Normalmente, eu não me interesso por projetos que se posicionam como "resolvendo a propriedade dos dados de IA". Não porque o problema não seja real, mas porque a narrativa já foi reutilizada tantas vezes que começa a se confundir com o ruído de fundo. Cada ciclo traz uma nova tentativa de "reestruturar os dados", "redefinir a propriedade" ou "liberar o fluxo de valor da IA", e a maioria delas colapsa sob o mesmo peso: superestimam o quanto o mercado se importa com a justiça quando a velocidade é a única coisa sendo precificada.
Então, quando eu encontrei a OpenLedger pela primeira vez, a reação não foi curiosidade. Foi hesitação. Não do tipo cético que fecha as coisas imediatamente—mas do tipo cansado. O tipo moldado por assistir a muitas estruturas promissoras se dissolverem em painéis que ninguém usa.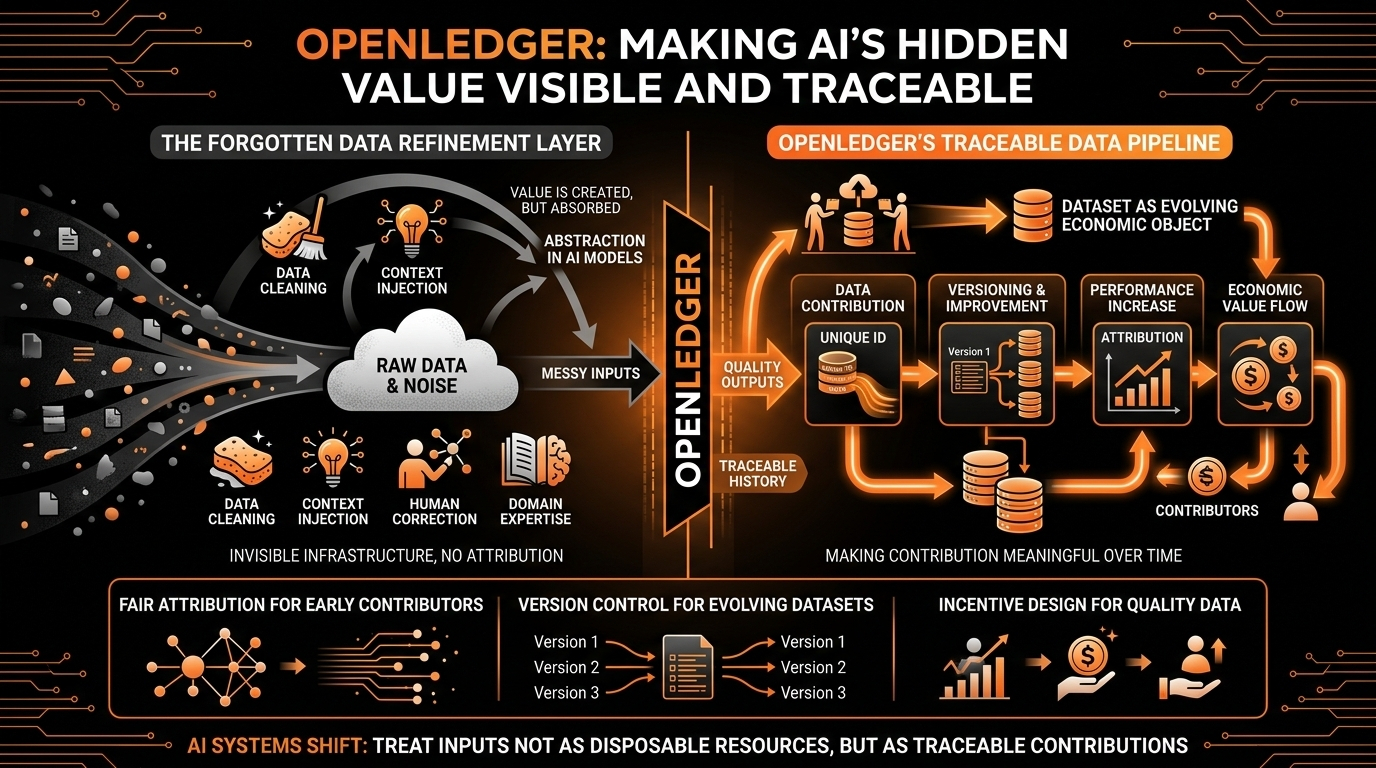
Mas a ideia não saiu facilmente, e isso geralmente significa que há algo sob a superfície que vale a pena desvendar.
A maioria das pessoas vê a IA como um produto finalizado: um modelo, um agente, uma interface, uma resposta. O que é ignorado é tudo que torna essa saída possível. Limpeza de dados, injeção de contexto, correção humana, expertise no domínio, ciclos de feedback e tratamento de casos extremos. O trabalho lento e sem glamour de transformar ruído bruto em algo que se comporta como inteligência.
