

Zestaw liczb, które zapierają dech w piersiach
W marcu 2026 roku dyrektor Krajowego Biura Danych Liu Liehong na Chińskim Forum Rozwoju przedstawił zestaw liczb:
1000 miliardów → 100 bilionów → 140 bilionów
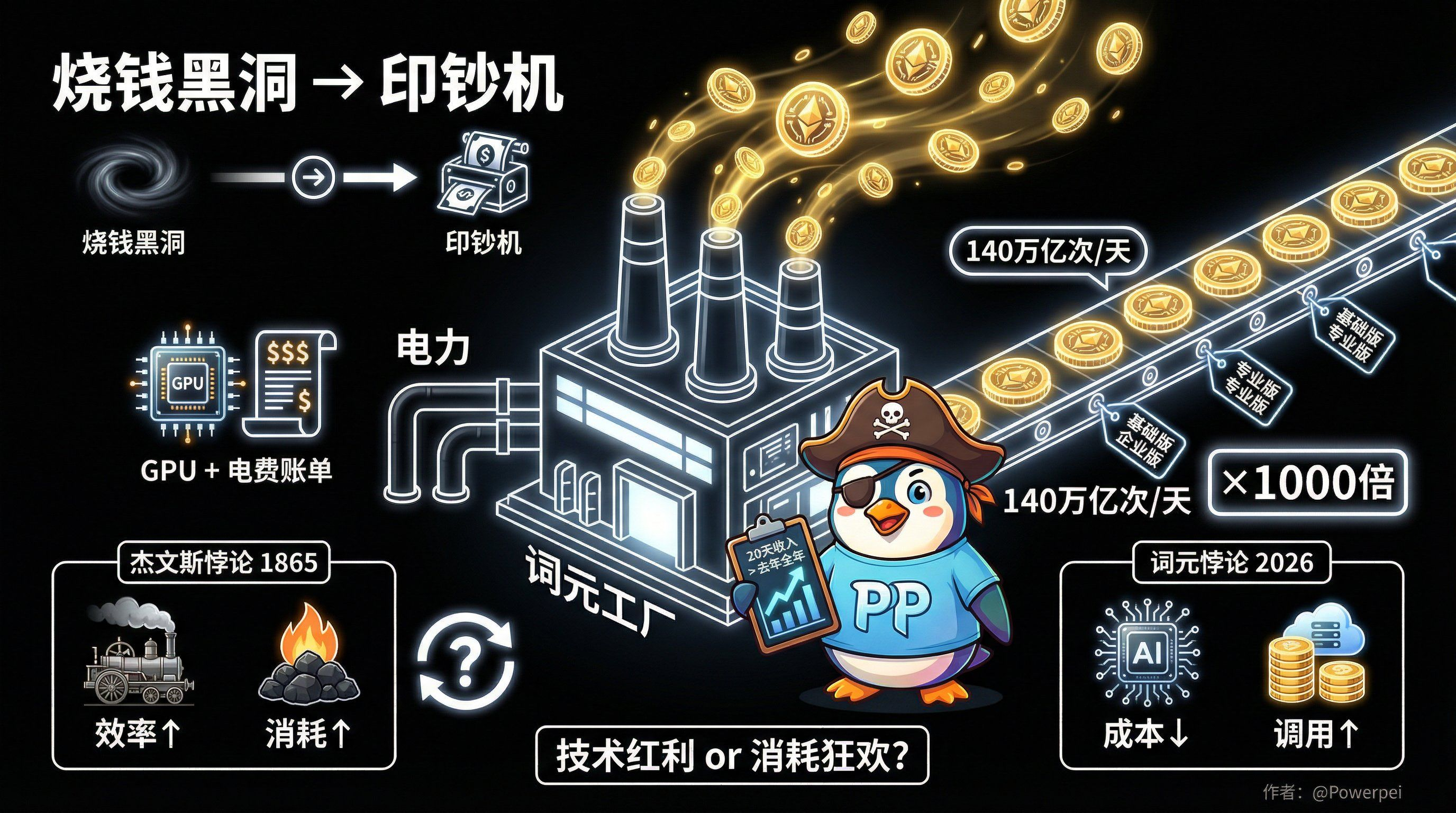
Średnie dzienne wykorzystanie tokenów w naszym kraju wzrosło ponadtysiąc razy
Co bardziej szokujące, niektóre modele firm w ciągu 20 dni przynoszą więcej dochodów niż w całym roku ubiegłym
Szczerze mówiąc, gdy po raz pierwszy zobaczyłem tę liczbę, przez kilka sekund byłem zszokowany
Nie dlatego, że wzrost był tak zdumiewający
W erze Internetu widzieliśmy zbyt wiele historii o wzroście wykładniczym
Lecz dlatego, że termin 'token' nagle przeszedł z technicznego żargonu do ekonomicznych wskaźników, które można omówić na forach na wysokim szczeblu.
