


Como disse o mestre Leonardo da Vinci uma vez, "Aprender nunca exaure a mente." Mas na era da inteligência artificial, parece que aprender pode exaurir o suprimento de poder computacional do nosso planeta. A revolução da IA, que está a caminho de injetar mais de $15,7 trilhões na economia global até 2030, é fundamentalmente construída sobre duas coisas: dados e a pura força de computação. O problema é que a escala dos modelos de IA está crescendo em um ritmo alucinante, com o poder computacional necessário para o treinamento dobrando aproximadamente a cada cinco meses. Isso criou um gargalo massivo. Um pequeno punhado de gigantes empresas de nuvem detém as chaves do reino, controlando o suprimento de GPU e criando um sistema que é caro, permissionado e, francamente, um pouco frágil para algo tão importante.
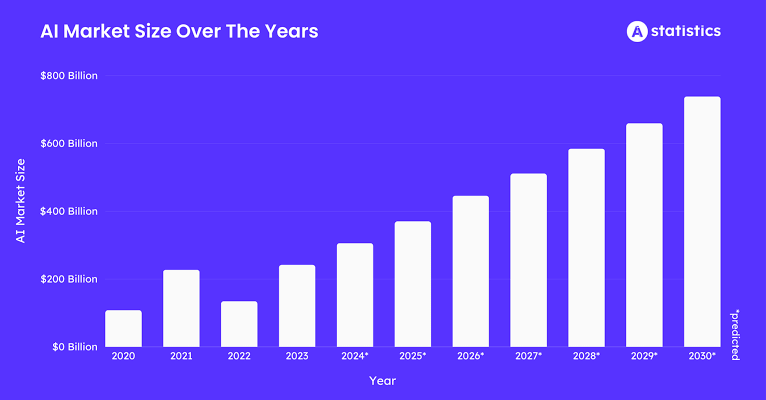
É aqui que a história fica interessante. Estamos vendo uma mudança de paradigma, uma arena emergente chamada treinamento de modelos de IA descentralizada (DeAI), que usa as ideias centrais da blockchain e do Web3 para desafiar esse controle centralizado.
Vamos olhar para os números. O mercado de dados de treinamento de IA deve atingir cerca de $3,5 bilhões até 2025, crescendo a uma taxa de cerca de 25% a cada ano. Todos esses dados precisam ser processados. O mercado de IA em Blockchain deve ter um valor de quase $681 milhões em 2025, crescendo a uma saudável CAGR de 23% a 28%. E se ampliarmos a visão para o quadro maior, todo o espaço de Infraestrutura Física Descentralizada (DePIN), do qual a DeAI faz parte, está projetado para ultrapassar $32 bilhões em 2025.
O que tudo isso significa é que a fome da IA por dados e computação está criando uma enorme demanda. O DePIN e a blockchain estão entrando para fornecer a oferta, uma rede global, aberta e economicamente inteligente para construir inteligência. Já vimos como os incentivos em tokens podem fazer com que as pessoas coordenen hardware físico como pontos de acesso sem fio e unidades de armazenamento; agora estamos aplicando esse mesmo manual ao processo de produção digital mais valioso do mundo: criar inteligência artificial.
I. O Stack DeAI
O impulso por IA descentralizada surge de uma profunda missão filosófica de construir um ecossistema de IA mais aberto, resiliente e equitativo. Trata-se de fomentar a inovação e resistir à concentração de poder que vemos hoje. Os defensores frequentemente contrastam duas maneiras de organizar o mundo: um "Taxis", que é uma ordem projetada e controlada centralmente, versus um "Cosmos", uma ordem descentralizada e emergente que cresce a partir de interações autônomas.

Uma abordagem centralizada para IA poderia criar uma espécie de "completar automaticamente a vida", onde sistemas de IA sutilmente empurram ações humanas e, escolha por escolha, desgastam nossa capacidade de pensar por nós mesmos. A descentralização é o antídoto proposto. É uma estrutura onde a IA é uma ferramenta para melhorar o florescimento humano, não para direcioná-lo. Ao espalhar o controle sobre dados, modelos e computação, a DeAI visa devolver o poder às mãos dos usuários, criadores e comunidades, garantindo que o futuro da inteligência seja algo que compartilhamos, não algo que algumas empresas possuem.
II. Deconstruindo o Stack DeAI
No fundo, você pode dividir a IA em três peças básicas: dados, computação e algoritmos. O movimento DeAI é todo sobre reconstruir cada um desses pilares sobre uma base descentralizada.