Essa camada não aparece em demonstrações. Não tende em linhas do tempo. Não é embalada em decks para investidores da mesma forma que os modelos. Mas sem ela, o sistema não funciona.
E é aqui que o padrão começa a parecer familiar—especialmente se você passou algum tempo ao redor do cripto também. Em sistemas de IA e cripto, sempre há um grupo oculto de contribuidores que fazem o trabalho fundamental. Eles são usuários iniciais, testadores iniciais, provedores de dados iniciais, construtores de comunidade iniciais. Eles criam valor muito antes que o valor se torne visível. E então, uma vez que o sistema amadurece, eles geralmente desaparecem do mapa de valor—não porque deixem de existir, mas porque o sistema para de rastreá-los.
Eu vi essa dinâmica se repetir tantas vezes que quase parece estrutural ao invés de acidental. Um sistema cresce, os contribuidores se acumulam, o ruído é filtrado, o valor começa a se formar, e em algum lugar nessa transição a atribuição se quebra. As entradas iniciais que tornaram o sistema útil tornam-se inrastreadas. As pessoas que moldaram o comportamento do modelo, do conjunto de dados ou da rede não fazem mais parte da conversa de valor. Elas se tornam uma infraestrutura invisível.
A IA torna isso ainda mais extremo por causa de como os modelos realmente aprendem. Não há uma linha clara entre "esses dados causaram essa saída". Tudo é misturado, abstraído e distribuído estatisticamente através de bilhões de parâmetros. Então, mesmo quando a contribuição é essencial, torna-se analiticamente inconveniente de rastrear. E os sistemas tendem a evitar coisas inconvenientes.
Essa é a tensão que a OpenLedger está tentando explorar.
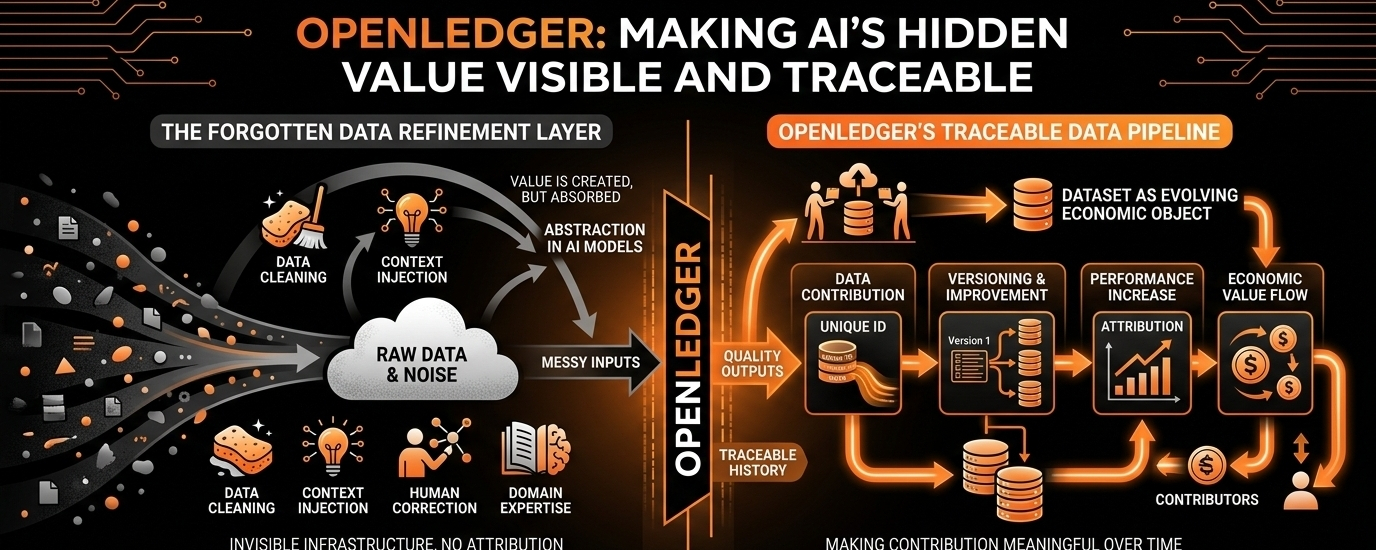
Desprovido de branding, a OpenLedger está tentando tornar a contribuição de dados rastreável e significativa ao longo do tempo. Não é apenas "você carregou um conjunto de dados", mas o que esse conjunto de dados melhorou, como ele evoluiu através das versões, quais contribuições aumentaram o desempenho e onde o valor realmente surgiu a montante. Em outras palavras, trata conjuntos de dados menos como arquivos estáticos e mais como objetos econômicos em evolução.
Essa mudança importa mais do que parece. Porque agora, a maioria dos conjuntos de dados de IA se comporta como ativos mortos. Eles são consumidos, absorvidos e esquecidos. Uma vez que entram no pipeline de treinamento, eles desaparecem em abstração. A OpenLedger está tentando tornar esse desaparecimento menos absoluto.