Kiedy w przemówieniu szefa biura zaczyna pojawiać się jakiś termin techniczny, nie jest to już wyłącznie kwestia techniczna, lecz ekonomiczna.
Przypomina mi to okres około 2010 roku, kiedy „ruch danych” był jedynie terminem technicznym używanym wewnętrznie przez operatorów telekomunikacyjnych i dostawców internetu. Zwykli ludzie nie przejmowali się, ile MB danych zużywają każdego dnia. Jednak kilka lat później lęk przed danymi stał się tematem ogólnokrajowym, a wraz z nim pojawiły się pakiety danych, karty danych i gospodarka oparta na danych.
Teraz historia zdaje się powtarzać, tylko bohaterowie zmienili się w słowa.

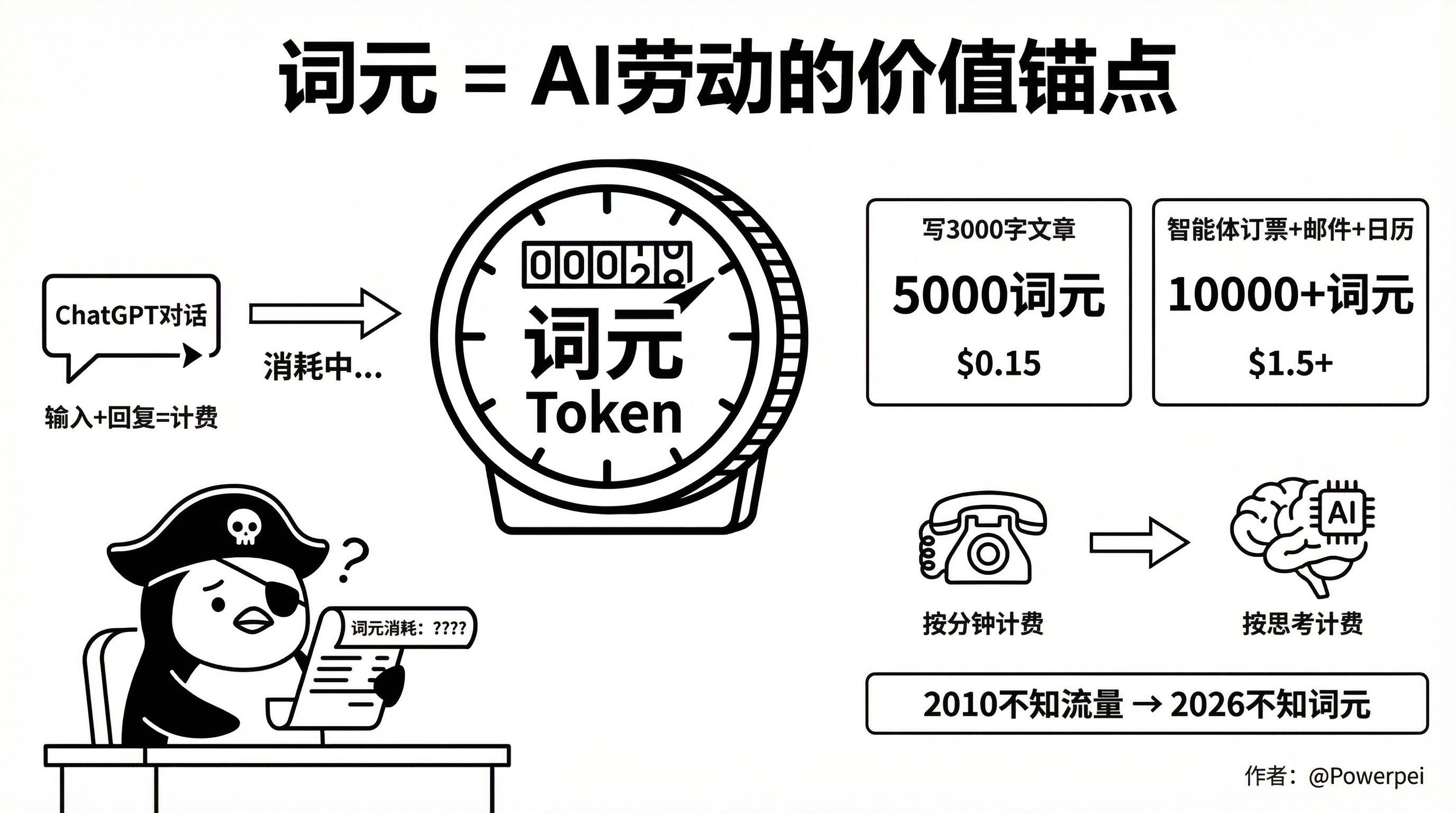
Czym właściwie jest element leksykalny?
