Market's been doing that strange sideways drift for a few days — not crashing, not running, just sitting. The kind of quiet that makes you look at things you'd normally skip.
So I started poking around the $OPEN ecosystem. Nothing special planned, just following a thread. And somewhere in the middle of reading about how OpenLedger structures its Datanets — those community-owned datasets that feed into model training — something clicked that I hadn't expected.
Everyone talks about OpenLedger as a "fair AI" project. Pay contributors, track attribution, don't let big labs extract value for free. That story is clean and it's real. But the piece I kept coming back to was different.
The actual problem with AI development isn't that it's unfair. It's that it's badly coordinated.
Right now, building a useful AI model means one centralized team deciding what data matters, what gets labeled, what quality looks like. They control the curation pipeline. Everyone outside that team is either a data vendor or irrelevant. The reason AI development stays dominated by a handful of labs isn't just money — it's that they're the only ones with the coordination infrastructure to aggregate and filter knowledge at scale.
What OpenLedger is quietly doing is building an alternative coordination layer. Datanets aren't just data pools. Each one has a validation mechanism, an influence scoring system, and an economic penalty for low-quality submissions — you stake OPEN, and if your data gets flagged as redundant or adversarial, you lose. That's not a fairness mechanism. That's a quality-enforcement mechanism designed to make decentralized contribution work without a central team babysitting every upload.
The mainnet launched in November 2025. The Attribution Engine update in January 2026 kept those data-output links intact as models evolved through fine-tuning, which is the unsexy infrastructure work that makes the whole thing hold together over time rather than degrading with every model update.
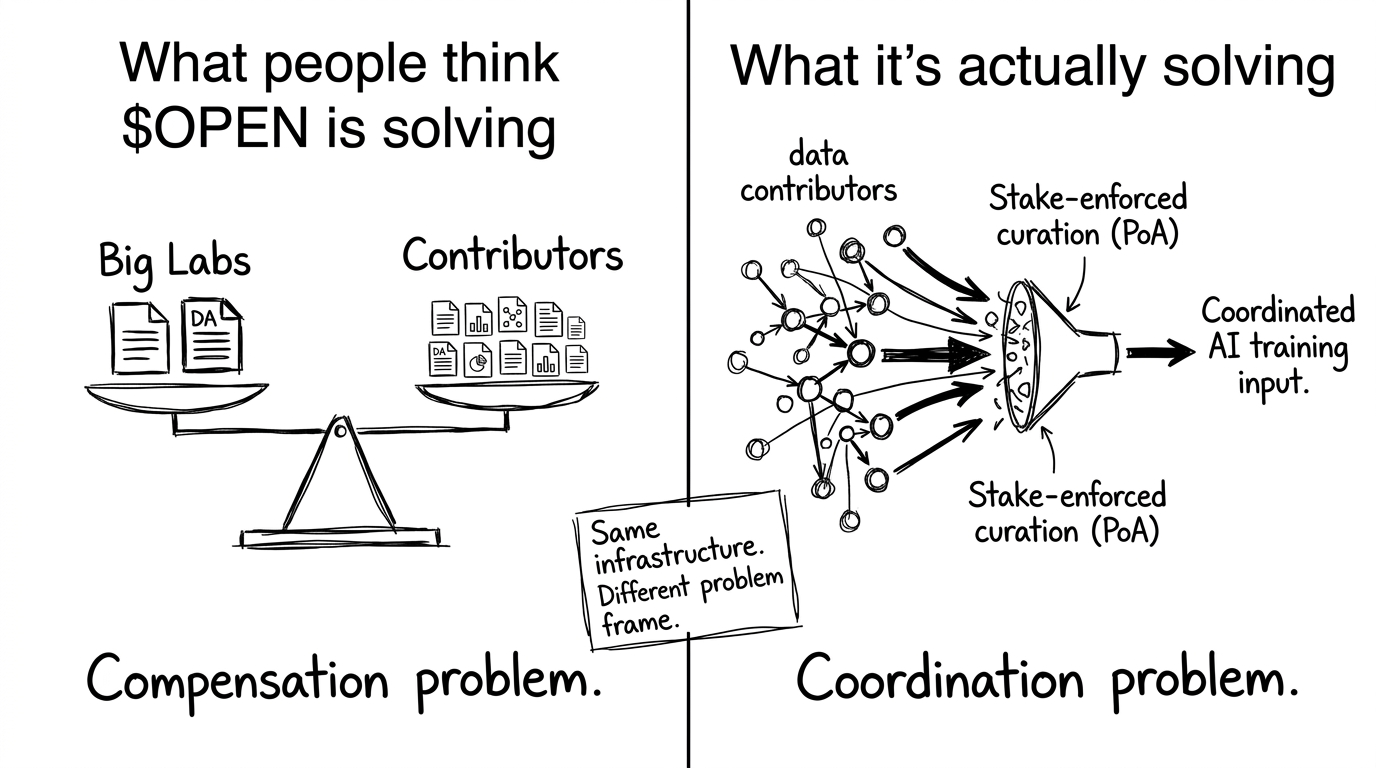
I thought this was mainly about compensation. But actually it's closer to… solving the problem of why open source AI keeps getting beaten by closed AI. Open source has contributors. It doesn't have coordinated, economically enforced curation.
But here's where I get uncertain.
Decentralized coordination works when participants have aligned long-term incentives. It breaks when incentives are short-term — and crypto ecosystems are historically very short-term. The $OPEN token has been trading well below its all-time high since the September 2025 TGE. If the reward signal weakens, the quality of the contributor base changes. And if contributor quality drops, the whole premise — that decentralized coordination produces better AI data than centralized labs — just doesn't hold.
I'm not convinced the incentive structure survives a sustained bear market. Not yet. The mechanism is elegant. Whether the human behavior on top of it matches the theory is a different question that only time answers.
There's also the scale problem. Centralized AI labs don't just have better coordination — they have compute, researchers, and distribution advantages that no data coordination layer fixes by itself. OpenLedger solves one constraint. Several others remain completely untouched.
Still, the reframe is interesting. This isn't about ethics. It's about whether decentralized coordination can ever be a genuine production input for AI development rather than a nice story attached to a token.
Anyway. Charts still look sideways. Probably going to be one of those weeks.
@OpenLedger #OpenLedger