Tôi hình dung một tương lai nơi một đội ngũ web3 nhỏ đang ngồi trong một cuộc gọi quản trị vào đêm muộn, đôi mắt mệt mỏi nhìn vào một màn hình, số liệu kho bạc trên một màn hình khác, và một đại lý AI lặng lẽ đọc hàng năm tranh luận của cộng đồng ở nền.
Rồi có người hỏi, "Bên nào trong đề xuất này có bằng chứng mạnh hơn?"
Đại lý không trả lời như một ảo thuật gia. Nó không đưa ra một đoạn văn hoàn hảo và yêu cầu mọi người tin tưởng. Nó mở ra ký ức phía sau câu trả lời. Một lưu ý rủi ro từ một chủ đề cũ trong diễn đàn. Một bảng phân bổ ngân sách từ một người đóng góp. Một mối quan tâm về hợp đồng thông minh từ một nhà phát triển. Một cảnh báo từ ai đó đã thấy một cuộc bỏ phiếu tương tự thất bại trước đó. Mỗi phần đều có dấu vết. Mỗi dấu vết đều có nguồn gốc.
Đó là phiên bản AI mà tôi muốn tin tưởng.
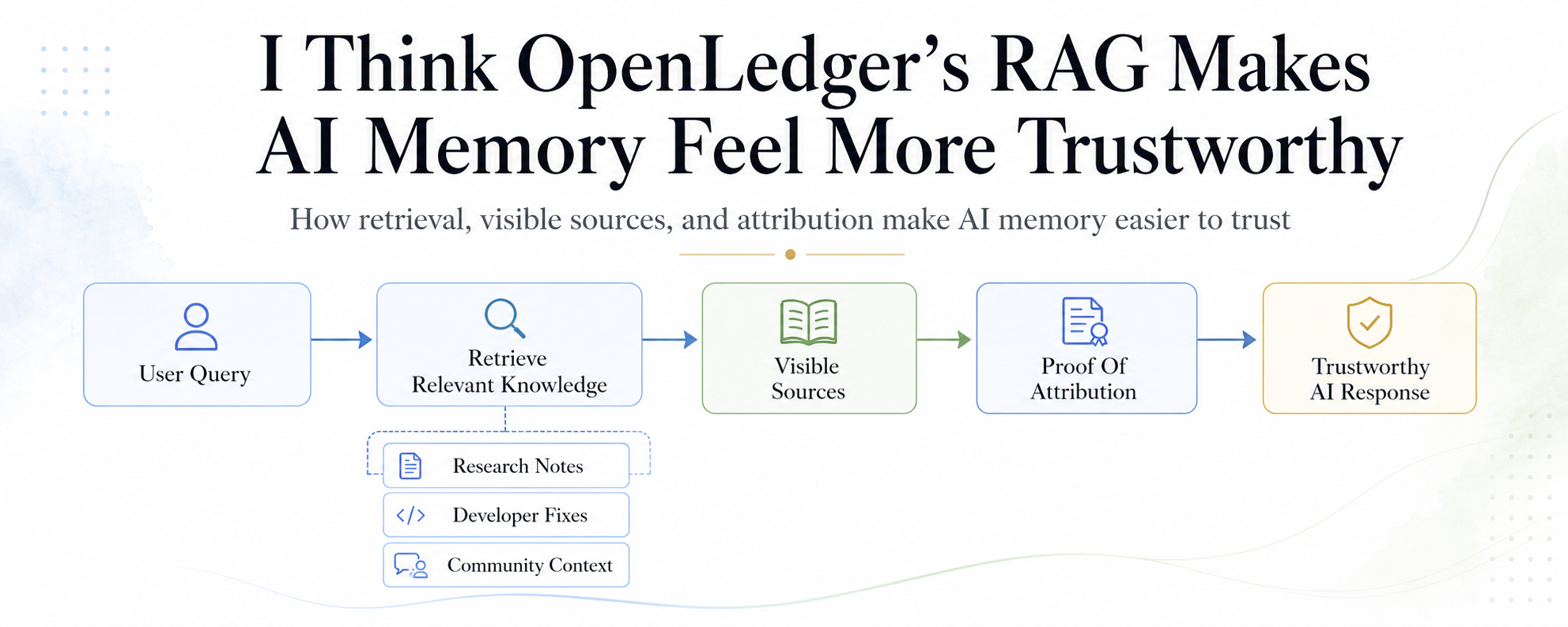
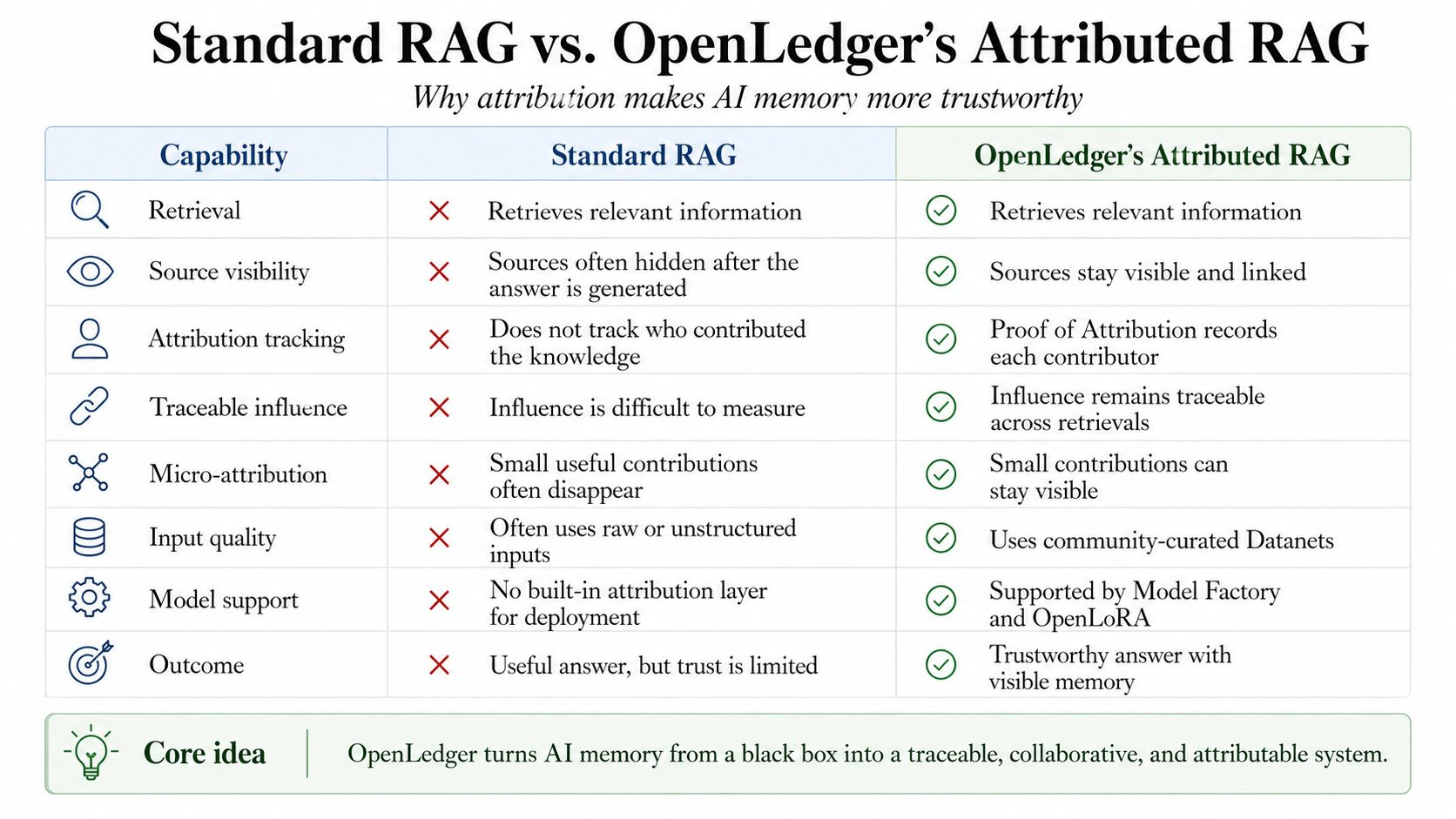
Bởi vì vấn đề lớn nhất với ký ức AI không chỉ là liệu nó có nhớ chính xác hay không. Vấn đề sâu hơn là liệu nó có nhớ một cách trung thực hay không. Rag tiêu chuẩn giúp một hệ thống AI truy xuất thông tin bên ngoài trước khi đưa ra câu trả lời. Điều đó là hữu ích. Nhưng hầu hết các hệ thống rag vẫn có một khiếm khuyết lặng lẽ. Chúng có thể sử dụng kiến thức của con người mà không giữ cho con người đó được nhìn thấy.
