


正如大師達芬奇所說:"學習永遠不會讓思維疲憊。" 但在人工智能的時代,學習似乎可能會耗盡我們星球的計算能力。預計到 2030 年,人工智能革命將爲全球經濟注入超過 15.7 萬億美元,這一革命根本上建立在兩個基礎上:數據和計算的巨大力量。問題在於,AI 模型的規模正在以驚人的速度增長,訓練所需的計算能力大約每五個月翻一番。這造成了一個巨大的瓶頸。少數幾家巨型雲公司控制着王國的鑰匙,掌控 GPU 供應,創造了一個昂貴的、需要許可的、坦率地說,對於如此重要的事情而言,顯得有些脆弱的系統。
在這裏,故事變得有趣。我們正在看到一個範式轉變,一個稱爲去中心化 AI(DeAI)模型訓練的新興領域,它利用區塊鏈和 Web3 的核心理念來挑戰這種集中控制。
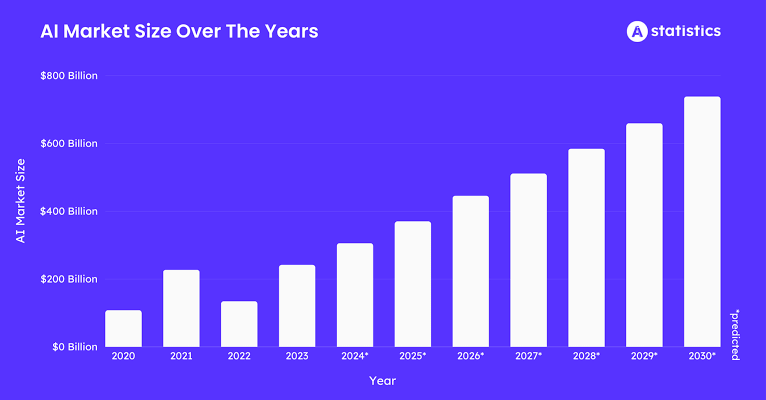
讓我們來看一下數字。到 2025 年,AI 訓練數據市場預計將達到約 35 億美元,每年增長約 25%。所有這些數據都需要處理。區塊鏈 AI 市場本身預計到 2025 年將接近 6.81 億美元,年複合增長率健康地在 23% 到 28% 之間。如果我們放眼更大的圖景,整個去中心化物理基礎設施(DePIN)領域,DeAI 是其中的一部分,預計到 2025 年將突破 320 億美元。
這意味着 AI 對數據和計算的渴求正在創造巨大的需求。DePIN 和區塊鏈正在介入提供供給,爲構建智能提供一個全球、開放和經濟合理的網絡。我們已經看到代幣激勵如何促使人們協調物理硬件,如無線熱點和存儲驅動器;現在我們將同樣的策略應用於世界上最有價值的數字生產過程:創造人工智能。
I. DeAI 技術棧