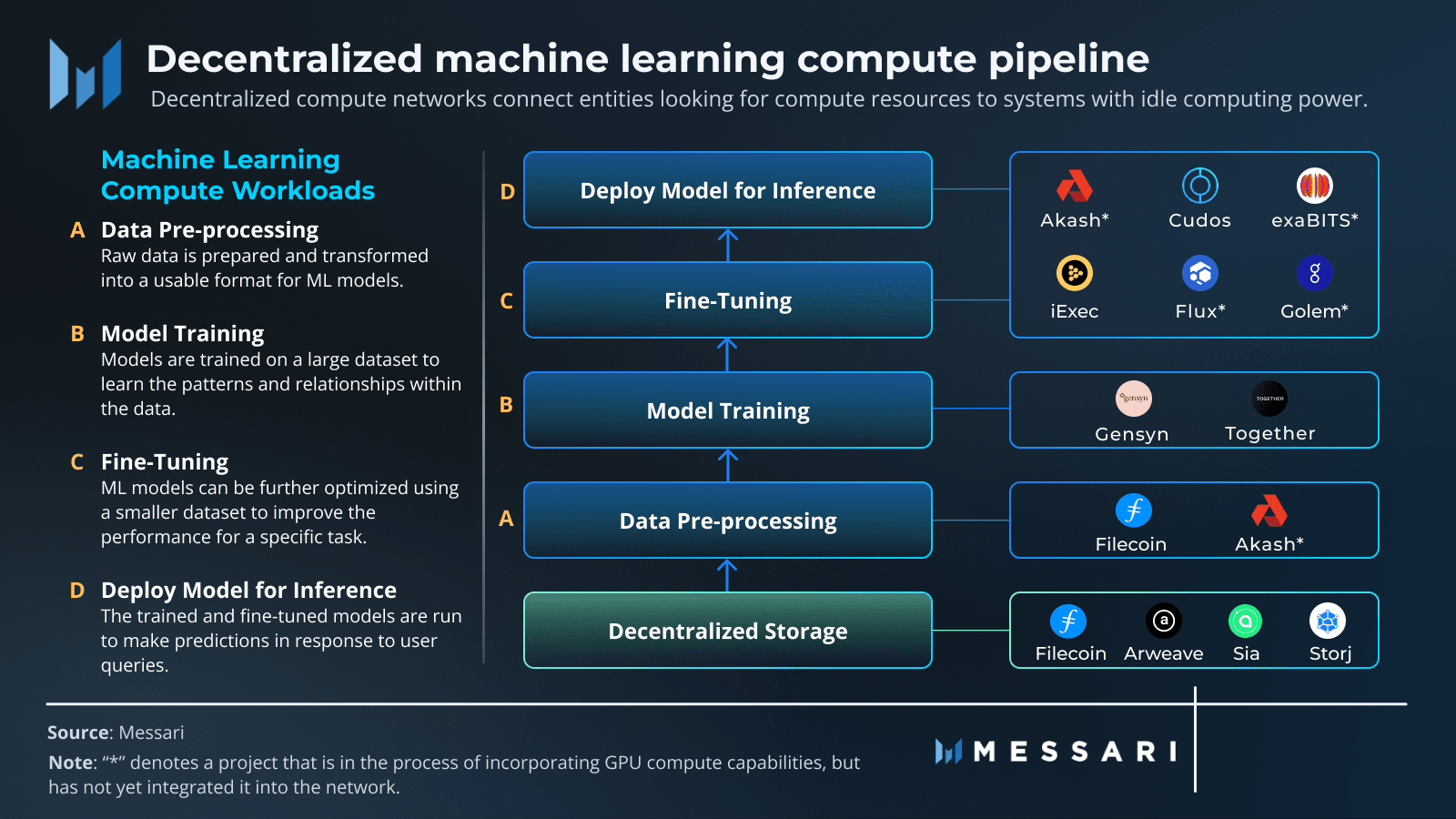
❍ Pilar 1: Dados Descentralizados
O combustível para qualquer IA poderosa é um conjunto de dados massivo e variado. No modelo antigo, esses dados ficam trancados em sistemas centralizados como Amazon Web Services ou Google Cloud. Isso cria pontos únicos de falha, riscos de censura e dificulta o acesso a novos entrantes. Redes de armazenamento descentralizadas oferecem uma alternativa, oferecendo um lar permanente, resistente à censura e verificável para dados de treinamento de IA.
Projetos como Filecoin e Arweave são jogadores-chave aqui. O Filecoin utiliza uma rede global de provedores de armazenamento, incentivando-os com tokens para armazenar dados de forma confiável. Ele utiliza provas criptográficas inteligentes como Prova de Replicação e Prova de Espaço-Tempo para garantir que os dados estejam seguros e disponíveis. O Arweave tem uma abordagem diferente: você paga uma vez, e seus dados são armazenados para sempre em uma "permaweb" imutável. Ao transformar dados em um bem público, essas redes criam uma base sólida e transparente para o desenvolvimento de IA, garantindo que os conjuntos de dados usados para treinamento sejam seguros e abertos a todos.
❍ Pilar 2: Computação Descentralizada
O maior obstáculo na IA agora é obter acesso a computação de alto desempenho, especialmente GPUs. A DeAI enfrenta isso de frente, criando protocolos que podem reunir e coordenar poder computacional de todo o mundo, desde GPUs de grau de consumidor nas casas das pessoas até máquinas ociosas em data centers. Isso transforma o poder computacional de um recurso escasso que você aluga de alguns guardiões em uma commodity líquida e global. Projetos como Prime Intellect, Gensyn e Nous Research estão construindo os mercados para essa nova economia computacional.
❍ Pilar 3: Algoritmos e Modelos Descentralizados
Obter os dados e a computação é uma coisa. O verdadeiro trabalho está em coordenar o processo de treinamento, garantindo que o trabalho seja feito corretamente e fazendo todos colaborarem em um ambiente onde você não pode necessariamente confiar em ninguém. É aqui que uma mistura de tecnologias Web3 se junta para formar o núcleo operacional da DeAI.
