
撰文:李丹,華爾街見聞
今年 OpenAI 最爲大衆期待的產品來了。
美東時間 8 月 7 日週四,OpenAI 宣佈,推出新一代旗艦人工智能(AI)模型 GPT-5。它是 OpenAI 首個「一體化」的 AI 系統,是 OpenAI 首次將 o 系列模型的推理能力與 GPT 系列模型快速響應能力相結合的產物。
OpenAI CEO Sam Altman 在新模型發佈會上高度評價 GPT-5,稱它是「世界上最好的模型」,是相比此前模型的「重大升級」,並表示,它的問世標誌着,OpenAI 在實現通用人工智能(AGI)道路上邁出「重要一步」。
OpenAI 介紹,GPT-5 在多項基準測試中表現出色,在編程、數學、健康等領域達到前沿水平。GPT-5 在 SWE-bench Verified 代碼測試中得到 74.9% 的準確率,略超 Anthropic 本週二發佈的新模型 Claude Opus 4.1。同時,GPT-5 的幻覺問題大幅改善,錯誤信息率僅爲 4.8%,遠低於前代模型 GPT-4o 的 20.6%。
從本週四當日起,GPT-5 向所有 ChatGPT 的免費用戶和訂閱 Plus、Pro、Team 的付費用戶開放,作爲默認模型使用,並於一週內在 Enterprise 和 Edu 付費方案上線。
與 GPT-4o 一樣,GPT-5 免費和付費版的區別在於用量。Plus 用戶享有更高使用限額,Pro 用戶可無限使用並獲得增強版本 GPT-5 Pro。對於免費用戶,完整的推理功能可能需要幾天時間才能全部上線。一旦免費用戶達到 GPT-5 的用量限制,OpenAI 就將爲他們切換到更小的模型 GPT-5 mini。
OpenAI 週三還表示,將以每年 1 美元的象徵性收費向美國聯邦政府機構提供 ChatGPT 產品。具體來說是 ChatGPT 的企業版,其中包含強化的安全和隱私功能。
OpenAI 剛剛官宣 GPT-5,微軟就宣佈,從本週四開始,將 GPT-5 整合到旗下廣泛的產品組合中,包括 365 Copilot、Copilot、GitHub Copilot 和 Azure AI Foundry 等平臺,讓微軟的企業和消費者用戶能夠立即體驗到 GPT-5 的高級推理能力和編程優勢。
GPT-5 擁有編程、創意寫作、健康領域三大優勢
OpenAI 的 GPT5 發佈公告在一開頭就說,GPT-5 是 OpenAI「最智能、最快速、最實用的模型,其內置的思維能力,讓每個人都能擁有專家級的智慧。」
根據 OpenAI 介紹,作爲 OpenAI 的「最強大模型」,GPT-5 在三個關鍵領域實現了顯著提升。
首先是編程能力。GPT-5 是 OpenAI 迄今爲止最強大的編碼模型,在複雜的前端生成和大型代碼庫調試方面表現突出,能夠僅憑一個提示就創建美觀響應式的網站、應用程序 App 和遊戲。早期測試者注意到其在間距、排版和留白等設計選擇方面的改進。
在從 GitHub 獲取現實世界編碼任務的基準測試 SWE-bench Verified 中,GPT-5 思考後首次嘗試的準確率達 74.9%,高於 OpenAI 推理模型 o3 的 69.1% 和 GPT-4o 的 30.8%。
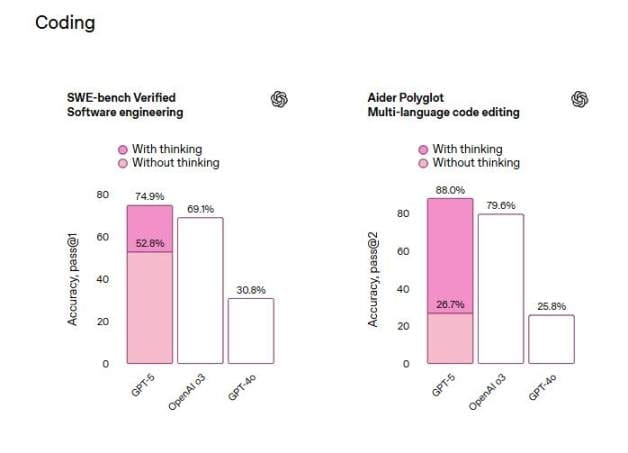