推動去中心化 AI 的動力源於一個深刻的哲學使命:建立一個更開放、更具韌性和公平的 AI 生態系統。這是關於促進創新,抵制我們今天所看到的權力集中。倡導者常常對比兩種組織世界的方式:"Taxis",即一箇中央設計和控制的秩序,和 "Cosmos",一個去中心化的、通過自主互動成長的秩序。

對 AI 的集中化方法可能會創造一種 "生活的自動補全",其中 AI 系統微妙地推動人類行動,並在每個選擇上削弱我們獨立思考的能力。去中心化是提出的解藥。這是一個框架,其中 AI 是一種工具,用於增強人類的繁榮,而不是引導它。通過分散對數據、模型和計算的控制,DeAI 旨在將權力重新交還給用戶、創造者和社區,確保智能的未來是我們共同擁有的,而不是少數公司所擁有的。
II. 解構 DeAI 技術棧
在其核心,可以將 AI 分解爲三個基本部分:數據、計算和算法。DeAI 運動正是爲了在去中心化基礎上重建這三大支柱。
❍ 支柱 1:去中心化數據
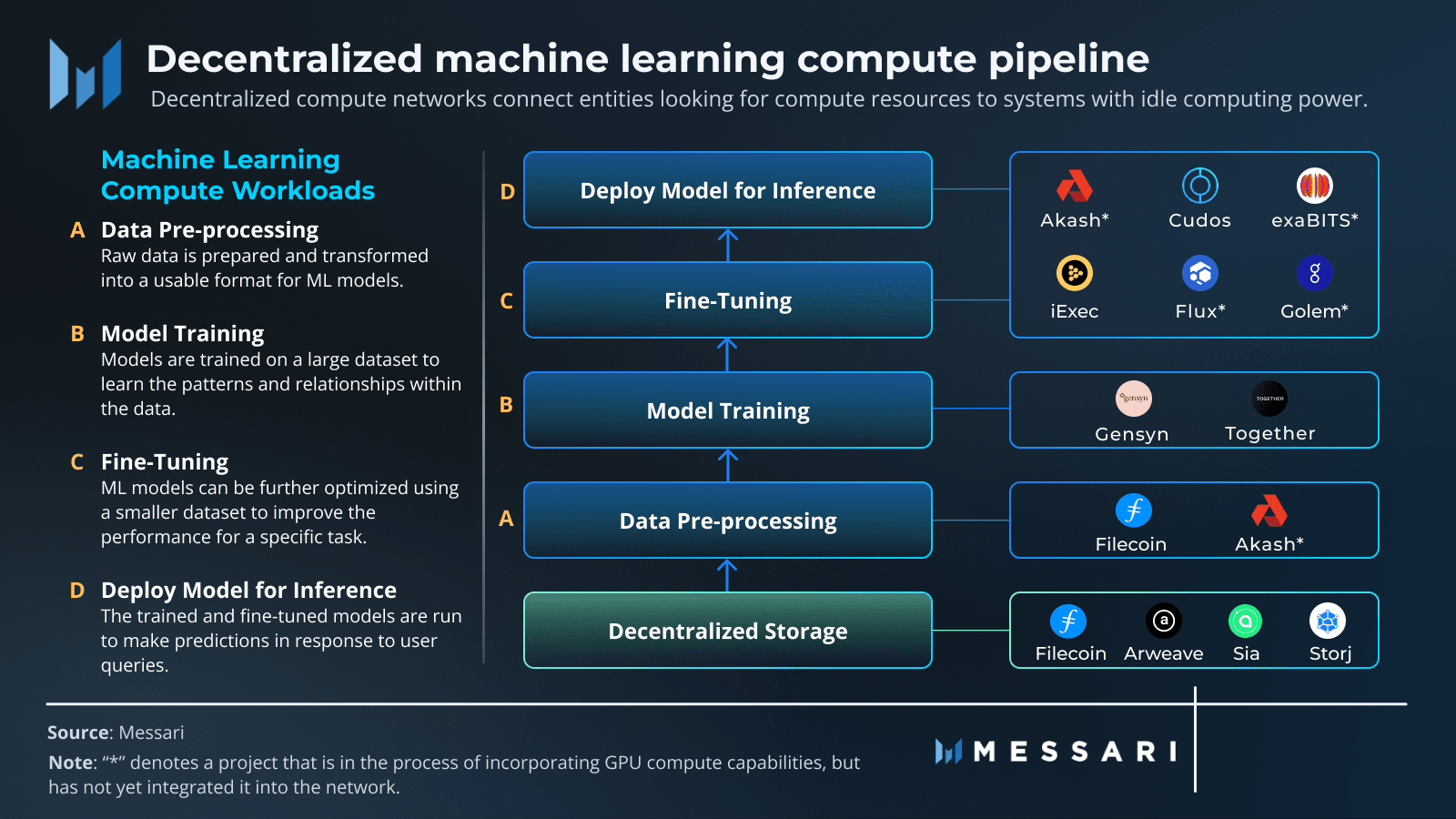
任何強大 AI 的燃料都是大量多樣的數據集。在舊模型中,這些數據被鎖定在亞馬遜網絡服務或谷歌雲等集中式系統中。這造成了單點故障、審查風險,並使新來者難以獲得訪問。去中心化存儲網絡提供了一種替代方案,爲 AI 訓練數據提供一個永久、不受審查和可驗證的家。
像 Filecoin 和 Arweave 這樣的項目在這裏扮演着關鍵角色。Filecoin 使用全球存儲提供商網絡,利用代幣激勵他們可靠地存儲數據。它使用聰明的加密證明,如複製證明和時空證明,以確保數據的安全和可用。Arweave 則有不同的看法:你一次性付款,你的數據將永遠保存在一個不可變的 "永久網" 上。通過將數據轉變爲公共財物,這些網絡爲 AI 開發創造了一個堅實、透明的基礎,確保用於訓練的數據集是安全且向所有人開放的。
❍ 支柱 2:去中心化計算