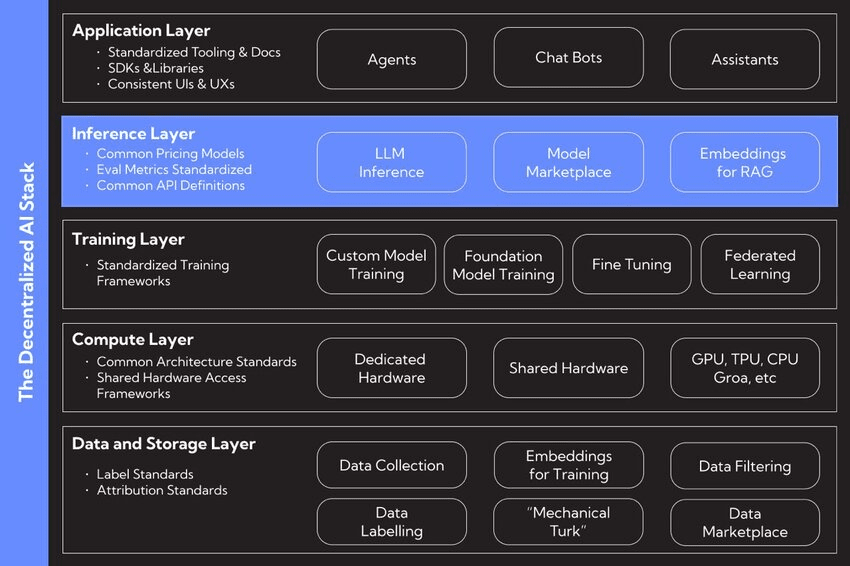
Blockchain e Contratos Inteligentes: Pense nisso como o livro de regras imutável e transparente. Blockchains fornecem um livro-razão compartilhado para rastrear quem fez o quê, e contratos inteligentes aplicam automaticamente as regras e distribuem recompensas, assim você não precisa de um intermediário.
Aprendizado Federado: Esta é uma técnica chave para preservação de privacidade. Permite que modelos de IA treinem em dados espalhados por diferentes locais sem que os dados precisem se mover. Somente as atualizações do modelo são compartilhadas, não suas informações pessoais, o que mantém os dados dos usuários privados e seguros.
Tokenomics: Este é o motor econômico. Tokens criam uma mini-economia que recompensa as pessoas por contribuir com coisas valiosas, seja dados, poder computacional ou melhorias nos modelos de IA. Isso alinha os incentivos de todos em direção ao objetivo compartilhado de construir uma IA melhor.
A beleza deste stack é sua modularidade. Um desenvolvedor de IA poderia pegar um conjunto de dados do Arweave, usar a rede do Gensyn para treinamento verificável e, em seguida, implantar o modelo finalizado em uma subnet especializada do Bittensor para ganhar dinheiro. Essa interoperabilidade transforma as peças do desenvolvimento de IA em "legos de inteligência", gerando um ecossistema muito mais dinâmico e inovador do que qualquer plataforma única e fechada poderia.
III. Como Funciona o Treinamento de Modelos Descentralizados
Imagine que o objetivo é criar um chef de IA de classe mundial. A maneira antiga e centralizada é trancar um aprendiz em uma única cozinha secreta (como a do Google) com um enorme livro de receitas secreto. A maneira descentralizada, usando uma técnica chamada Aprendizado Federado, é mais como dirigir um clube de culinária global.
