Am stat destul de mult să citesc cum vorbește OpenLedger despre transformarea categoriei tranzacțiilor într-un strat de raționare pentru mașină.
La început, ideea asta pare foarte logică.
Datele on-chain sunt prea complicate pentru oameni. O wallet trimite bani. Un contract apelează alt contract. Un vault rotește activele. Un agent execută câteva pași consecutivi. Totul trece ca un hash rece, dens, aproape imposibil de citit cu ochiul liber.
Dacă ar exista un strat de context între, care să grupeze comportamentele în categorii mai ușor de înțeles, cum ar fi alocarea capitalului, rutele de trezorerie sau mișcarea riscurilor, agentul ar părea că înțelege lumea financiară mai repede.
Dar cu cât mă gândesc mai mult, cu atât văd că punctul periculos se află în cuvântul „înțelegere”.
Dacă categorisirea tranzacției ajută doar oamenii să citească din nou datele, este foarte utilă. Dacă ajută doar agentul să reducă efortul de accesare, are un motiv de a exista. Dar dacă devine stratul principal de raționament, unde agentul privește lumea prin etichetele contabile stabilite de oameni, atunci nu mai este o rampă de lansare.
Poate deveni o cușcă cognitivă.
Problema nu este că blockchain-ul este prea zgomotos. Problema este zgomotul pentru cine.
Cu oamenii, un call trace, schimbare de stare, pattern de gas, timing și relații de adresă sunt foarte greu de citit. Dar cu un model de învățare automată, aceste lucruri nu sunt neapărat gunoi. Ele pot fi semnale. Chiar și partea pe care oamenii o consideră haotică poate conține cele mai recente stări de risc.
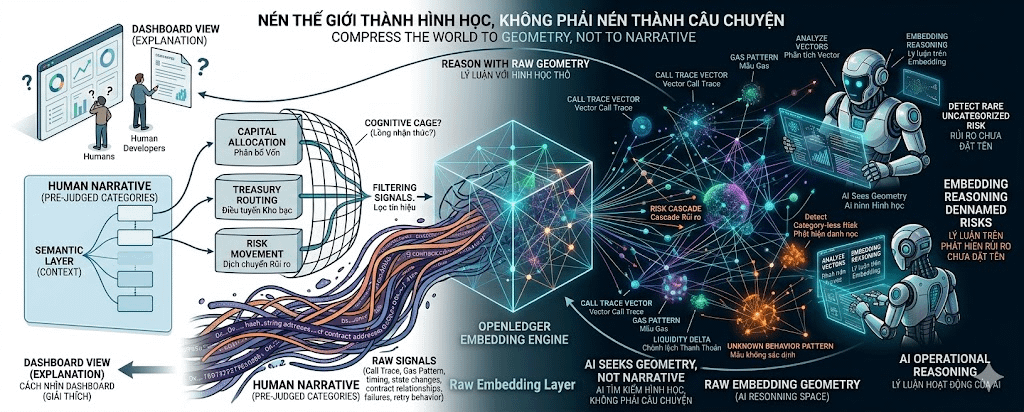
Un agent financiar puternic nu trebuie să știe doar în ce categorie se încadrează tranzacția. El trebuie să descopere stări care nu au categorie. Pattern-uri care nu au fost denumite. Moduri prin care fluxurile de bani se camuflează înainte ca oamenii să apuce să le scrie o etichetă.
Dacă forțăm totul într-o câteva etichete precum rutare de trezorerie sau alocare de capital prea devreme, filtrăm informația înainte ca AI-ul să apuce să vadă structura reală.
Dar a spune „lasă AI-ul să citească raw data direct” nu este realist.
Raw call trace este foarte scump. Schimbarea de stare este foarte grea. Un agent care rulează în timp real nu poate să parseze milioane de blocuri de fiecare dată când ia o decizie, să reconstruiască graficul portofelului, să creeze embedding de la zero și apoi să acționeze. Dacă ar fi așa, sistemul s-ar bloca din cauza latenței și costului de calcul înainte de a deveni inteligent.
Așadar, problema nu este dacă ar trebui să comprimăm datele sau nu.
Problema este cum să comprimăm în ce formă.
Dacă comprimăm comportamentul raw on-chain într-o etichetă de citit de oameni, obținem un dashboard mai frumos. Dar dacă agentul folosește chiar acea etichetă ca input de decizie, va fi prins în modul în care oamenii înțeleg finanțele de ieri.
Ce ar trebui să prioritizeze OpenLedger nu este un strat de etichete contabile pentru mașini.