當前 AI 最大的障礙是獲得高性能計算,尤其是 GPU。DeAI 直接應對這個問題,通過創建協議來聚集和協調來自世界各地的計算能力,從消費級 GPU 到數據中心的閒置機器。這將計算能力從一種由少數看門人租賃的稀缺資源轉變爲一種液態、全球商品。像 Prime Intellect、Gensyn 和 Nous Research 這樣的項目正在爲這一新的計算經濟建立市場。
❍ 支柱 3:去中心化算法和模型
獲取數據和計算是一回事。真正的工作在於協調訓練過程,確保工作正確完成,並在一個你不能完全信任任何人的環境中讓每個人協作。這就是各種 Web3 技術結合形成 DeAI 操作核心的地方。
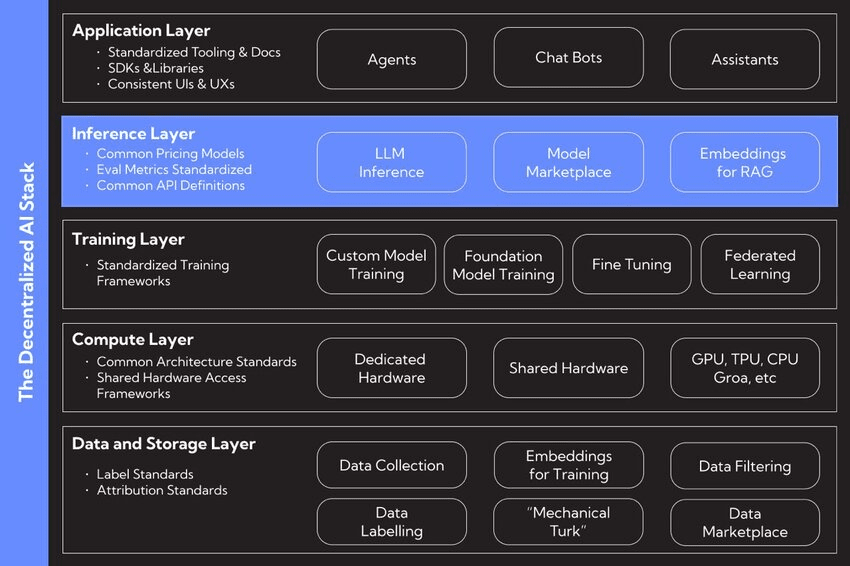
區塊鏈和智能合約:把這些看作是不變和透明的規則手冊。區塊鏈提供了一個共享的賬本來追蹤誰做了什麼,智能合約自動執行規則併發放獎勵,因此你不需要中介。
聯邦學習:這是一種關鍵的隱私保護技術。它允許 AI 模型在分散的不同位置上的數據上訓練,而無需這些數據移動。只有模型更新被共享,而不是你的個人信息,從而保持用戶數據的私密性和安全性。
代幣經濟學:這是經濟引擎。代幣創造了一個小型經濟體,獎勵人們爲貢獻有價值的東西,無論是數據、計算能力,還是對 AI 模型的改進。它使每個人的激勵方向一致,朝着共同的目標建立更好的 AI。
這個技術棧的美在於它的模塊化。一個 AI 開發者可以從 Arweave 獲取數據集,使用 Gensyn 的網絡進行可驗證訓練,然後在一個專門的 Bittensor 子網絡上部署完成的模型以賺錢。這種互操作性將 AI 開發的各個部分變成了 "智能樂高",激發出比任何單一封閉平臺都更具活力和創新的生態系統。
III. 去中心化模型訓練的工作原理