Tôi thấy viễn cảnh rag của \u003cm-12/\u003e khác đi. Đối với tôi, nó không chỉ là một công cụ ký ức. Nó là một cách để đưa ký ức AI trở thành của một ai đó.
Internet cũ đã cho chúng ta thấy điều gì xảy ra khi mọi người tạo ra giá trị nhưng các nền tảng lại nắm giữ bản đồ. Các nhà văn đã viết. Các cộng đồng đã giải thích. Các nhà phát triển đã chia sẻ các bản sửa lỗi. Các nhà nghiên cứu đã công bố ghi chú. Người dùng đã đào tạo hệ thống gợi ý với mỗi cú nhấp chuột và bình luận. Sau đó, giá trị đã chuyển vào các nền tảng, trong khi những người đã hình thành kiến thức thường trở thành tiếng ồn nền.
Bây giờ AI đang làm cho cùng một vấn đề trở nên sắc nét hơn.
Kiến thức con người đi vào một mô hình. Mô hình sản xuất một câu trả lời. Câu trả lời trông sạch sẽ. Nhưng phần hữu ích đến từ đâu? Ai đã giúp hình thành nó? Ai đã sửa chữa dữ liệu yếu kém? Ai nên được nhớ đến khi phản hồi trở nên có giá trị?
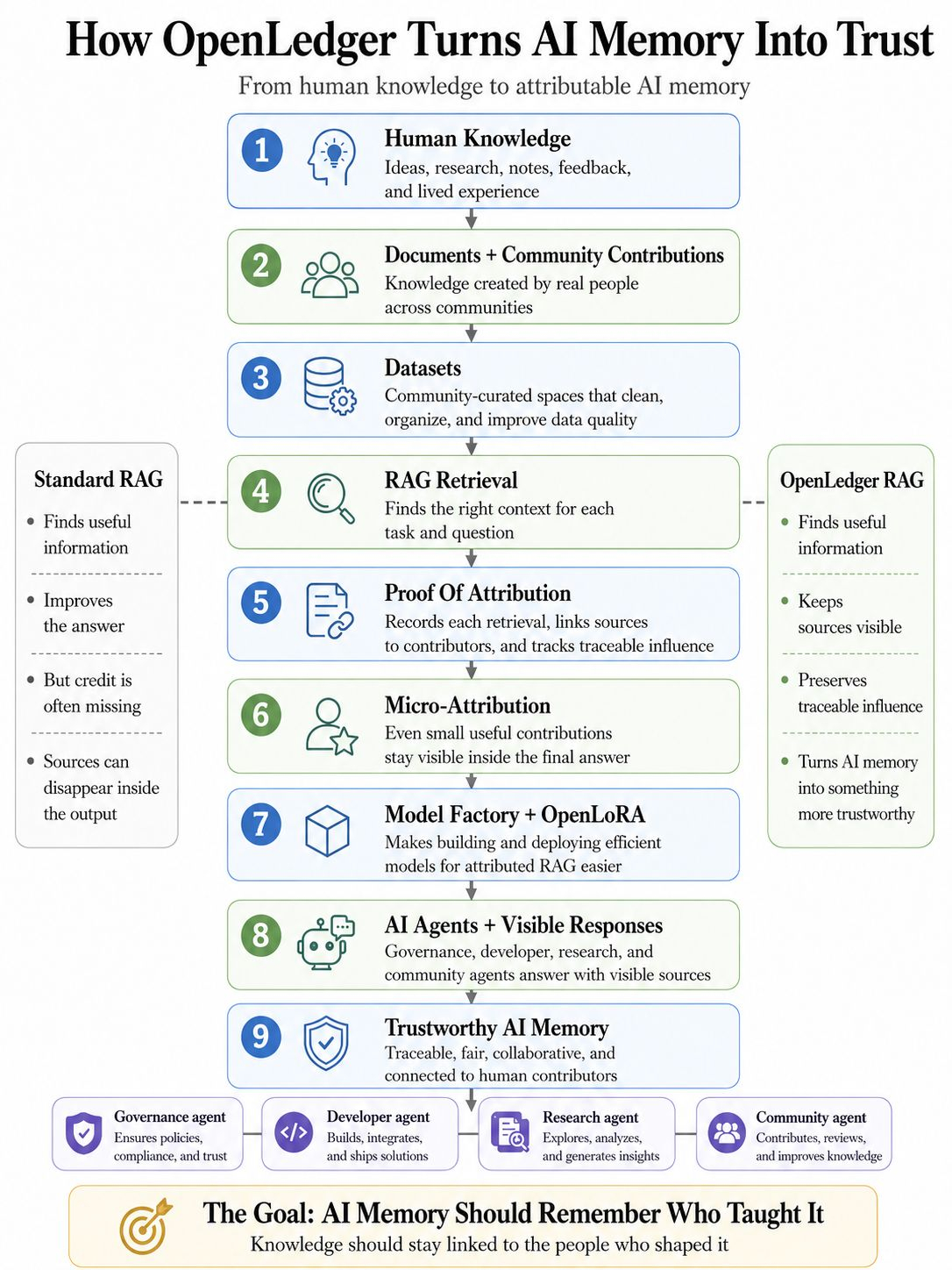
Đây là nơi bằng chứng thuộc tính trở nên quan trọng. Trong thiết kế của openledger, thuộc tính không được coi như một chú thích nhỏ sau câu trả lời. Nó trở thành một phần của chính hệ thống. Mỗi lần truy xuất có thể được ghi lại. Tài liệu có thể giữ liên kết với những người đóng góp thực sự. Ảnh hưởng có thể trở nên có thể theo dõi. Những phần nhỏ nhưng hữu ích của kiến thức có thể nhận được viêc ghi nhận nhỏ thay vì bị máy nuốt chửng.