評論指出,這意味着,GPT-5 的表現略勝於 Anthropic 週二推出的 Claude Opus 4.1 和谷歌 DeepMind 的 Gemini 2.5 Pro,後兩者在 SWE-bench Verified 測試的得分分別爲 74.5% 和 59.6%。
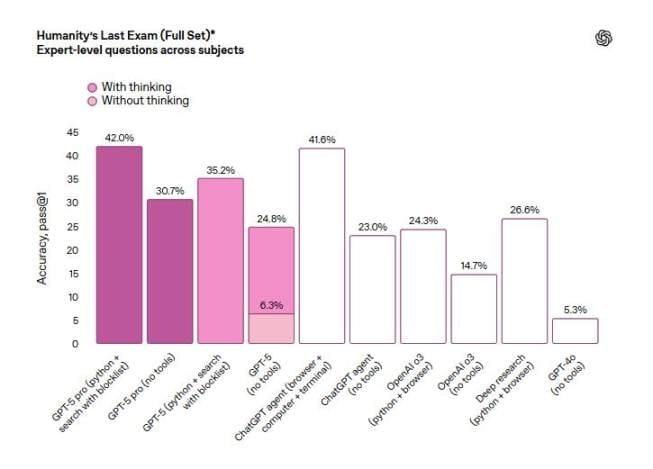
不過,在衡量數學、人文和自然科學領域模型表現的各學科專家級能力 Humanity『s Last Exam 測試中,帶有擴展推理功能的 GPT-5 增強版本 GPT-5 pro 在使用工具的情況下得分 42%。這略低於得分 44.4% 的 xAI 模型 Grok 4 Heavy。
Altman 稱,GPT-5 尤其擅長按需啓動整個軟件 App,也就是所謂的「氛圍編碼」、即用 AI 根據自然語言提示生成功能代碼,從而加快開發速度。
作爲實例,OpenAI 的研究者演示了,要求 GPT-5 創建一款網頁 App,幫助說英語的用戶學習法語,且該 App 必須有一個引人入勝的主題,包含抽認卡、測驗、經典的貪喫蛇遊戲,以及追蹤每日學習進度的方法。
研究者將相同的提示詞提交到兩個 GPT-5 窗口中,幾分鐘後生成了兩個不同的 App。OpenAI 的負責人稱,這些 App「存在一些缺陷」,但用戶可以根據個人喜好再調整 AI 生成的軟件,例如更改背景或添加更多標籤頁。
在創意寫作方面,GPT-5 能夠處理結構複雜的寫作任務,如無韻律的抑揚格五音步詩或自然流動的自由詩。OpenAI 的 ChatGPT 業務副總 Nick Turley 表示,GPT-5 在創意任務上表現出「更好的品味」,響應更自然。

健康諮詢是第三個重要提升領域。
GPT-5 能更積極地標記潛在健康問題,幫助用戶解析醫療結果,儘管 OpenAI 強調,ChatGPT 不能替代醫療專業人員。
在名爲 HealthBench Hard Hallucinations 的測試中,具備思考能力的 GPT-5 出現幻覺的錯誤信息率僅爲 1.6%。這遠低於 GPT-4o 和 o3 模型,後兩者的錯誤信息率分別爲 15.8% 和 12.9%。
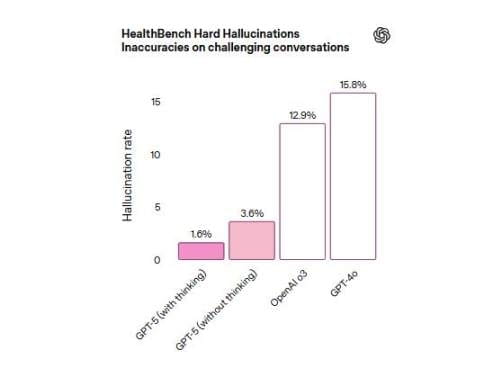
幻覺可能性顯著降低 新的安全訓練模式
OpenAI 稱,GPT-5 相比此前的模型更可靠和實用,它能更準確地回答現實世界的疑問,出現幻覺的可能性顯著降低。
在對代表 ChatGPT 生產流量的匿名提示詞啓用網絡搜索後,GPT-5 響應中包含事實錯誤的可能性比 GPT-4o 低約 45%;在思考後,GPT-5 響應中包含事實錯誤的可能性比 o3 低約 80%。下圖可見,GPT-5 響應的錯誤信息率僅爲 4.8%,GPT-4o 爲 20.6%,o3 爲 22%。
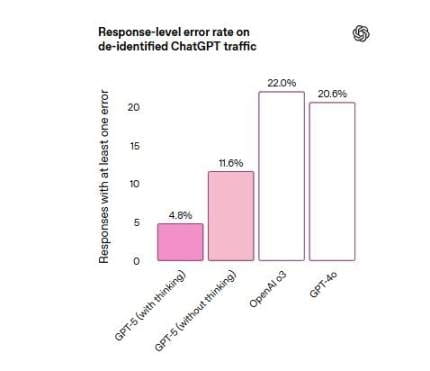
OpenAI 還表示,爲 GPT-5 引入了一種新的安全訓練形式,名爲安全補全(safe completions)。它教模型在安全範圍內儘可能給出最有幫助的答案。有時,這可能意味着部分回答用戶的問題,或者只提供高水平的回答。
如果需要拒絕,經過訓練的 GPT-5 會以透明的方式告知用戶拒絕的原因,並提供安全的替代方案。
在受控的實驗和 OpenAI 的生產模型中,OpenAI 都發現這種安全補全的方法更加細緻入微,能夠更好地引導雙重用途問題,增強對模糊意圖的魯棒性,並減少不必要的過度拒絕。