想象一下目標是創造一個世界級的 AI 廚師。舊的集中方式是將一個學徒鎖在一個祕密廚房中(就像谷歌的那樣),並擁有一本巨大的祕密食譜。去中心化的方法,使用一種稱爲聯邦學習的技術,更像是運行一個全球烹飪俱樂部。
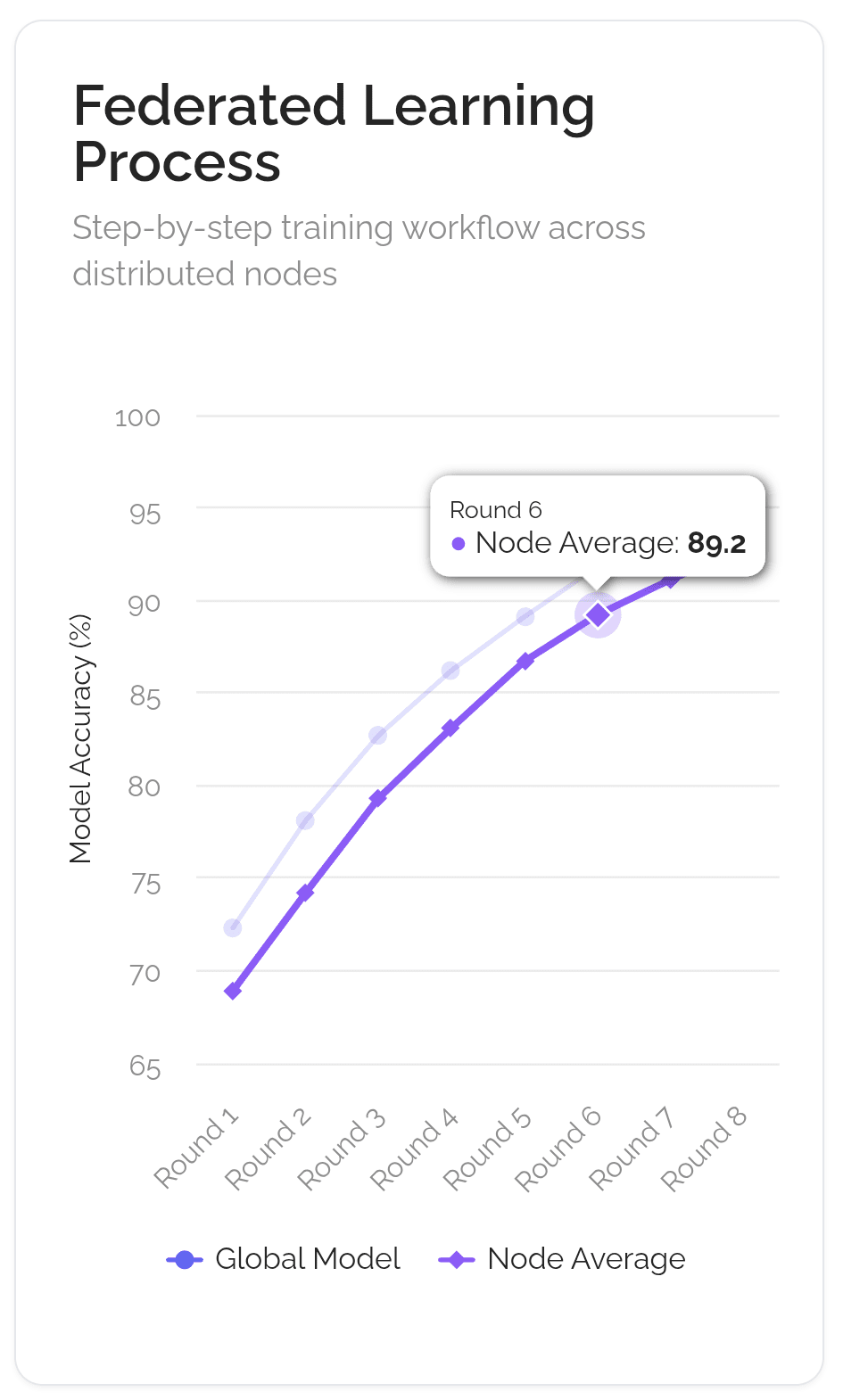
主食譜("全球模型")被髮送到全球數千名當地廚師。每位廚師在自己的廚房中嘗試這個食譜,使用他們獨特的本地食材和方法("本地數據")。他們不分享自己的祕密食材;他們只是記錄如何改進食譜("模型更新")。這些記錄被髮送回俱樂部總部。俱樂部然後結合所有的記錄創建出一個新的、改進的主食譜,發送出去進行下一輪。整個過程由一個透明的、自動化的俱樂部章程("區塊鏈")管理,確保每位參與者獲得信用並獲得公平的獎勵("代幣獎勵")。
❍ 關鍵機制
這個類比與允許這種協作訓練的技術工作流程非常接近。這是一個複雜的事情,但歸結爲幾個關鍵機制,使這一切成爲可能。
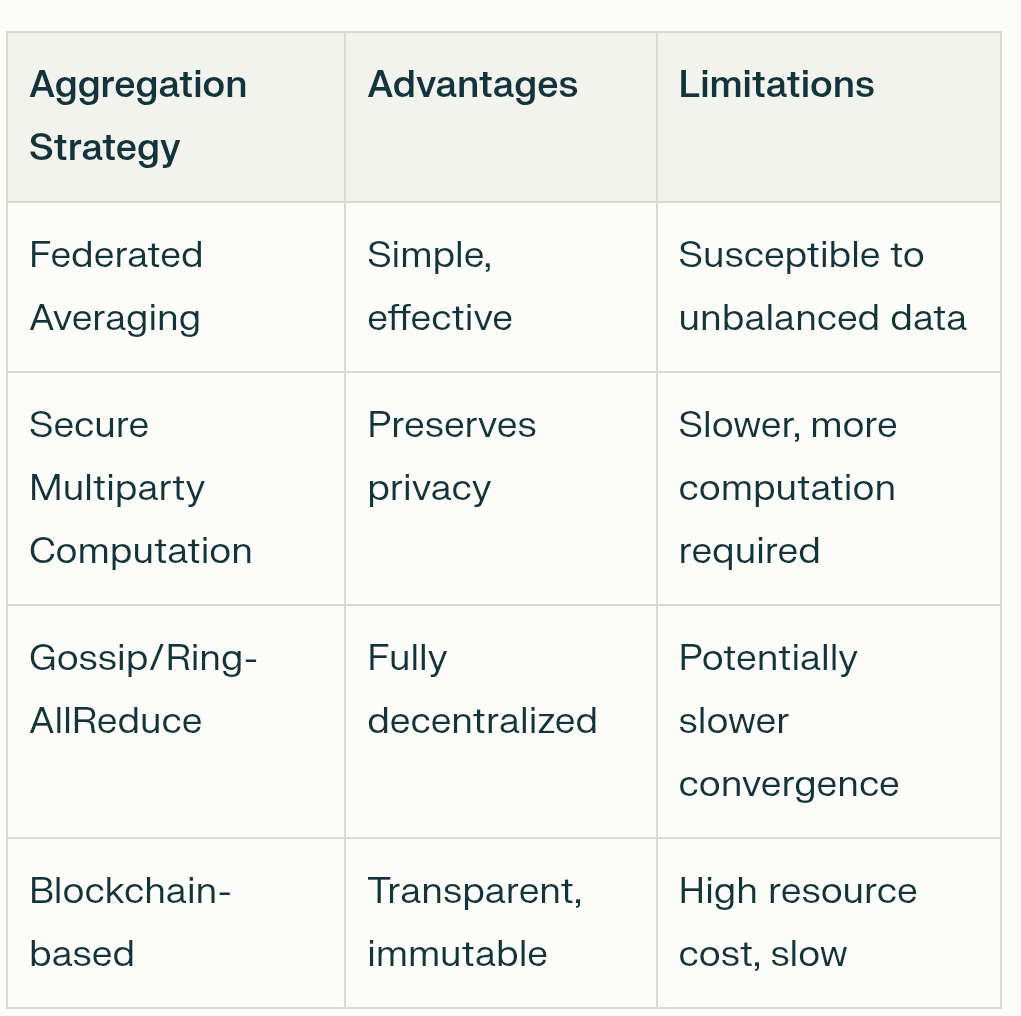
分佈式數據並行性:這是起點。不是一個巨大的計算機處理一個龐大的數據集,而是將數據集分解爲更小的部分,分佈在網絡中的許多不同計算機(節點)上。每個節點都獲得一個完整的 AI 模型副本以進行工作。這允許巨量的並行處理,顯著加快速度。每個節點在其獨特的數據片段上訓練其模型副本。
低通信算法:一個主要挑戰是保持所有這些模型副本的同步,而不阻塞互聯網。如果每個節點必須不斷地向每個其他節點廣播每一個微小的更新,這將非常緩慢且低效。這就是低通信算法發揮作用的地方。像 DiLoCo(分佈式低通信)這樣的技術允許節點在需要與更廣泛的網絡同步進度之前,獨立執行數百次本地訓練步驟。更新的方法,如 NoLoCo(無全歸約低通信),甚至更進一步,用 "八卦" 方法取代大規模的組同步,其中節點定期與單一隨機選擇的同伴平均它們的更新。