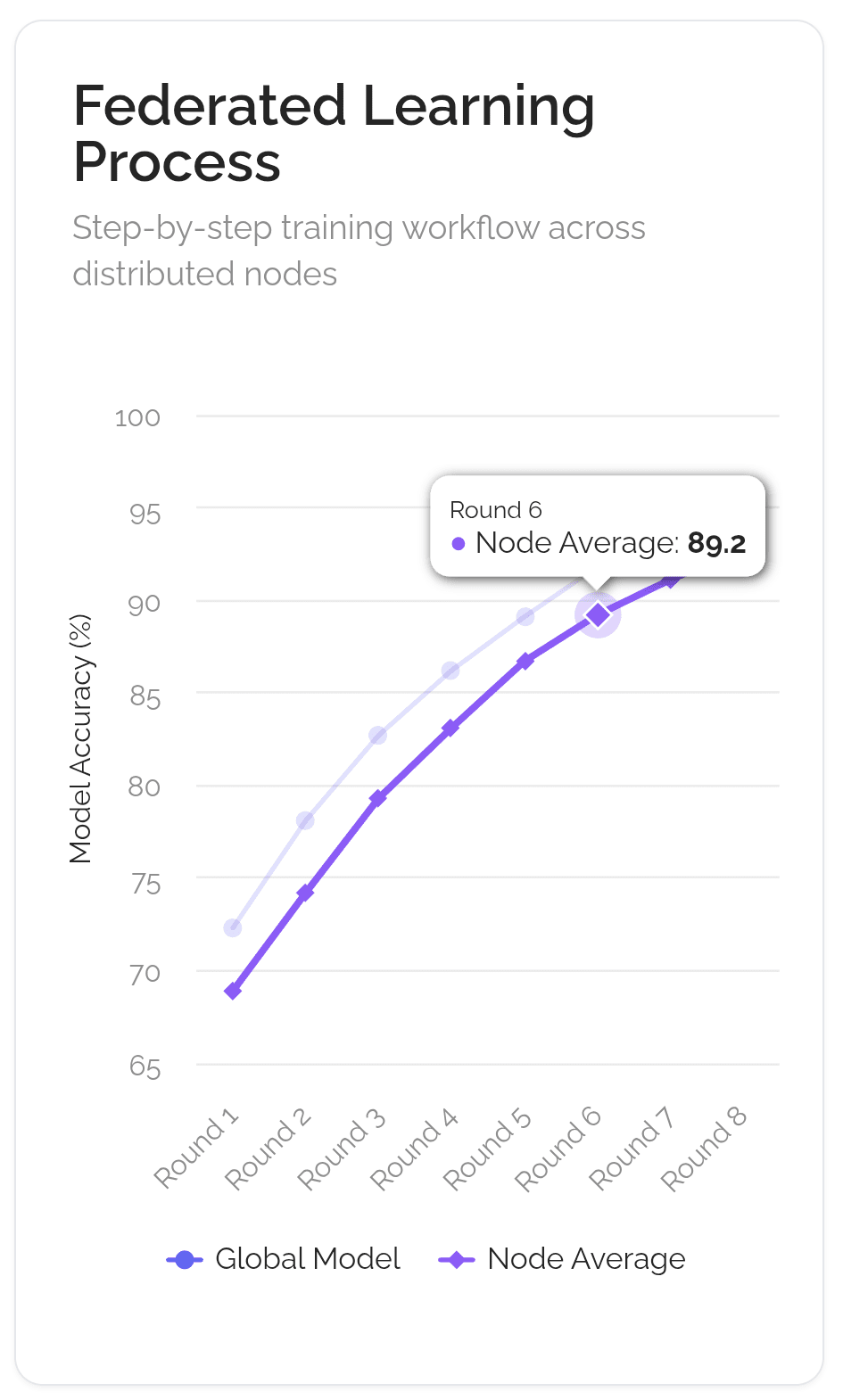
A receita principal (o "modelo global") é enviada para milhares de chefs locais em todo o mundo. Cada chef experimenta a receita em sua própria cozinha, usando seus ingredientes e métodos locais únicos ("dados locais"). Eles não compartilham seus ingredientes secretos; apenas fazem anotações sobre como melhorar a receita ("atualizações do modelo"). Essas anotações são enviadas de volta para a sede do clube. O clube então combina todas as notas para criar uma nova receita principal aprimorada, que é enviada para a próxima rodada. Todo o processo é gerenciado por um estatuto de clube transparente e automatizado (a "blockchain"), que garante que cada chef que ajuda receba crédito e seja recompensado de forma justa ("recompensas em tokens").
❍ Mecanismos-Chave
Essa analogia se alinha bastante ao fluxo de trabalho técnico que permite esse tipo de treinamento colaborativo. É uma coisa complexa, mas se resume a alguns mecanismos-chave que tornam tudo isso possível.
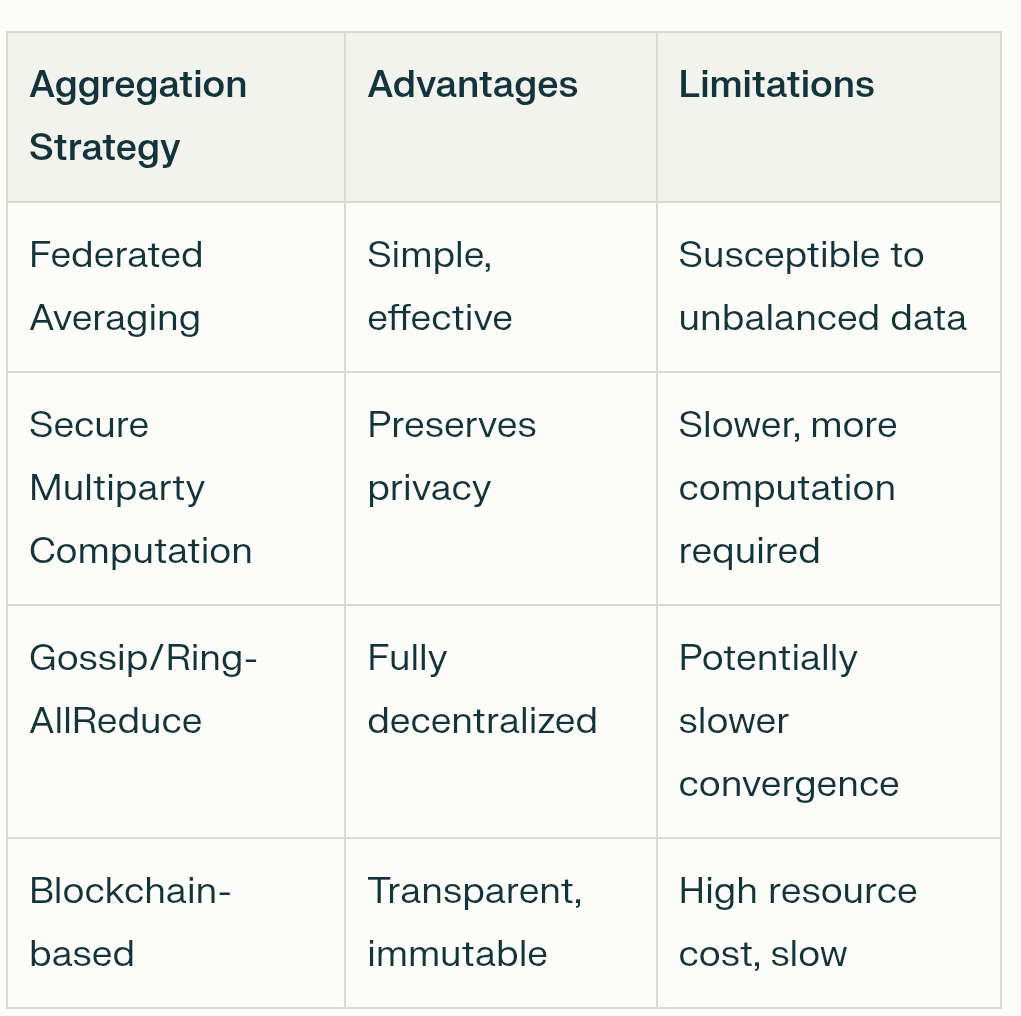
Paralelismo de Dados Distribuídos: Este é o ponto de partida. Em vez de um computador gigante processando um enorme conjunto de dados, o conjunto de dados é dividido em pedaços menores e distribuído por muitos computadores diferentes (nós) na rede. Cada um desses nós recebe uma cópia completa do modelo de IA com o qual trabalhar. Isso permite uma quantidade enorme de processamento paralelo, acelerando drasticamente as coisas. Cada nó treina sua réplica do modelo em sua fatia única de dados.