Hãy nghĩ đến một tác nhân quản trị trong một cuộc bỏ phiếu DAO nghiêm túc.
Đề xuất này không đơn giản. Nó ảnh hưởng đến chi tiêu kho bạc, động lực tương lai và niềm tin của cộng đồng. Một tác nhân AI bình thường có thể tóm tắt tình huống một cách mượt mà, nhưng câu trả lời vẫn có thể cảm thấy lơ lửng trong không khí. Với rag có thuộc tính, tác nhân có thể chỉ ra tài liệu nào đã hình thành phần rủi ro, những người đóng góp nào đã cung cấp bối cảnh bỏ phiếu trong quá khứ, và những ghi chú nghiên cứu nào đã ảnh hưởng đến lời giải thích cuối cùng. Cuộc tranh luận trở nên ít về niềm tin mù quáng và nhiều hơn về ký ức rõ ràng.
Bây giờ hãy tưởng tượng một tác nhân phát triển giúp một nhà xây dựng sửa một vấn đề hợp đồng thông minh.
Tác nhân đọc ghi chú kiểm toán, báo cáo lỗi cũ, ví dụ đã xác minh và giải thích của người đóng góp từ datanets. Những datanets đó quan trọng vì dữ liệu thô rất lộn xộn. Các bài đăng ngẫu nhiên, tệp tin rải rác, ghi chú viết dở và bình luận lỗi thời không thể tự động trở thành ký ức tốt. Chúng cần cấu trúc. Chúng cần sự dọn dẹp của cộng đồng. Chúng cần chất lượng. Datanets biến tiếng ồn thành không gian kiến thức có tổ chức, nơi rag có thể truy xuất đầu vào tốt hơn.