壓縮:爲了進一步減少通信負擔,網絡使用壓縮技術。這就像在發送郵件之前壓縮文件。模型更新,實際上是大量數字的列表,可以被壓縮以減小體積並加快發送速度。例如,量化降低了這些數字的精度(例如,從 32 位浮點數到 8 位整數),這可以在對準確性影響極小的情況下將數據大小縮小四倍或更多。修剪是一種消除模型中不重要連接的方法,使其更小、更高效。
激勵和驗證:在一個無信任的網絡中,你需要確保每個人都公平競爭並獲得相應的獎勵。這是區塊鏈及其代幣經濟的作用。智能合約充當自動化的託管,持有並分發代幣獎勵給貢獻有用計算或數據的參與者。爲了防止作弊,網絡使用驗證機制。這可能涉及驗證者隨機重新運行小部分節點的計算以驗證其正確性,或使用加密證明來確保結果的完整性。這創建了 "智能證明" 的系統,確保有價值的貢獻得到可驗證的獎勵。
容錯:去中心化網絡由不可靠、全球分佈的計算機組成。節點可以在任何時候掉線。系統需要能夠處理這一點,而整個訓練過程不會崩潰。這就是容錯的作用。像 Prime Intellect 的 ElasticDeviceMesh 這樣的框架允許節點動態加入或離開訓練運行,而不會導致系統範圍的故障。異步檢查點技術定期保存模型的進展,因此如果某個節點失敗,網絡可以迅速從上一次保存的狀態恢復,而不是從頭開始。
這一持續的、迭代的工作流程從根本上改變了 AI 模型的定義。它不再是一個由單一公司創建和擁有的靜態對象。它變成了一個活的系統,一個由全球集體不斷完善的共識狀態。該模型不是一個產品;它是一個由其網絡共同維護和保護的協議。
IV. 去中心化訓練協議
去中心化 AI 的理論框架現在正由越來越多的創新項目實施,每個項目都有獨特的策略和技術方法。這些協議創造了一個競爭的領域,在這裏不同的協作、驗證和激勵模型正在大規模測試。
