
Uma coisa estranha acontece quando uma nova tecnologia ganha atenção.
Todo mundo olha primeiro para a parte emocionante.
Com IA, essa parte emocionante é fácil de ver. O modelo responde. O agente atua. A ferramenta economiza tempo. Uma tarefa que antes parecia lenta de repente se sente mais leve. Essa é a parte que as pessoas notam, e honestamente, faz sentido. É a parte que parece viva.
Mas por trás de tudo isso, há um problema muito mais sem graça.
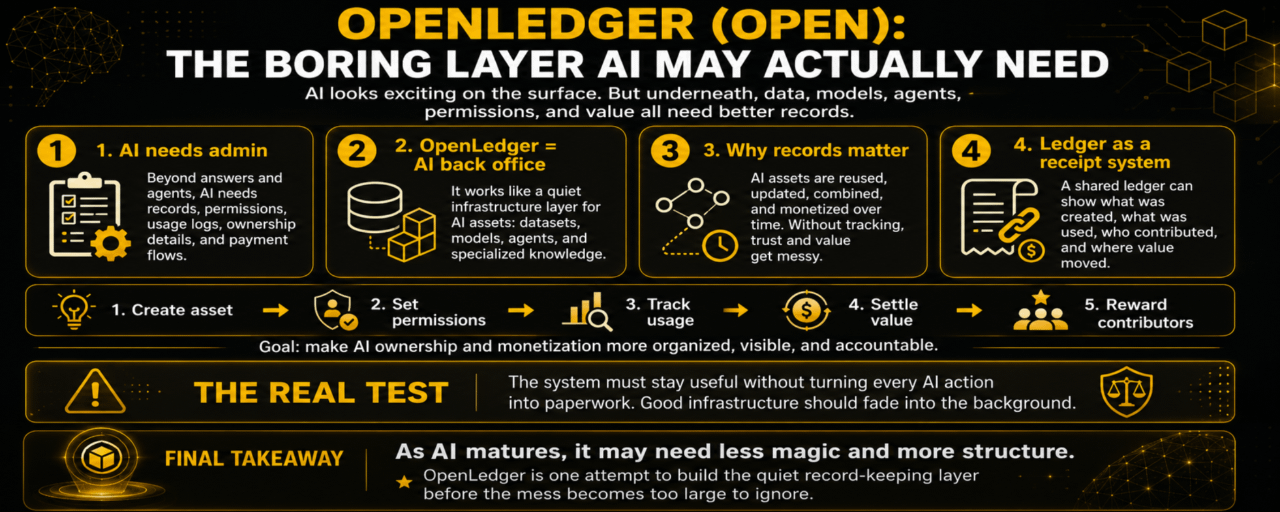
A IA precisa de administração.
Não é o tipo de administração que as pessoas gostam de discutir. Não são grandes ideias ou demonstrações chamativas. É mais como registros, permissões, logs de uso, detalhes de propriedade, fluxos de pagamento, e maneiras de saber a quem pertence o quê. Parece chato. Mas, com o tempo, você geralmente percebe que sistemas chatos são o que permitem que coisas úteis durem.
Essa é uma forma de olhar para a OpenLedger.
Não como a parte mais visível da IA. Não como a ferramenta que as pessoas tocam diretamente todo dia. Mais como o back office para uma economia de IA que ainda não existe.
E isso é importante.
Agora, a IA parece muito ativa na superfície, mas confusa por baixo. Um dataset pode ser usado em muitos lugares. Um modelo pode ser ajustado, copiado, melhorado, conectado a agentes ou envolvido em aplicações. Um agente pode realizar tarefas com base em vários modelos e muitas fontes de informação. Um usuário pode nunca saber o que realmente impulsionou o resultado.
Tudo se move, mas a papelada está faltando.
Isso pode não parecer importante no começo. Os mercados iniciais frequentemente funcionam com energia e experimentação. As pessoas constroem rapidamente. Elas compartilham coisas. Testam ideias. Avançam. Mas quando o valor real começa a aparecer, as perguntas se tornam mais sérias.
Quem tem o direito de usar esses dados?
Quem criou essa versão do modelo?
Qual agente o usou?
Com que frequência foi usado?
Quem deve receber valor desse uso?
O que acontece quando o ativo é atualizado?
Essas não são perguntas dramáticas. Elas são perguntas ordinárias. Mas perguntas ordinárias se tornam importantes quando dinheiro, propriedade e confiança estão envolvidos.
@OpenLedger parece estar tentando responder a essas perguntas para ativos de IA.