Algoritmos de Baixa Comunicação: Um grande desafio é manter todas essas réplicas do modelo sincronizadas sem entupir a internet. Se cada nó tivesse que constantemente transmitir cada pequena atualização para todos os outros nós, seria incrivelmente lento e ineficiente. É aqui que entram os algoritmos de baixa comunicação. Técnicas como DiLoCo (Comunicação Baixa Distribuída) permitem que nós realizem centenas de etapas de treinamento local por conta própria antes de precisar sincronizar seu progresso com a rede mais ampla. Métodos mais novos como NoLoCo (Comunicação Baixa Sem Todos os Redutores) vão ainda mais longe, substituindo grandes sincronizações em grupo por um método de "gossip" onde os nós simplesmente periodicamente fazem a média de suas atualizações com um único par escolhido aleatoriamente.
Compressão: Para reduzir ainda mais a carga de comunicação, as redes usam técnicas de compressão. Isso é como compactar um arquivo antes de enviá-lo por e-mail. Atualizações de modelo, que são apenas grandes listas de números, podem ser comprimidas para torná-las menores e mais rápidas de enviar. A quantização, por exemplo, reduz a precisão desses números (digamos, de um float de 32 bits para um inteiro de 8 bits), o que pode diminuir o tamanho dos dados em um fator de quatro ou mais com impacto mínimo na precisão. O pruning é outro método que remove conexões não importantes dentro do modelo, tornando-o menor e mais eficiente.
Incentivo e Validação: Em uma rede sem confiança, você precisa garantir que todos joguem limpo e sejam recompensados por seu trabalho. Essa é a função da blockchain e de sua economia de tokens. Contratos inteligentes atuam como um escrow automatizado, segurando e distribuindo recompensas em tokens para participantes que contribuem com computação ou dados úteis. Para evitar fraudes, as redes usam mecanismos de validação. Isso pode envolver validadores reexecutando aleatoriamente uma pequena parte do cálculo de um nó para verificar sua correção ou usando provas criptográficas para garantir a integridade dos resultados. Isso cria um sistema de "Prova de Inteligência" onde contribuições valiosas são recompensadas de forma verificável.
Tolerância a Falhas: Redes descentralizadas são compostas por computadores não confiáveis e globalmente distribuídos. Nós podem ficar offline a qualquer momento. O sistema precisa ser capaz de lidar com isso sem que todo o processo de treinamento trave. É aqui que entra a tolerância a falhas. Estruturas como o ElasticDeviceMesh da Prime Intellect permitem que nós entrem ou saiam de uma execução de treinamento dinamicamente sem causar uma falha em todo o sistema. Técnicas como salvamento assíncrono salvam regularmente o progresso do modelo, para que se um nó falhar, a rede possa rapidamente se recuperar do último estado salvo em vez de começar do zero.
Esse fluxo de trabalho contínuo e iterativo muda fundamentalmente o que um modelo de IA é. Ele não é mais um objeto estático criado e possuído por uma única empresa. Torna-se um sistema vivo, um estado de consenso que está constantemente sendo refinado por um coletivo global. O modelo não é um produto; é um protocolo, mantido e protegido coletivamente por sua rede.
IV. Protocolos de Treinamento Descentralizados
A estrutura teórica da IA descentralizada está sendo agora implementada por um número crescente de projetos inovadores, cada um com uma estratégia e abordagem técnica únicas. Esses protocolos criam uma arena competitiva onde diferentes modelos de colaboração, verificação e incentivação estão sendo testados em grande escala.