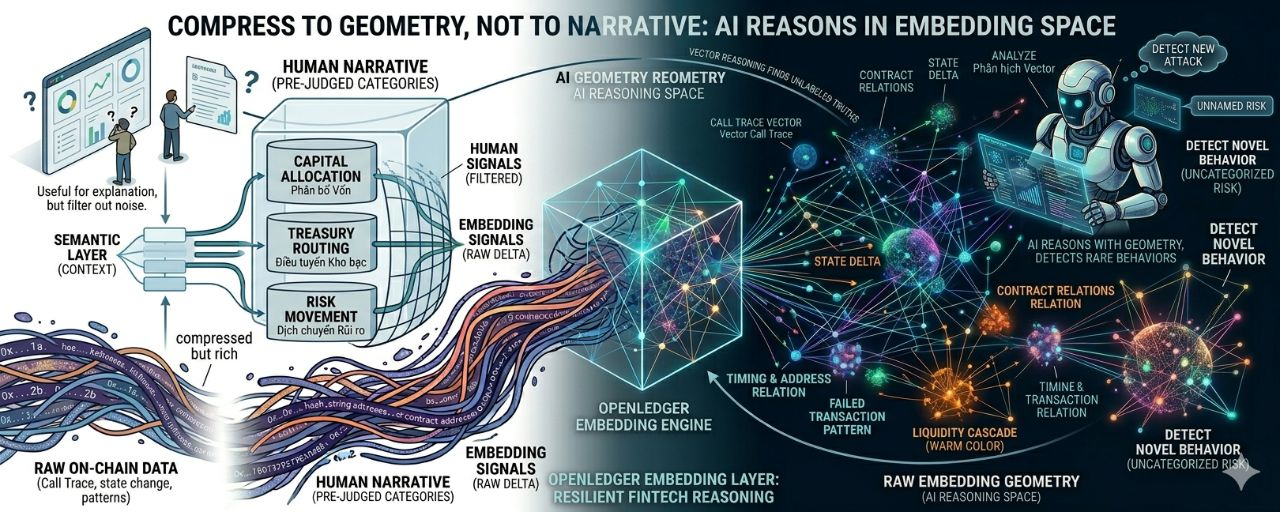
Ci un raw embedding layer.
Adică, raw data este încă comprimată, dar nu este tradusă prea devreme în categorii sărace în informații. Call trace, pattern de gas, mișcare de lichiditate, delta de stare, calea contractului, tranzacție eșuată, comportament de reîncercare și relația de adresă pot fi transformate în spații embedding bogate în structură. Oamenii care se uită la ele pot să nu înțeleagă imediat, dar agentul poate vedea distanțe, clustere, anomalii, corelații și riscuri pe care etichetele nu le pot cuprinde.
Cu alte cuvinte: nu comprima lumea într-o poveste pentru oameni, apoi obligă AI-ul să creadă acea poveste.
Să comprimăm lumea în geometrie pentru mașini.
Aceasta este limita importantă pentru OpenLedger.
Nu cred că OpenLedger greșește când vrea să facă datele on-chain mai ușor de folosit pentru AI. Dimpotrivă, dacă OpenLedger cu MCP și stratul de context poate reduce costul de accesare, standardiza fluxul de date și conduce agentul către zona corectă de informații mai repede, atunci este o piesă foarte valoroasă. Nimeni nu vrea ca un agent financiar să trebuiască să mineze din blocul genesis de fiecare dată când ia o decizie.
Dar stratul de context nu ar trebui să devină ochii agentului.
Ar trebui să fie un rutier și un interpret.
Ajută agentul să găsească mai repede zona corectă de date. Ajută oamenii să citească din nou deciziile într-un limbaj mai ușor de înțeles. Dar raționamentul de bază al agentului nu ar trebui să fie blocat în categoriile contabile statice.
Pentru că în DeFi, etichetele îmbătrânesc întotdeauna mai repede decât comportamentul.
O tranzacție care încarcă active într-un vault poate fi optimizare a randamentului. Poate fi și risc de leverage. Poate fi expunere la guvernanță. Poate fi și germenul unei cascade care nu a avut loc. Dacă sistemul o forțează într-o categorie prea devreme, raționamentul de deasupra va fi distorsionat. Nu pentru că eticheta este complet greșită. Ci pentru că eticheta este prea corectă prea puțin.
Acesta este și locul unde stratul semantic poate deveni o suprafață de atac.
Când eticheta devine semnal de rutare pentru agent, atacatorii nu vor ataca doar contractul. Ei pot ataca semnificația. Pot face ca comportamentele dăunătoare să pară rutare de trezorerie, reducerea riscurilor sau optimizarea lichidității. Dacă agentul crede în etichete mai mult decât în structura brută de bază, a pierdut cel mai important lucru în finanțele on-chain: scepticismul matematic.
Așadar, procesul corect ar trebui să meargă invers.
Agentul vede prin raw embedding și semnale brute care au fost comprimate corect. Apoi, când este nevoie de audit, raportare sau confirmare, stratul semantic traduce acea decizie într-un limbaj pe care oamenii îl pot înțelege.
AI-ul vede prin vectori.
Oamenii citesc prin etichete.
Nu inversa ordinea asta.
Întrebarea finală nu este dacă OpenLedger poate face tranzacțiile mai ușor de înțeles. Întrebarea reală este: stratul de context al OpenLedger va ajuta AI-ul să vadă mai bine finanțele on-chain, sau va obliga AI-ul să poarte ochelarii contabile ai oamenilor și să numească asta raționament?