Há algo que a indústria raramente diz em voz alta: bons dados de IA não são limpos no início. Eles são bagunçados, incompletos, inconsistentes e muitas vezes frustrantes de trabalhar. O verdadeiro valor é criado no processo de aperfeiçoamento—quando alguém remove ruído, corrige rótulos, adiciona contexto faltante, reestrutura entradas fracas e alinha dados ao uso no mundo real. É um trabalho lento, quase invisível, e raramente é tratado como economicamente importante.
Mas se você já viu um modelo passar de "meio inútil" para "chocantemente preciso", você sabe exatamente de onde vem essa mudança. Não é a arquitetura do modelo. É a camada de qualidade dos dados. É nessa camada que a OpenLedger está focada.
Há uma razão pela qual esse tipo de conceito continua aparecendo nas discussões de IA nativa em cripto. O cripto já expôs um padrão semelhante nas finanças e redes: os primeiros contribuidores raramente recebem um upside proporcional, a menos que o sistema seja projetado para preservar a atribuição. Usuários bootstrapam liquidez, comunidades bootstrapam atenção, construtores bootstrapam ecossistemas, e então o sistema amadurece e os primeiros contribuidores muitas vezes são achatados na "história de crescimento" ao invés de participantes ativos na distribuição de valor.
A OpenLedger está basicamente aplicando essa mesma crítica aos pipelines de dados de IA, não de uma maneira filosófica, mas de uma maneira estrutural. Se os dados criam inteligência, e a inteligência cria valor, então ignorar a origem dos dados não é apenas injusto—é uma contabilidade incompleta.
O problema é que rastrear a contribuição em IA não é apenas difícil, mas também conflita com a forma como os sistemas de IA modernos são projetados. Os sistemas de IA preferem abstração à rastreabilidade, desempenho à transparência, e saída à linhagem, porque a rastreabilidade introduz atrito. E o atrito desacelera a adoção.
A OpenLedger está se movendo deliberadamente na direção oposta. Ela introduz memória em um espaço que historicamente tentou esquecer tudo, exceto o resultado final. Essa é tanto a força quanto o risco, porque uma vez que você introduz responsabilidade em um sistema otimizado para escala, você imediatamente expõe ineficiências que antes estavam ocultas.
A parte mais difícil não é a ideia—é tudo que vem depois dela. Como medir contribuição de forma justa? Como prevenir a agricultura de baixa qualidade? Como evitar jogos nos sistemas de recompensa? Como rastrear influência quando os modelos não aprendem linearmente? Como prevenir a inflação de contribuições falsas? Esses não são casos extremos; são riscos centrais do sistema.
Qualquer sistema de contribuição aberta atrai ruído. Se recompensas existem, as pessoas otimizam por recompensas. E se a otimização se torna desalinhada com a qualidade, o sistema se degrada. Então a verdadeira questão não é se a visão da OpenLedger é lógica— a ideia é clara o suficiente. É se o design de incentivos pode sobreviver ao contato com os usuários.
O que importa agora não é a teoria, mas o comportamento. A camada de revisão realmente filtra a qualidade de forma eficaz? A versionagem melhora os conjuntos de dados na prática ou apenas existe como um conceito? Os construtores realmente preferem esses conjuntos de dados em relação a alternativas? Os contribuidores permanecem porque o sistema recompensa a qualidade, não a atividade? A atribuição se traduz em algo economicamente significativo?
Porque se nada disso funcionar, não importa quão elegante a narrativa seja. Ela se torna apenas mais uma camada de abstração sobre o mesmo problema.
Se a OpenLedger tiver sucesso—mesmo que parcialmente— a mudança não parecerá dramática. Não será uma "nova era da IA". Parecerá operacional. Até chato. Conjuntos de dados mais estruturados. Melhor atribuição. Ciclos de feedback mais limpos. Fluxo de valor ligeiramente mais transparente. Uma migração lenta de construtores em direção a fontes de dados de qualidade superior.
E ao longo do tempo, uma mudança silenciosa em como os sistemas de IA tratam suas entradas—não como recursos descartáveis, mas como contribuições rastreáveis.
A maior parte do mercado de IA ainda está obcecada com o que você pode ver: modelos, agentes, interfaces, saídas, demonstrações—as coisas que se movem rapidamente e parecem impressionantes. A OpenLedger está apontando para algo menos visível, na camada onde a inteligência realmente começa a se formar, antes de se tornar algo que você pode capturar ou transformar em produto.
Essa camada sempre existiu. Ela simplesmente nunca foi devidamente rastreada, precificada ou reconhecida. Se a OpenLedger resolver isso ainda é uma pergunta em aberto. Mas o problema que ela está apontando não vai embora, e neste mercado, isso por si só é muitas vezes razão suficiente para prestar atenção.
\u003cm-29/\u003e\u003ct-30/\u003e\u003ct-31/\u003e\u003cc-32/\u003e