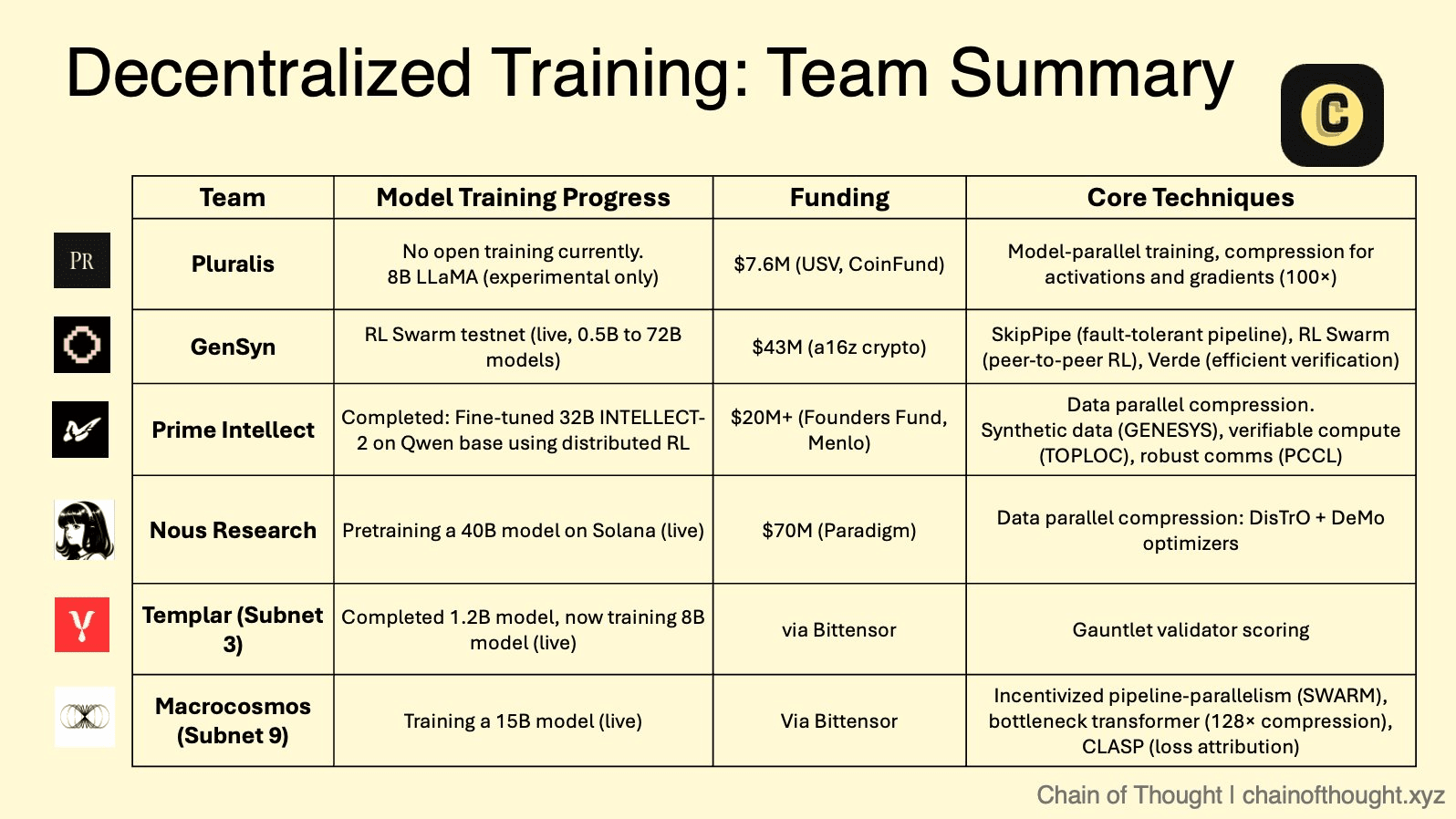
❍ O Mercado Modular: O Ecossistema de Subnets do Bittensor
Bittensor opera como uma "internet de commodities digitais", um meta-protocolo que hospeda várias "subnets" especializadas. Cada subnet é um mercado competitivo e impulsionado por incentivos para uma tarefa específica de IA, desde geração de texto até dobramento de proteínas. Dentro desse ecossistema, duas subnets são particularmente relevantes para o treinamento descentralizado.

Templar (Subnet 3) está focado em criar uma plataforma sem permissão e antifrágil para pré-treinamento descentralizado. Ele incorpora uma abordagem competitiva pura onde mineradores treinam modelos (atualmente até 8 bilhões de parâmetros, com um roteiro rumo a 70 bilhões) e são recompensados com base no desempenho, impulsionando uma corrida implacável para produzir a melhor inteligência possível.

Macrocosmos (Subnet 9) representa uma evolução significativa com sua IOTA (Arquitetura de Treinamento Orquestrado Incentivado). A IOTA vai além da competição isolada em direção à colaboração orquestrada. Ela emprega uma arquitetura de hub e spoke onde um Orquestrador coordena o treinamento em paralelo de dados e pipeline em uma rede de mineradores. Em vez de cada minerador treinar um modelo inteiro, eles são designados para camadas específicas de um modelo muito maior. Essa divisão de trabalho permite que o coletivo treine modelos em uma escala muito além da capacidade de qualquer participante único. Validador realizam "auditorias sombreadas" para verificar o trabalho, e um sistema de incentivo granular recompensa contribuições de forma justa, promovendo um ambiente colaborativo, mas responsável.
❍ A Camada de Computação Verificável: A Rede Sem Confiança do Gensyn
O foco principal do Gensyn é resolver um dos problemas mais difíceis do espaço: aprendizado de máquina verificável. Seu protocolo, construído como um Rollup L2 Ethereum personalizado, é projetado para fornecer prova criptográfica de correção para cálculos de aprendizado profundo realizados em nós não confiáveis.