Ở đây, thuộc tính thay đổi kết quả. Nhà phát triển nhận được câu trả lời, nhưng người đã viết bản sửa chữa hữu ích không biến mất. Ghi chú bảo mật vẫn còn rõ ràng. Ảnh hưởng của người đóng góp vẫn được kết nối. Tác nhân trở thành hơn một lối tắt. Nó trở thành một cầu nối giữa công việc của con người và phản hồi của máy.
Một tác nhân nghiên cứu cho thấy cùng một ý tưởng từ một khía cạnh khác.
Hãy tưởng tượng một nhà nghiên cứu đang nghiên cứu một nền kinh tế tác nhân mới. AI rút ra từ các tài liệu kỹ thuật, ghi chú quản trị, báo cáo mô hình và các giải thích do cộng đồng viết. Nếu không có thuộc tính, câu trả lời có thể nghe tự tin nhưng cảm thấy không có gốc rễ. Với bằng chứng thuộc tính, câu trả lời có thể mang theo một dấu vết ký ức. Nguồn nào đã hình thành tuyên bố? Tài liệu nào đã hỗ trợ sự so sánh? Ai đã thêm bối cảnh còn thiếu?
Có phải điều đó gần hơn với cách mà kiến thức nghiêm túc nên hoạt động không?
Sau đó có tác nhân cộng đồng, có thể là ví dụ nhân văn nhất trong tất cả.
Một thành viên cộng đồng viết một cảnh báo ngắn sau khi thử nghiệm một công cụ. Một người khác thêm một hướng dẫn đơn giản. Ai đó khác giải thích một trường hợp sử dụng địa phương bằng ngôn ngữ đơn giản. Một mình, những phần này có thể trông nhỏ bé. Bên trong một datanet được chọn lọc, chúng có thể trở thành một phần của ký ức AI trong tương lai. Thông qua viêc ghi nhận nhỏ, ngay cả một đóng góp hữu ích nhỏ cũng có thể giữ được danh tính của nó khi nó giúp một câu trả lời sau này.
Điều đó mạnh mẽ vì hầu hết mọi người không tạo ra các tập dữ liệu khổng lồ. Họ tạo ra các mảnh. Ghi chú. Sửa chữa. Ví dụ. Cảnh báo. Tầm nhìn của openledger mang lại cho những mảnh đó cơ hội tốt hơn để giữ liên kết với chủ sở hữu của chúng.
Tất nhiên, tương lai này có những thách thức thực sự.
Độ chính xác thuộc tính phải mạnh. Chất lượng dữ liệu phải được bảo vệ. Một hệ thống không nên thưởng cho tiếng ồn chỉ vì nó tồn tại. Nó nên biết sự khác biệt giữa kiến thức hữu ích, nội dung lặp lại, bối cảnh lỗi thời và đóng góp thực sự. Đó là lý do tại sao toàn bộ stack quan trọng. Datanets cải thiện đầu vào. Rag truy xuất đầu vào. Bằng chứng thuộc tính ghi lại ảnh hưởng. Nhà máy mô hình và openlora giúp cho các nhà xây dựng dễ dàng tạo ra và triển khai các mô hình có thể thực sự sử dụng ký ức được ghi nhận này.
Điểm mấu chốt không phải là làm cho AI nghe có vẻ thông minh hơn.
Điểm mấu chốt là làm cho AI có trách nhiệm hơn.
