

I was three minutes into reading a workflow breakdown when I noticed it.
Not the model output. Not the inference result. A small label sitting in the corner of the interface: "Datanet." I almost scrolled past it. I almost did scroll past it.
That's the tell.
Everyone is watching the model. The outputs. The benchmark scores. The inference speed. Those things are real. But they are, structurally, the last thing that happens. Before any of that runs, something had to hold the data. Something had to know where it came from. Something had to prove it wasn't scraped at 2am by a bot with no accountability attached. That something is boring. It has a boring name.
It's called a Datanet.
A Datanet, in OpenLedger's framework, is a shared community-owned data network with verifiable provenance. I'll restate that in worse, flatter words: it's a place where data lives, where that data has receipts, and where the people who contributed it retain some claim over it. That's the whole thing. There's no drama in that sentence and there shouldn't be.
But here is the uncomfortable part.
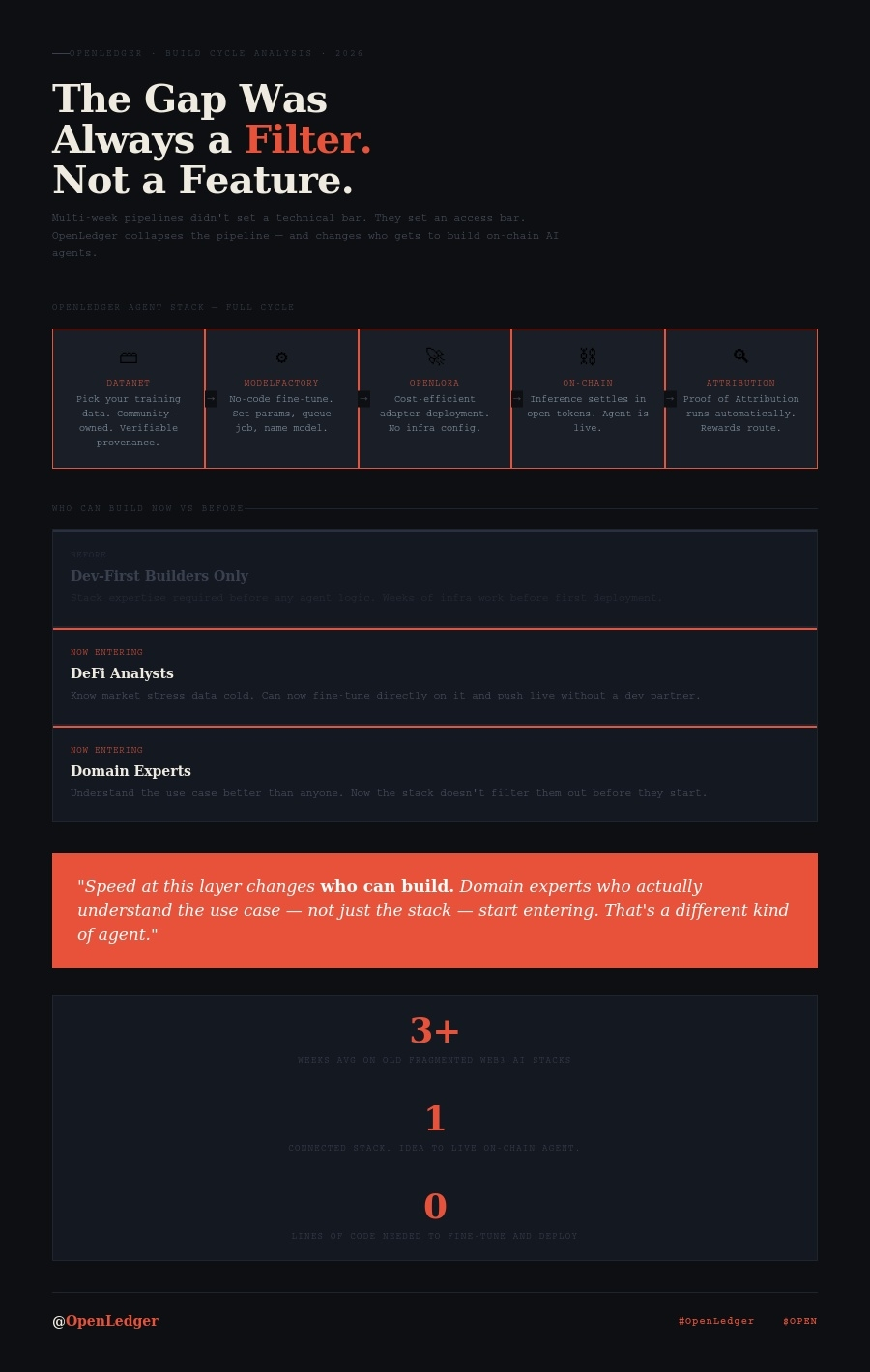
If the data layer is broken, everything downstream is broken. Not slowed. Not degraded. Broken. The model you're excited about trained on something. That something came from somewhere. A Datanet is the infrastructure that tracks whether "somewhere" is real, attributable, and governed by actual humans rather than aggregations nobody can audit.
Who decided what data enters a Datanet?
Who governs additions after launch?
What happens when two contributors claim the same source?
What does "community-owned" actually mean when capital enters the picture and incentives shift? What does verifiable provenance look like at scale, not in a controlled demo with cooperative participants?
I don't have clean answers. I don't think the space does either, yet.
Here's where it gets uncomfortable for anyone deploying capital into AI infrastructure. You're not only betting on a model. You're betting on the data layer under the model. You're betting that provenance is real, that the governance holds, that the Datanet storing the training inputs doesn't splinter when contributor incentives diverge. That's a systems design problem. Not a product problem. Not a narrative problem. A systems design problem that nobody in the coverage cycle finds interesting enough to open.
When I was sitting inside that workflow interface, looking at that small label, I kept circling back to one thing. This is where trust gets made or broken. Not at the model layer. Not at inference. Here. In this boring, unglamorous, community-governed data network that almost every analytical piece skips entirely.
The exciting visible action is inference. It's outputs. It's the thing you screenshot and share.
The boring layer is the Datanet. It's where provenance either exists or it doesn't. Where community governance either holds or collapses quietly. Where the whole claim about AI being more trustworthy than what came before falls apart if nobody actually built the foundation right.
I almost scrolled past it. Almost.
The question I started with, who actually owns the data layer underneath AI infrastructure, is still open. It's heavier now than it was. And I'm not sure "community-owned" is an answer yet. It might still just be an honest description of the problem.

