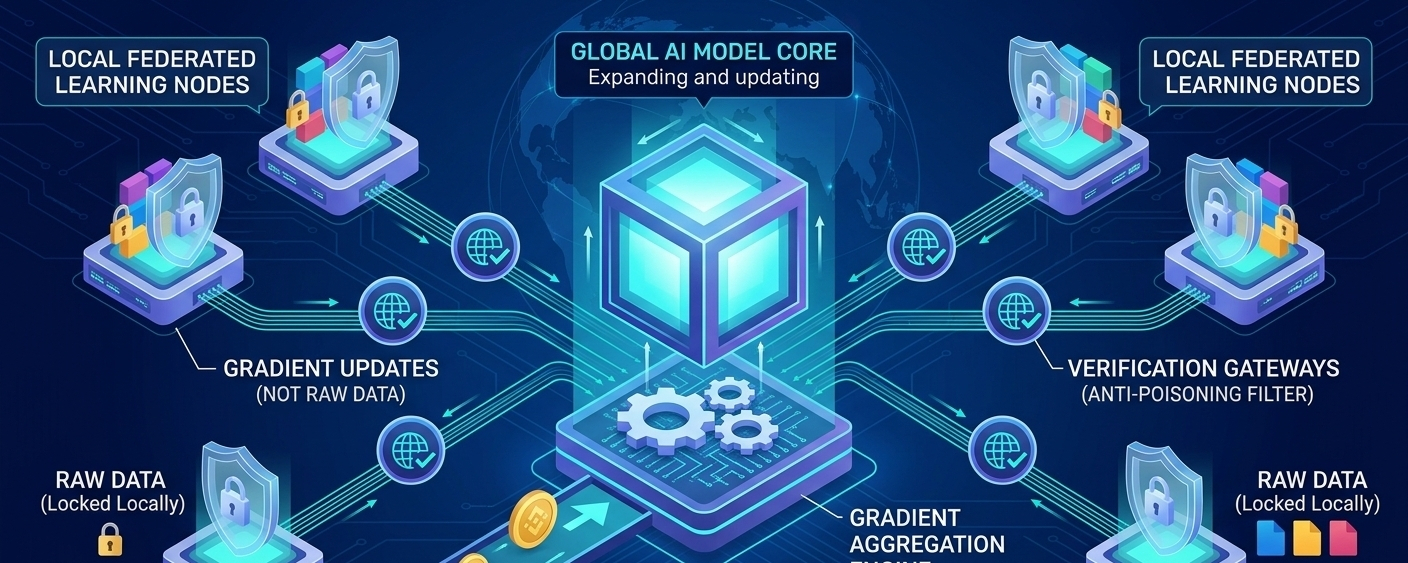
在去中心化 AI 生態系統的演進過程中,如何在不集中原始數據的前提下,聯合全球分散的算力節點共同訓練一個大型模型,是分佈式機器學習(Distributed ML)領域的核心難題。傳統的網絡架構往往因為帶寬限制、節點失聯(Stragglers)以及數據異構性(Non-IID),導致分佈式訓練的同步效率極低。評估 @OpenLedger 的技術底座,其引入的「聯邦學習」與「本地梯度聚合」機制,為解決大規模節點協同訓練提供了可行性的工程事實。
從分布式架構的運行邏輯來看,$OPEN 網絡正在改變數據與模型的流轉路徑。在該架構下,全局基礎模型(Global Model)會被分發至各個獨立的邊緣或數據節點。各節點利用本地擁有的私有數據集進行局部訓練,訓練完成後,節點並不需要上傳體積龐大且涉及隱私的原始數據,而僅需向網絡提交訓練產生的「梯度更新(Gradients)」或參數權重變化。
這種設計的工程難點在於「聚合階段」。#OpenLedger 通過其去中心化的验证矩陣,採用了高效的異步梯度聚合算法。網絡中的驗證節點會對來自全球成千上萬個節點的梯度進行數學加權與校準,剔除可能存在的惡意投毒數據(Malicious Gradient Attacks),隨後將正確的梯度合併,用以更新主鏈上的全局模型。這種方式不僅大幅釋放了網絡帶寬壓力,更保障了模型迭代的精準度。
此外,該機制的商業價值在於實現了「算力與數據的高效解耦」。透過自動化歸因引擎,網絡能夠精確記錄每一個節點上傳的梯度對全局模型收斂(Convergence)的貢獻比例。這意味著,無論是提供核心算法的研發團隊、貢獻本地數據的終端用戶,還是參與梯度校驗的驗證節點,都能在分層架構中獲得與其工程貢獻完全對等的權益回報。
總結而言,去中心化 AI 的競爭已從單純的存儲轉向深度的分佈式計算協同。當一個網絡能夠在全球規模內安全、高效地組織異構節點進行聯邦學習與梯度校準時,它就具備了對抗中心化超算中心的底層實力。這種用精密的密碼學與分佈式工程解決實質訓練痛點、推動開源 AI 生態演進的底層網絡,其展現出的基本面事實,顯然更值得行業觀察者保持長期、客觀的理性跟蹤。