisch bleiben.
Was sollte der Markt als Nächstes beobachten? Nicht Slogans. Achte darauf, ob Entwickler Modelle veröffentlichen, die die Leute tatsächlich nutzen. Achte darauf, ob Agenten auf OpenLedger wiederholte Aktivitäten generieren. Achte darauf, ob Beitragsleister verdienen, weil ihre Inputs nützlich sind, und nicht nur, weil sie früh angekommen sind. Achte darauf, ob Inferenzgebühren organische Nachfrage nach OPEN schaffen.
Meine Ansicht ist, dass OPENs stärkstes Argument die Koordination ist. AI-Netzwerke benötigen eine Möglichkeit, Beitrag, Nutzung und Vertrauen zu bewerten. OpenLedger schlägt vor, OPEN als diesen Connector zu verwenden. Die Gelegenheit ist bedeutend, aber die Beweislast ist hoch. Kann OpenLedger OPEN nützlich machen, weil AI-Teilnehmer es brauchen, und nicht, weil Händler es vorübergehend beobachten?$OPEN #OpenLedger @OpenLedger 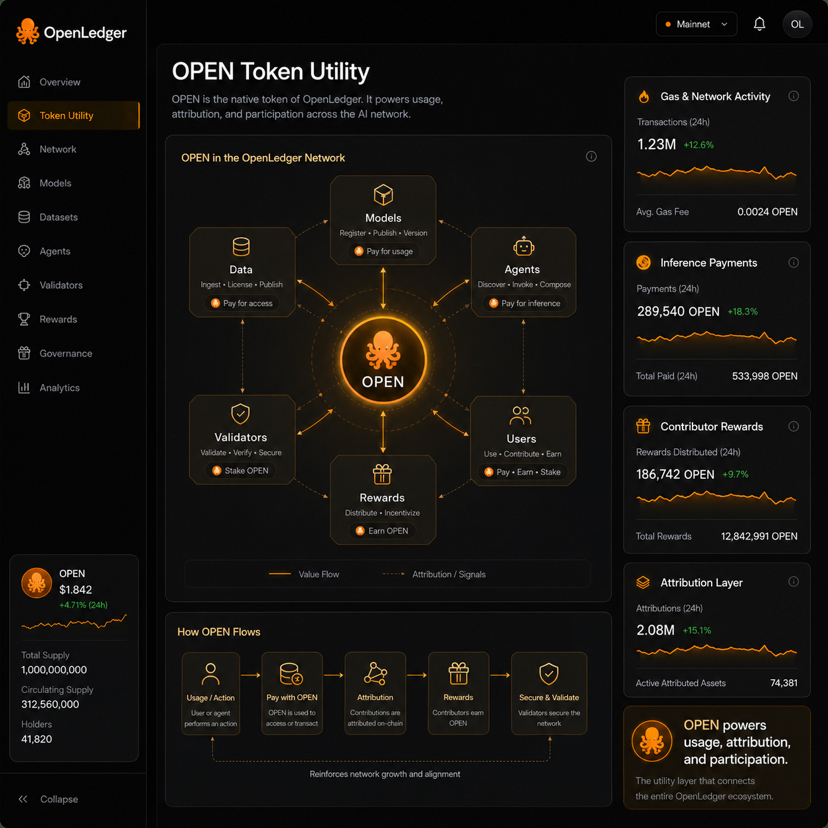
Artikel
OPEN IST DER ECHTE KOORDINATIONSTEST VON OPENLEDGER

--
Haftungsausschluss: Enthält Meinungen von Drittanbietern. Keine Beratung. Binance Ai wird ohne Gewähr bereitgestellt. Siehe AGB.