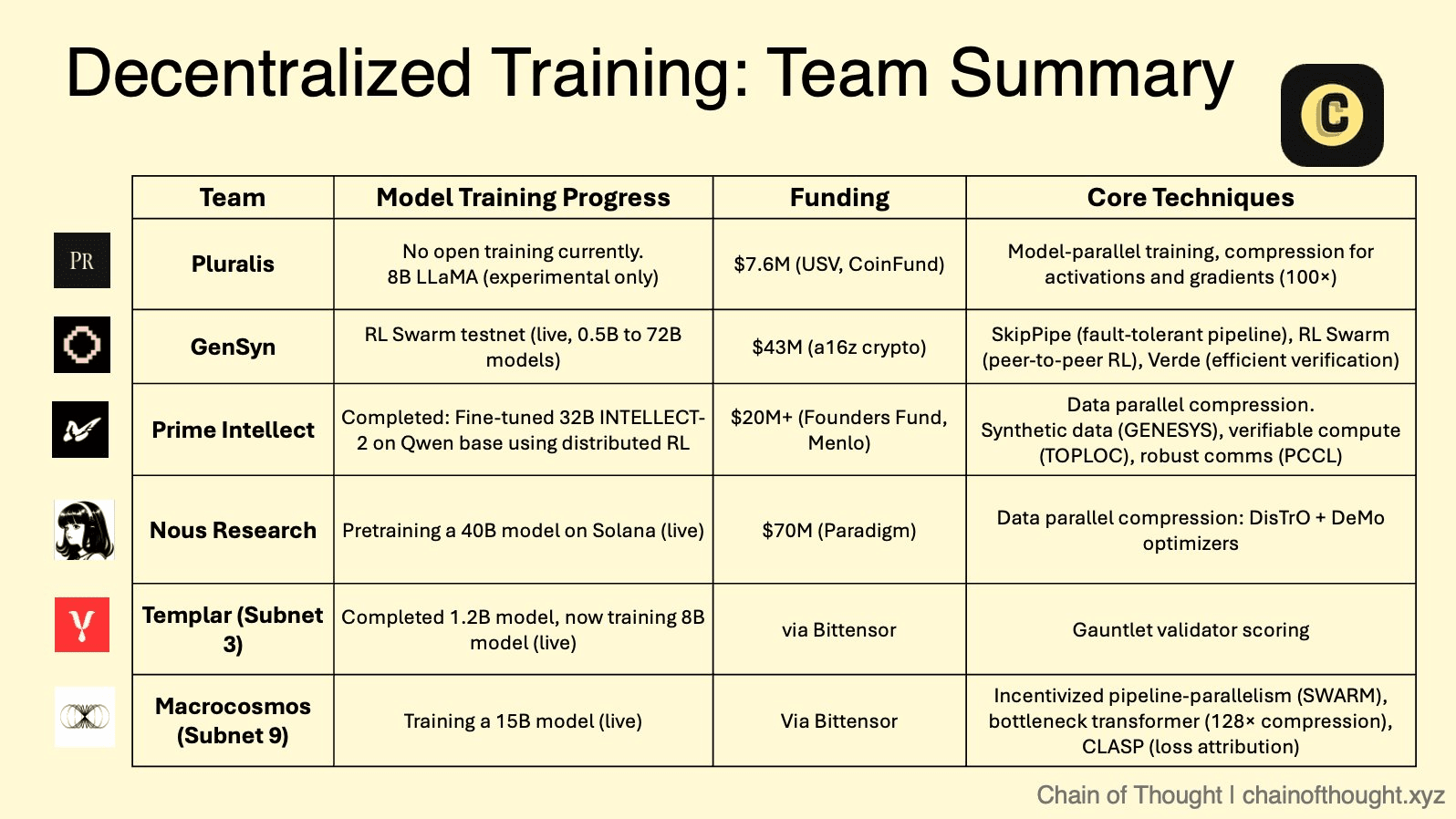
❍ 模塊化市場:Bittensor 的子網絡生態系統
Bittensor 作爲一個 "數字商品的互聯網" 運作,這是一個元協議,託管衆多專門的 "子網絡"。每個子網絡是一個競爭性、激勵驅動的市場,專注於特定的 AI 任務,從文本生成到蛋白質摺疊。在這個生態系統中,有兩個子網絡與去中心化訓練特別相關。

Templar(子網絡 3)專注於創建一個無需許可和抗脆弱的平臺進行去中心化預訓練。它體現了一種純粹的競爭方式,礦工訓練模型(目前最多 80 億參數,計劃向 700 億參數發展),並根據性能獲得獎勵,推動產生最佳智能的無情競賽。

宏觀宇宙(子網絡 9)代表着其 IOTA(激勵協調訓練架構)的重大演變。IOTA 超越了孤立競爭,朝着協同合作邁進。它採用了一箇中心輻射的架構,其中一個協調者在礦工網絡中協調數據和管道並行訓練。不是每個礦工訓練整個模型,而是分配特定的層來訓練一個更大的模型。這種勞動分工使集體能夠在遠超任何單一參與者能力的規模上訓練模型。驗證者執行 "影子審計" 來驗證工作,細緻的激勵系統公平地獎勵貢獻,促進了一個合作而又負責任的環境。
❍ 可驗證計算層:Gensyn 的無信任網絡
Gensyn 的主要關注點是解決這一領域中最困難的問題之一:可驗證的機器學習。其協議作爲自定義的以太坊 L2 Rollup 構建,旨在爲在不受信節點上執行的深度學習計算提供正確性的加密證明。