Technicy powiedzą Ci:
Token to najmniejsza jednostka informacji przetwarzana przez duży model. Jest to dyskretny segment, który model może zrozumieć, tworzony poprzez segmentację tekstu na słowa za pomocą algorytmów segmentacji słów. Chiński znak może być tokenem, angielskie słowo może być podzielone na dwa lub trzy, a opis obrazu może pochłaniać setki tokenów.
Jednak dla większości ludzi takie wyjaśnienie nie ma sensu.
Innymi słowy: za każdym razem, gdy rozmawiasz z ChatGPT, zlecasz sztucznej inteligencji pisanie kodu, generowanie obrazu, a nawet rezerwację lotu lub organizowanie e-maili przez agenta, zużywasz tokeny w tle. Dostawcy modeli prawie zawsze pobierają opłaty za pomocą tokenów.
Koszt Twojego wkładu i koszt reakcji sztucznej inteligencji są wyraźnie wyświetlane.
Na przykład
Napisz artykuł o objętości 3000 słów, korzystając z GPT-4.
→ Zużywa około 5000 jednostek leksykalnych
→ Koszt około 0,15 USD
Pozwól agentowi AI wykonywać zadania takie jak rezerwacja lotów, pisanie e-maili i aktualizowanie kalendarza.
→ Zużycie słów z łatwością przekracza 10 000
→ Koszty wzrosły ponad 10-krotnie
To jak rozmowa telefoniczna: kiedyś naliczano opłatę za minutę, teraz sztuczna inteligencja nalicza opłatę za liczbę myśli. Tyle że proces myślowy jest wyrażany w słowach.
Pytanie brzmi: czy wiesz, ile słów wypowiadasz każdego miesiąca?
Podobnie ludzie w 2010 roku nie wiedzieli, ile danych wykorzystali.
Krajowa Administracja Danych oficjalnie nadała tokenowi nazwę „Jednostka Cenomiczna”, co nie jest jedynie kwestią tłumaczenia, ale także uznaniem jego atrybutów ekonomicznych. Jest on definiowany jako punkt odniesienia dla wartości i jednostka rozliczeniowa w erze inteligentnej. Mówiąc prościej, zapewnia on wymierny standard wyceny pracy AI.
Od czarnej dziury spalającej pieniądze do maszyny do drukowania pieniędzy
Przychody wiodącego producenta modeli w ciągu 20 dni przekroczyły jego całkowite przychody za cały poprzedni rok.
W ciągu ostatnich kilku lat usłyszeliśmy niezliczone historie o firmach zajmujących się sztuczną inteligencją, które przepalają pieniądze.
Szkolenie dużego modelu może łatwo kosztować dziesiątki milionów dolarów, zakup procesorów GPU jest tak tani jak zakup kapusty, a rachunki za prąd mogą spędzić sen z powiek dyrektorowi finansowemu.
W tamtym czasie jednostki leksykalne postrzegano częściej jako koszt: ile jednostek leksykalnych jest zużywanych w trakcie uczenia, ile jednostek leksykalnych jest zużywanych w trakcie wnioskowania i jak je zoptymalizować, aby wydać mniej pieniędzy.
Ale teraz sytuacja się zmieniła.
Gdy sztuczna inteligencja wkracza w fazę zastosowań na dużą skalę, każda rozmowa użytkownika i każde zadanie wykonywane przez inteligentnego agenta nieustannie zużywają zasoby słownictwa. Im więcej słów jest zużywanych, tym więcej sprzedają producenci.
Słowo „koszt” przekształciło się w słowo „towar”, który można produkować masowo, wyceniać w ratach i handlować nim na dużą skalę.
Fabryka leksykalna Huanga Renxuna
Podczas konferencji GTC 2026, prezes firmy Nvidia, Jensen Huang, bezpośrednio zaproponował koncepcję „metagospodarki”.