Essa frase, “ativos de IA”, pode parecer um pouco abstrata. Mas fica mais clara quando você pensa sobre o que as pessoas estão realmente construindo. Um dataset é um ativo se ajuda um modelo a ter um desempenho melhor. Um modelo é um ativo se outros podem usá-lo para criar algo útil. Um agente é um ativo se pode completar trabalho repetidamente. Até mesmo um pequeno pedaço de conhecimento especializado pode se tornar valioso se tornar um sistema de IA mais preciso.
O problema é que esses ativos não se comportam como arquivos simples.
Eles são usados.
Eles são reutilizados.
Eles são mudados.
Eles são combinados com outras coisas.
Eles podem criar valor muito tempo depois que o criador original parou de prestar atenção.
É aí que sistemas normais começam a parecer fracos.
Um marketplace básico pode mostrar o que está à venda. Uma plataforma pode hospedar um modelo. Um banco de dados pode armazenar informações. Mas ativos de IA precisam de algo mais conectado do que isso. Eles precisam de registros de atividade. Precisam de uma forma de seguir o valor enquanto se move através de diferentes camadas.
O lado blockchain da OpenLedger se torna mais fácil de entender a partir daqui.
Não é apenas sobre colocar IA na blockchain porque isso soa moderno. A ideia útil é mais prática. Um livro razão compartilhado pode agir como um sistema de recibos para trabalho de IA. Pode mostrar que algo foi criado, que foi usado, que contribuiu para um processo e que o valor se moveu por causa disso.
Recibos não são emocionantes.
Mas eles são poderosos.
Um recibo dá memória a uma ação. Diz que isso aconteceu. Diz que esse recurso esteve envolvido. Dá às pessoas algo para apontar depois. Em um pequeno projeto, talvez isso não importe muito. Em uma rede de IA maior, isso importa muito.
Porque sem registros, o valor frequentemente flui para a camada mais visível.
O app recebe atenção. A plataforma ganha usuários. O resultado final é julgado. Mas as partes mais silenciosas por baixo podem desaparecer. O dataset limpo. O modelo estreito. O módulo do agente. A pessoa que tornou o sistema mais útil de alguma forma pequena, mas importante.
#OpenLedger é interessante porque parece levar essas partes silenciosas a sério.
Não tentando torná-las glamourosas. Apenas dando-lhes um espaço no sistema.
Esse é um tipo diferente de ambição. Não está tentando fazer a IA parecer mais mágica. Está tentando tornar a IA mais organizada. E talvez isso seja o que o espaço vai precisar à medida que amadurece. Menos magia, mais estrutura.
Claro, a estrutura pode se tornar pesada se for feita de forma ruim.
Esse é um risco. Se cada interação de IA parecer gestão de papelada, as pessoas vão evitá-la. Os construtores querem ferramentas que se movam rapidamente. Os usuários querem coisas que funcionem. Os colaboradores querem recompensas, mas não querem passar todo o seu tempo pensando sobre regras técnicas. Então, a parte difícil não é apenas construir um livro razão. A parte difícil é fazer o livro razão desaparecer no fundo.
A melhor infraestrutura geralmente faz isso.
Ela mantém o rastreamento sem fazer as pessoas olharem para o rastreamento. Ela lida com a liquidação sem fazer o processo parecer lento. Ela protege a propriedade sem transformar cada ação em um debate legal.
Esse pode ser o verdadeiro teste para a OpenLedger.
Pode fazer a propriedade de IA parecer natural?
Pode fazer a monetização acontecer sem fazer a experiência do usuário parecer lotada?
Pode ajudar os construtores a conectar ativos sem forçá-los a um sistema complicado?
Essas perguntas ainda estão em aberto.
Mas o ângulo vale a pena notar porque a IA não vai permanecer simples. Mais agentes vão aparecer. Mais modelos serão construídos para casos de uso estreitos. Mais dados se tornarão valiosos porque dão à IA um julgamento melhor em áreas específicas. À medida que isso acontece, a necessidade de registros provavelmente crescerá silenciosamente no fundo.
Nem todo mundo vai se importar com essa camada.
A maioria das pessoas vai continuar olhando para a resposta na tela.
Mas em algum lugar por trás dessa resposta, haverá dados, modelos, agentes, permissões, uso e valor se movendo de um lugar para outro. Alguém precisará manter o controle disso.
A OpenLedger é uma tentativa de construir essa camada silenciosa de registro antes que a bagunça se torne grande demais para ignorar.
@OpenLedger #OpenLedger $OPEN
Artigo
OpenLedger (OPEN): A Camada Chata que a IA Pode Realmente Precisar
Aviso Legal: inclui opiniões de terceiros. Não se trata de aconselhamento financeiro. Poderá incluir conteúdos patrocinados. Consulta os Termos e Condições.