Uma inovação chave da pesquisa do Gensyn é o NoLoCo (Comunicação Baixa Sem Todos os Redutores), um novo método de otimização para treinamento distribuído. Métodos tradicionais requerem um passo de sincronização global "all-reduce", que cria um gargalo, especialmente em redes de baixa largura de banda. O NoLoCo elimina completamente esse passo. Em vez disso, ele usa um protocolo baseado em gossip onde os nós periodicamente fazem a média de seus pesos de modelo com um único par selecionado aleatoriamente. Isso, combinado com um otimizador de momento de Nesterov modificado e roteamento aleatório de ativações, permite que a rede converja de forma eficiente sem sincronização global, tornando-a ideal para treinamento em hardware heterogêneo conectado à internet. A aplicação de teste do Gensyn RL Swarm demonstra esse stack em ação, permitindo o aprendizado por reforço colaborativo em um ambiente descentralizado.
❍ O Agregador Global de Computação: O Framework Aberto da Prime Intellect
Prime Intellect está construindo um protocolo peer-to-peer para agregar recursos computacionais globais em um mercado unificado, criando efetivamente um "Airbnb para computação". Sua estrutura PRIME é projetada para treinamento de alto desempenho e tolerante a falhas em uma rede de trabalhadores não confiáveis e globalmente distribuídos.
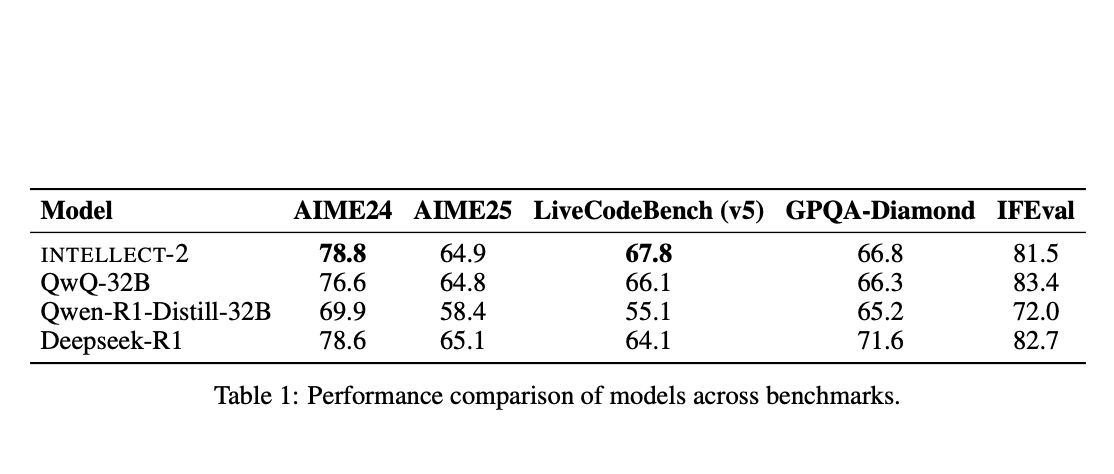
A estrutura é construída sobre uma versão adaptada do algoritmo DiLoCo (Comunicação Baixa Distribuída), que permite que os nós realizem muitos passos de treinamento local antes de precisar de uma sincronização global menos frequente. A Prime Intellect aumentou isso com avanços significativos em engenharia. O ElasticDeviceMesh permite que os nós entrem ou saiam de uma execução de treinamento dinamicamente sem travar o sistema. O salvamento assíncrono em sistemas de arquivos com suporte a RAM minimiza o tempo de inatividade. Finalmente, eles desenvolveram núcleos de redução personalizada de int8, que reduzem a carga de comunicação durante a sincronização em um fator de quatro, diminuindo drasticamente os requisitos de largura de banda. Esse robusto stack técnico permitiu que eles orquestrassem com sucesso o primeiro treinamento descentralizado do mundo de um modelo de 10 bilhões de parâmetros, INTELLECT-1.
❍ O Coletivo de Código Aberto: A Abordagem Orientada pela Comunidade da Nous Research
A Nous Research opera como um coletivo de pesquisa de IA descentralizado com uma forte ética de código aberto, construindo sua infraestrutura na blockchain Solana devido à sua alta taxa de transferência e baixos custos de transação.