Gensyn 研究的一個關鍵創新是 NoLoCo(無全歸約低通信),這是一種針對分佈式訓練的新優化方法。傳統方法需要一個全局的 "全歸約" 同步步驟,這在低帶寬網絡中造成了瓶頸。NoLoCo 完全消除了這一步。相反,它使用基於八卦的協議,節點定期與單個隨機選擇的同伴平均其模型權重。這加上修改過的 Nesterov 動量優化器和激活的隨機路由,使網絡能夠高效收斂,而無需全局同步,非常適合在異構的、互聯網連接的硬件上進行訓練。Gensyn 的 RL Swarm 測試網應用演示了這一技術棧的實際應用,使得在去中心化環境中進行協作強化學習成爲可能。
❍ 全球計算聚合器:Prime Intellect 的開放框架
Prime Intellect 正在構建一個點對點協議,將全球計算資源聚合成一個統一的市場,有效地創建一個 "計算的 Airbnb"。他們的 PRIME 框架旨在實現容錯、高性能的訓練,適用於一組不可靠且全球分佈的工作者。
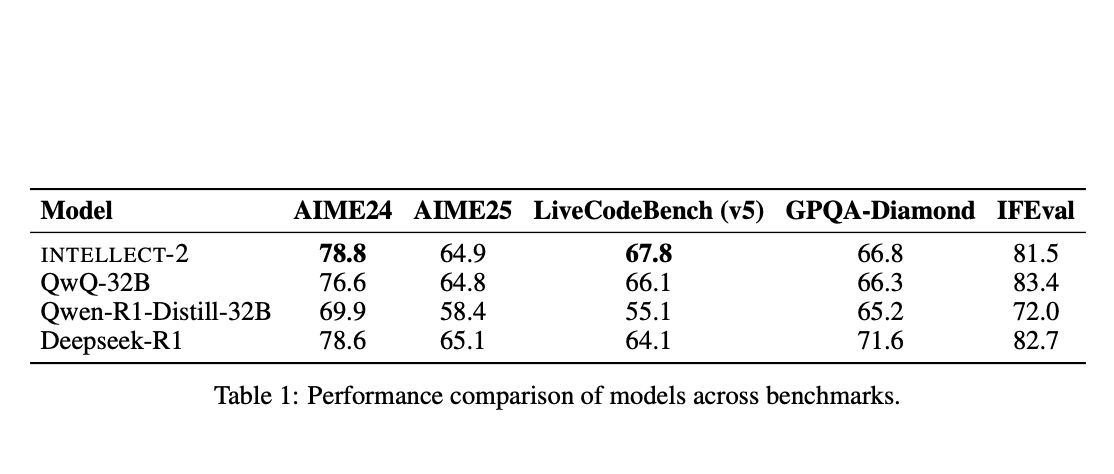
該框架基於 DiLoCo(分佈式低通信)算法的改編版本構建,該算法允許節點在需要較少的全局同步之前執行許多本地訓練步驟。Prime Intellect 在此基礎上增加了顯著的工程突破。ElasticDeviceMesh 允許節點動態加入或離開訓練運行,而不會崩潰系統。異步檢查點到 RAM 支持的文件系統最小化停機時間。最後,他們開發了自定義的 int8 全歸約內核,在同步期間將通信負載減少了四倍,從而大幅降低帶寬需求。這一強大的技術棧使他們能夠成功組織世界上第一個去中心化的 100 億參數模型訓練,INTELLECT-1。
❍ 開源集體:Nous Research 的社區驅動方法
Nous Research 作爲一個去中心化的 AI 研究集體運作,具有強烈的開源精神,基於 Solana 區塊鏈構建其基礎設施,以獲得高吞吐量和低交易成本。
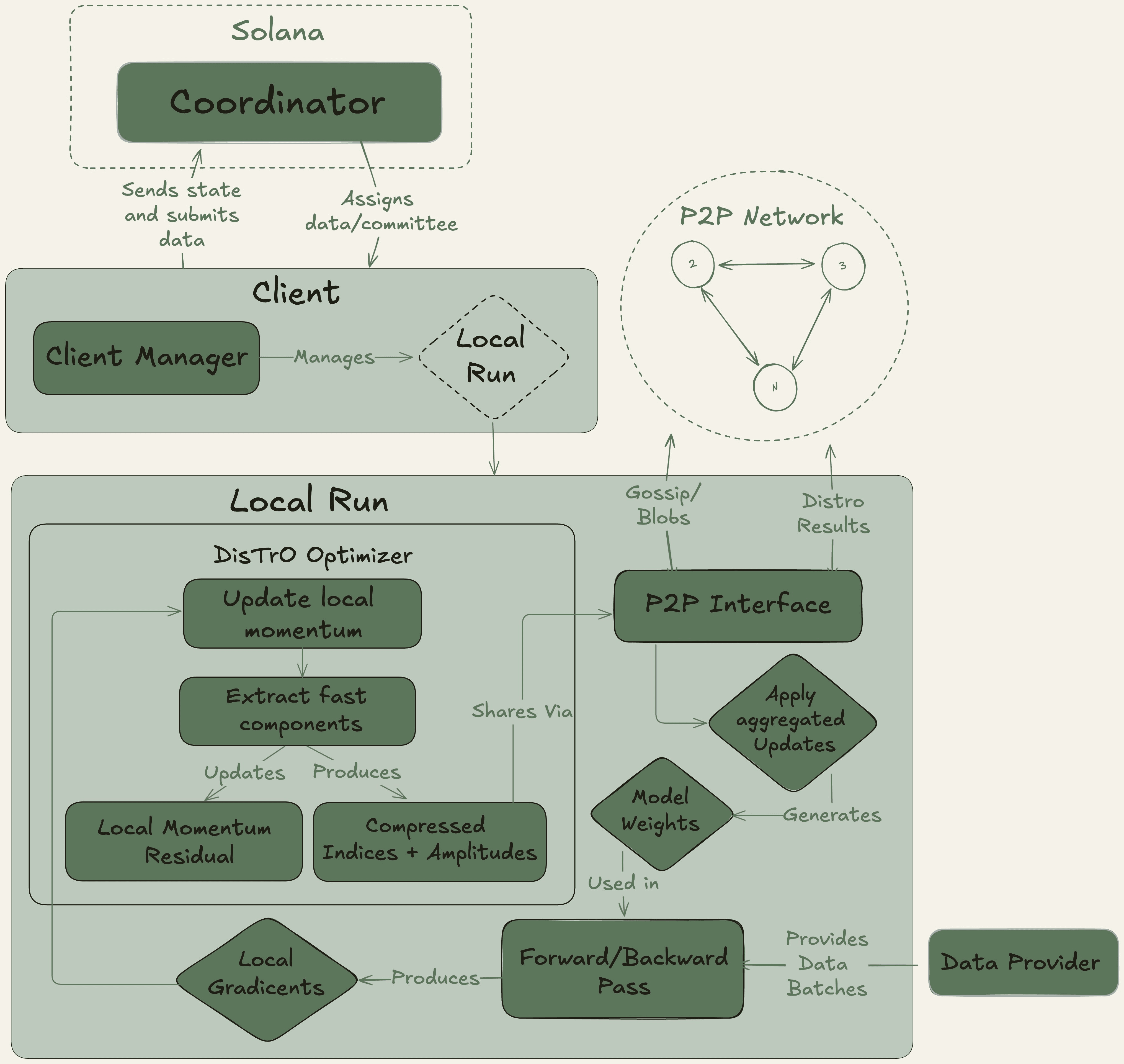