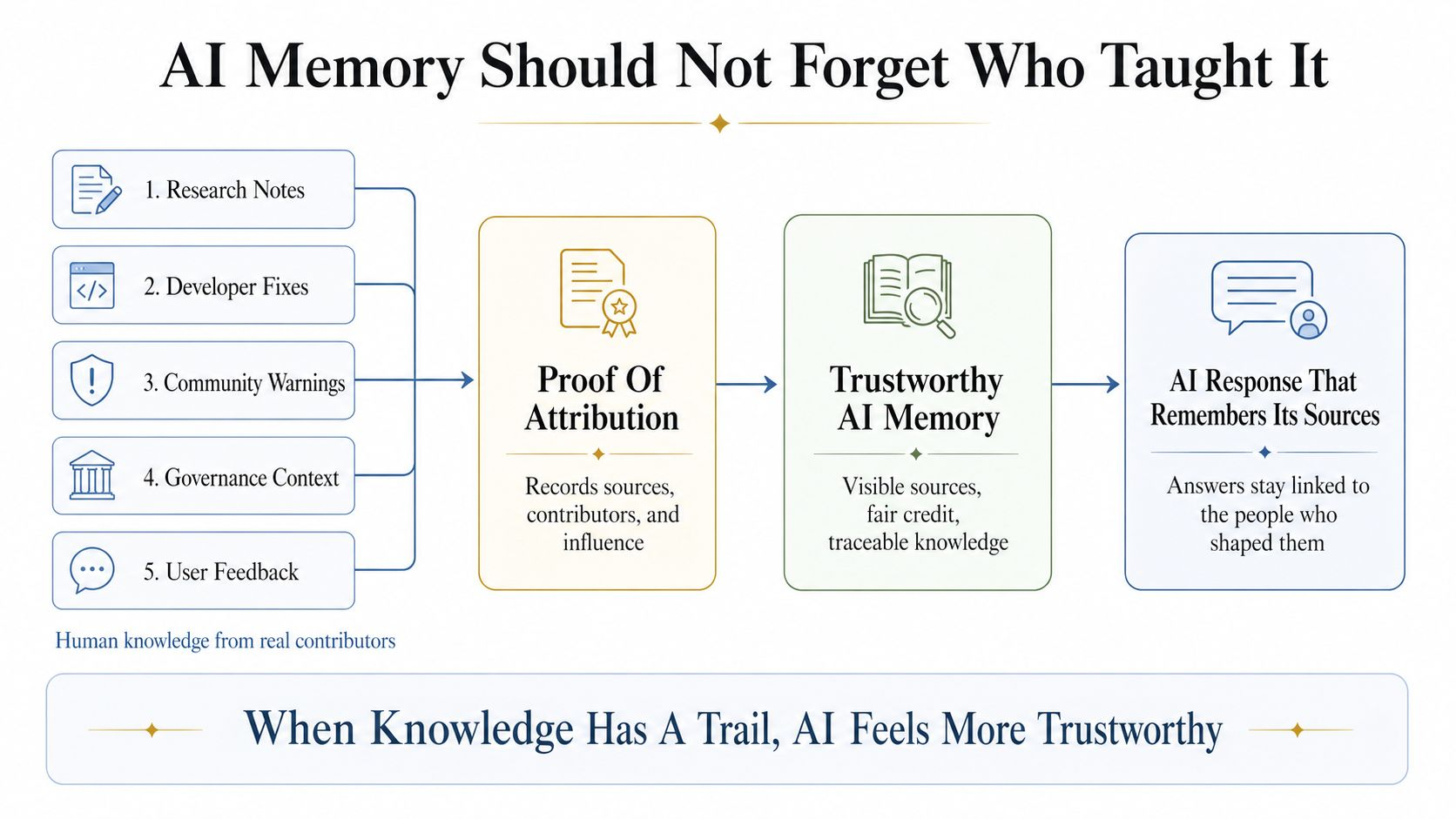
Khi tôi nhìn vào openledger qua lăng kính này, tôi không thấy rag như một tính năng backend. Tôi thấy nó như một nền kinh tế ký ức có lương tâm. Dữ liệu, mô hình và tác nhân được kết nối bởi một câu hỏi trung tâm: khi AI sử dụng kiến thức của con người, liệu kiến thức đó có thể giữ được tên của nó không?
Nếu câu trả lời là có, thì AI trở nên ít giống như một hộp đen và nhiều hơn như một bản ghi sống của công việc chung.
Có thể đó là cuộc cách mạng ẩn giấu ở đây.
Nếu AI sẽ học từ con người trên quy mô lớn, thì những người bên trong ký ức đó không nên biến mất.
\u003cc-56/\u003e \u003ct-58/\u003e