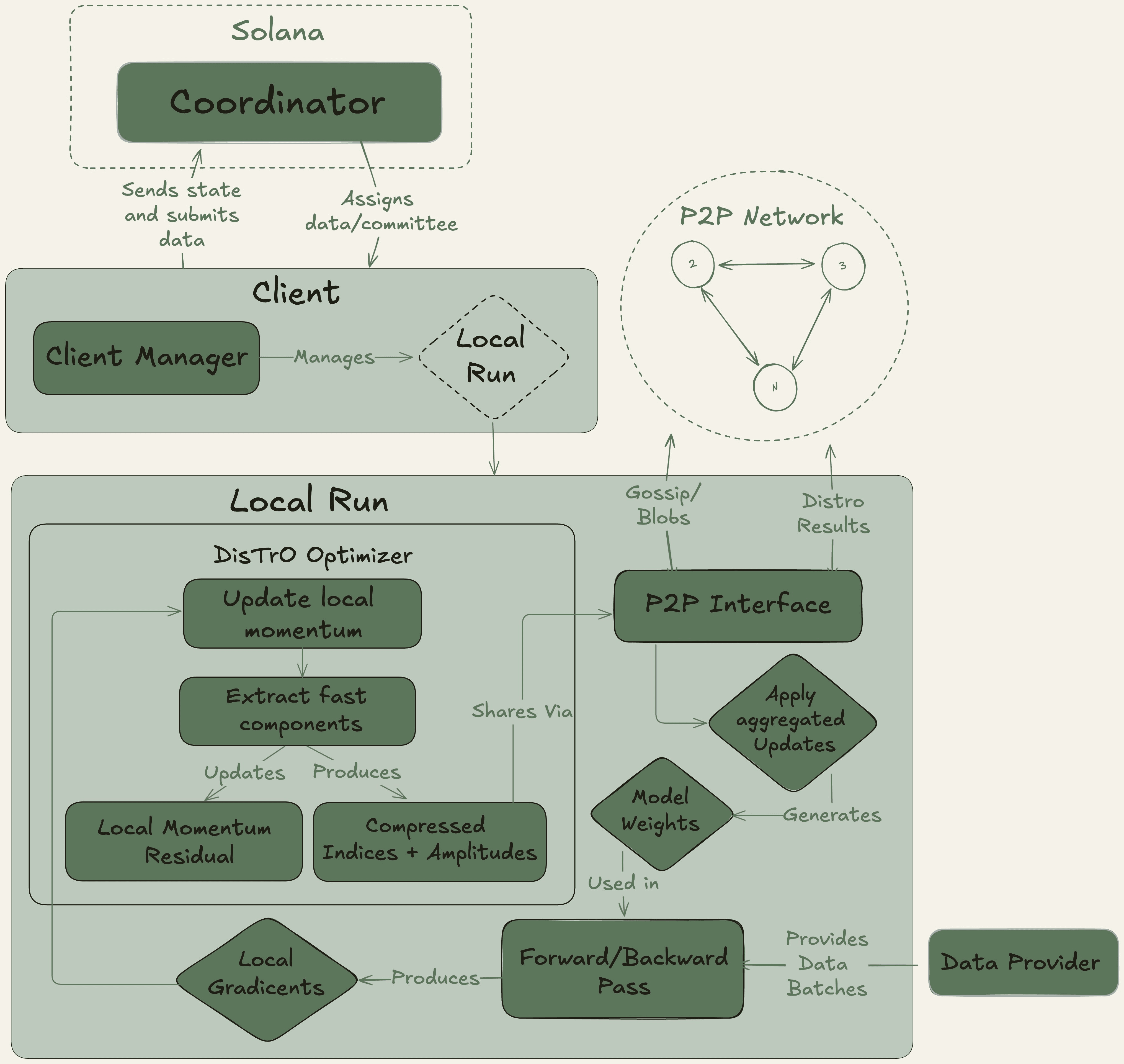
Sua plataforma principal, Nous Psyche, é uma rede de treinamento descentralizada alimentada por duas tecnologias principais: DisTrO (Treinamento Distribuído pela Internet) e seu algoritmo de otimização subjacente, DeMo (Otimização de Momento Desacoplada). Desenvolvidas em colaboração com um co-fundador da OpenAI, essas tecnologias são projetadas para eficiência extrema de largura de banda, alegando uma redução de 1.000x a 10.000x em comparação com métodos convencionais. Essa inovação torna viável a participação em treinamento de modelos em grande escala usando GPUs de grau de consumidor e conexões de internet padrão, democratizando radicalmente o acesso ao desenvolvimento de IA.
❍ O Futuro Pluralista: O Aprendizado de Protocolo da Pluralis AI
A Pluralis AI está enfrentando um desafio de nível mais alto: não apenas como treinar modelos, mas como alinhá-los com valores humanos diversos e pluralistas de maneira que preserve a privacidade.

Sua estrutura PluralLLM introduz uma abordagem baseada em aprendizado federado para alinhamento de preferências, uma tarefa tradicionalmente tratada por métodos centralizados como Aprendizado por Reforço a partir de Feedback Humano (RLHF). Com o PluralLLM, diferentes grupos de usuários podem treinar colaborativamente um modelo preditor de preferências sem nunca compartilhar seus dados subjacentes sensíveis. A estrutura usa Média Federada para agregar essas atualizações de preferências, alcançando uma convergência mais rápida e melhores pontuações de alinhamento do que métodos centralizados, enquanto preserva tanto a privacidade quanto a equidade.
Seu conceito abrangente de Aprendizado de Protocolo garante ainda mais que nenhum único participante possa obter o modelo completo, resolvendo questões críticas de propriedade intelectual e confiança inerentes ao desenvolvimento colaborativo de IA.
Embora a arena de treinamento de IA descentralizada tenha um futuro promissor, seu caminho para a adoção em massa está repleto de desafios significativos. A complexidade técnica de gerenciar e sincronizar cálculos em milhares de nós não confiáveis continua a ser um obstáculo de engenharia formidável. Além disso, a falta de estruturas legais e regulatórias claras para sistemas autônomos descentralizados e propriedade intelectual coletivamente possuída cria incerteza para desenvolvedores e investidores.
Em última análise, para que essas redes alcancem viabilidade a longo prazo, elas devem evoluir além da especulação e atrair clientes reais e pagantes para seus serviços computacionais, gerando assim receita sustentável e impulsionada por protocolo. E acreditamos que elas eventualmente cruzarão a estrada mesmo antes de nossa especulação.