OpenAI 的後訓練負責人 Michelle Pokrass 表示:「GPT-5 已經過訓練,能夠識別任務何時無法完成,避免猜測,並能更清晰地解釋侷限性,相比之前的模型,這減少了無根據的斷言。」
推出四種可選的 ChatGPT 聊天預設性格
OpenAI 稱,GPT-5 在指令執行方面表現提升,其執行自定義指令的能力也得到了相應的提升。OpenAI 將爲所有 ChatGPT 用戶推出四種預設性格的全新研究預覽版。
初始的四種性格選項——憤世嫉俗者(Cynic)、機器人(Robot)、傾聽者(Listener)和書呆子(Nerd)都是可選的,用戶可在設置中隨時調整,用以匹配 ChatGPT 和用戶的溝通風格。
上述四種性格最初適用於文本聊天,之後將擴展到語音聊天,讓用戶無需編寫自定義提示詞即可設置 ChatGPT 的交互方式——無論是簡潔專業的、周到支持的,還是略帶諷刺的。
OpenAI 稱,所有這些新性格都達到或超過了我們減少諂媚行爲的內部評估標準。
Altman 盛讚歷史性突破 用回 GPT-4 後效果相當糟
在本週四的簡報會上,Altman 對 GPT-5 給予了極高評價,將 GPT-5 定位爲通往 AGI 的重要里程碑。他表示:
「在以往歷史上任何時期,擁有像 GPT-5 這樣的東西都是不可想象的。」「這是第一次感覺就像在與任何領域的專家交談。」
Altman 在簡報會上甚至不惜用「踩」GPT-4 擡高 GPT-5。他說:
「我嘗試過用回 GPT-4,但效果相當糟糕。」
GPT-5 採用統一的系統架構,配備實時路由器,能夠根據對話類型、複雜性和工具需求自動決定是快速響應還是進行深度「思考」。這消除了用戶選擇合適設置的需要,使 ChatGPT 更易於使用。
在經濟價值工作的內部基準測試中,使用推理模式的 GPT-5 在大約一半的案例中可與專家水平相當或更優,涵蓋法律、物流、銷售和工程等 40 多個職業。OpenAI VP Nick Turley 稱:「這個模型的感覺真的很好。」
Altman 比喻,使用 GPT-5 就像隨時擁有一支學歷通通爲博士的專家團隊。他還說:「在很多新領域,人們受到想法的限制,但實際上卻沒有執行能力。」
微軟全面整合搶佔先機
微軟在 GPT-5 發佈當日即宣佈,將其整合到廣泛的產品線中。在企業級應用方面,Microsoft 365 Copilot 將利用 GPT-5 更好地處理複雜問題、在長對話中保持專注並理解用戶上下文。企業用戶可通過推理功能處理電子郵件、文檔和文件。
對於消費者,Microsoft Copilot 的新智能模式將利用 GPT-5 幫助用戶發現最佳解決方案。用戶可通過 copilot.microsoft.com 或 Windows、Mac、Android 和 iOS 設備上的 Copilot 應用免費體驗 GPT-5。
開發者將通過 GitHub Copilot 和 Visual Studio Code 獲得 GPT-5 支持,用於編寫、測試和部署代碼。Azure AI Foundry 平臺將提供所有 GPT-5 模型,配備 AI 驅動的模型路由器,根據每個任務的複雜性、性能需求和成本效率選擇最優模型。
微軟 AI 紅隊使用嚴格的安全協議測試了 GPT-5 推理模型,結果顯示,該模型在惡意軟件生成、欺詐自動化等多種攻擊模式下展現出 OpenAI 歷代模型中最強的 AI 安全配置之一。