
Đầu năm 2025, khi DeepSeek làm rung chuyển thị trường AI bằng mô hình chi phí thấp hơn nhiều đối thủ Mỹ, hàng loạt cổ phiếu công nghệ và token AI biến động mạnh. Trong lúc mọi người tranh luận xem AI nào sẽ thống trị tương lai, mình lại bị mắc kẹt ở một câu hỏi khác: nếu ai cũng có AI mạnh, vậy thứ gì mới thật sự khan hiếm? Mình mất khá lâu mới hiểu @OpenLedger và token $OPEN vì ban đầu nhìn vào cứ tưởng đây lại là một dự án AI + blockchain + token theo công thức quen thuộc của thị trường. Nhưng càng đọc sâu, mình càng nhận ra mình đang nhìn sai vấn đề từ đầu.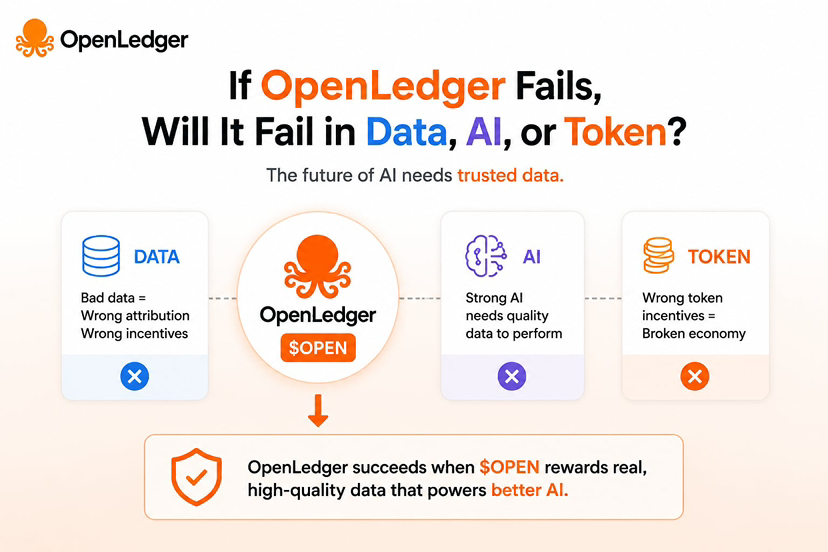
OpenLedger với token Open không thực sự cạnh tranh ở AI model. Nó đang cạnh tranh ở một thứ vô hình hơn: niềm tin dữ liệu. Nếu Ethereum bán blockspace, Solana bán tốc độ, còn Bittensor xây mạng lưới compute cho AI, thì OpenLedger đang cố xây một thị trường nơi dữ liệu được định giá dựa trên giá trị thực sự mà nó tạo ra. Nghe đơn giản, nhưng đây có thể là bài toán khó nhất trong cả ngành AI hiện nay.
Hãy tưởng tượng AI là một nhà hàng nổi tiếng. Người dùng chỉ nhìn thấy món ăn cuối cùng được mang ra bàn. Nhưng OpenLedger muốn truy ngược toàn bộ chuỗi cung ứng phía sau: nguyên liệu đến từ đâu, ai cung cấp, nguyên liệu nào tạo nên hương vị khác biệt. Token Open đóng vai trò như hệ thống thanh toán cho những người đóng góp nguyên liệu chất lượng nhất. Về mặt ý tưởng, đây là một phép ẩn dụ rất đẹp. Nhưng cũng chính là nơi rủi ro lớn nhất xuất hiện.
Nhiều người nghĩ OpenLedger sẽ thất bại nếu AI không đủ mạnh. Theo mình, đó không phải vấn đề cốt lõi. OpenAI, Google hay Anthropic đang đổ hàng chục tỷ USD vào cuộc đua mô hình. OpenLedger gần như không có lý do gì để thắng ở mặt trận đó. Điều đáng lo hơn là dữ liệu. Chính xác hơn là chất lượng dữ liệu. Internet chưa bao giờ thiếu dữ liệu. Mỗi ngày thế giới tạo ra hàng trăm triệu gigabyte dữ liệu mới. Thứ khan hiếm là dữ liệu đáng tin cậy.
Và đây là góc nhìn mình thấy ít người nói tới. Nếu cơ chế Attribution của OpenLedger và token Open xác định sai giá trị đóng góp của dữ liệu, mạng lưới có thể rơi vào thứ mình gọi là "Data Pollution Economy". Giống như một dòng sông ban đầu rất sạch. Nhưng nếu hệ thống trả thưởng như nhau cho nước sạch và nước bẩn, cuối cùng cả dòng sông sẽ bị ô nhiễm. Khi đó người dùng không còn tối ưu dữ liệu chất lượng nữa, mà tối ưu cách kiếm nhiều token $OPEN nhất.
Crypto đã từng chứng kiến chuyện này. DeFi từng bị farm thanh khoản. GameFi từng bị farm phần thưởng. OpenLedger hoàn toàn có thể đối mặt với làn sóng "farm data". Đây cũng là điểm yếu lớn nhất mà theo mình dự án cần khắc phục. Ngoài Attribution, OpenLedger cần xây thêm cơ chế đánh giá dữ liệu dựa trên hiệu quả thực tế của mô hình AI theo thời gian. Dữ liệu giúp AI tạo ra kết quả tốt hơn phải nhận nhiều $Open hơn dữ liệu chỉ đóng góp về số lượng.
Điều gây tranh cãi là có thể OpenLedger không cần trở thành nền tảng AI tốt nhất. Cũng không cần trở thành blockchain mạnh nhất. Nó chỉ cần trở thành nơi thị trường tin rằng dữ liệu chất lượng cao được trả công công bằng. Nếu làm được điều đó, token $OPEN có thể trở thành đơn vị định giá dữ liệu của nền kinh tế AI. Nếu không làm được, OpenLedger sẽ không thất bại vì AI.
Nó sẽ thất bại vì chính dữ liệu mà nó đang cố gắng biến thành tài sản.
Và đó mới là nghịch lý thú vị nhất của OpenLedger.#OpenLedger