他們的旗艦平臺 Nous Psyche 是一個去中心化的訓練網絡,由兩種核心技術驅動:DisTrO(基於互聯網的分佈式訓練)及其底層優化算法 DeMo(解耦動量優化)。這些技術與 OpenAI 的聯合創始人合作開發,旨在實現極端帶寬效率,聲稱與傳統方法相比可減少 1000 倍到 10000 倍。這一突破使得使用消費級 GPU 和標準互聯網連接參與大規模模型訓練成爲可能,從而徹底實現 AI 開發的民主化。
❍ 多元未來:Pluralis AI 的協議學習
Pluralis AI 正在解決一個更高層次的挑戰:不僅是如何訓練模型,而是如何以隱私保護的方式將其與多樣和多元的人類價值觀對齊。

他們的 PluralLLM 框架引入了一種基於聯邦學習的偏好對齊方法,這一任務傳統上由集中式方法(如來自人類反饋的強化學習 RLHF)處理。通過 PluralLLM,不同用戶羣體可以在不共享其敏感的基礎偏好數據的情況下協作訓練一個偏好預測模型。該框架使用聯邦平均來聚合這些偏好更新,獲得比集中式方法更快的收斂速度和更好的對齊分數,同時保留隱私和公平性。
他們的協議學習的總體概念進一步確保沒有單一參與者可以獲得完整模型,解決了協作 AI 開發中固有的關鍵知識產權和信任問題。
儘管去中心化 AI 訓練領域展現出光明的未來,但其走向主流採用的道路充滿了重大挑戰。管理和同步數千個不可靠節點之間的計算的技術複雜性仍然是一個可怕的工程障礙。此外,缺乏明確的法律和監管框架來應對去中心化自治系統和集體擁有的知識產權,爲開發者和投資者創造了不確定性。
最終,爲了使這些網絡實現長期可行性,它們必須超越投機,吸引真實的、付費的客戶來獲取其計算服務,從而產生可持續的、協議驅動的收入。而我們相信它們最終會在我們的投機之前就跨越這條路。