Zdefiniował na nowo centrum danych jako „fabrykę leksykalną”:
Brzmi świetnie, prawda? Ale tu pojawia się problem: czy to nie zamienia firm zajmujących się sztuczną inteligencją w „przetwornice prądu”? Ty zużywasz prąd, żeby produkować słowa, ja zużywam prąd, żeby produkować słowa, a ostatecznie toczy się rywalizacja o to, kto potrafi konwertować słowa wydajniej. Jaka jest fundamentalna różnica między tym a logiką tradycyjnej produkcji?
Paradoks Jevonsa: zwiększona wydajność ≠ zmniejszone koszty
Co ważniejsze, logika ta kryje w sobie klasyczną pułapkę ekonomiczną – paradoks Jevonsa.
W XIX wieku brytyjski inżynier Jevons odkrył, że wraz ze wzrostem sprawności silnika parowego, zużycie węgla w rzeczywistości rosło, a nie malało, ponieważ tańsza energia stymulowała większe wykorzystanie. Obecnie, znacząco niższy koszt wnioskowania opartego na sztucznej inteligencji (AI) paradoksalnie stymuluje większe wykorzystanie, co prowadzi do ciągłego wzrostu całkowitego zużycia i wydatków.
Kiedy więc dostawcy modeli świętują „wzrost liczby połączeń leksykalnych”, zawsze myślę:
Czy jest to dywidenda efektywności wynikająca z postępu technologicznego czy też nowy szał konsumpcjonizmu?
Nowe zasady gry w łańcuchu przemysłowym
Nacisk Chin na opłacalność kontra nacisk Ameryki na premiumizację: kto wygra?
Metagospodarka tworzy wyraźny łańcuch przemysłowy, w którym każde ogniwo ulega przekształceniu. Ale co jeszcze ciekawsze, Chiny i Stany Zjednoczone podążają zupełnie innymi ścieżkami.
Po stronie produkcji: kto ma tańszą energię elektryczną?
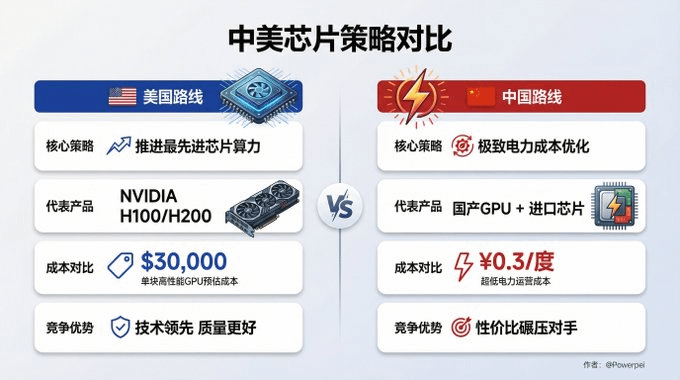
W efekcie, choć model amerykański może być lepszej jakości, to „opłacalność” modelu chińskiego znacznie przewyższa jego konkurencję.
Podobnie jest w przypadku branży telefonów komórkowych: Apple sprzedaje produkty z najwyższej półki, ale Xiaomi i OPPO zdobyły większość światowego rynku, oferując wydajne produkty po konkurencyjnych cenach.
Aspekt optymalizacyjny: Ile pieniędzy może zaoszczędzić oprogramowanie?
To jest moim zdaniem najbardziej niedoceniana warstwa. Sama optymalizacja oprogramowania może zwiększyć generowanie słów nawet 3-5 razy, bez dodawania nowego sprzętu.
Studium przypadku: Technologia trasowania modeli

Przykładowo algorytmy przyspieszające wnioskowanie (kwantyzacja, przycinanie, destylacja) mogą zwiększyć prędkość wnioskowania tego samego modelu 2–3 razy, co jest równoważne wyprodukowaniu większej liczby tokenów przy użyciu tej samej ilości energii elektrycznej.
Dlatego przyszła konkurencja w dziedzinie sztucznej inteligencji może polegać nie na samych modelach, ale na „systemach planowania” i „możliwościach optymalizacji kosztów”.
Zakończenie dystrybucji: Jaka jest istota globalizacji tokenu słownego?
Chińskie modele, wykorzystując swoją przewagę kosztową, umożliwiają „eksport tokenów leksykalnych” za pośrednictwem interfejsów API. Brzmi to jak science fiction, ale w gruncie rzeczy jest prawdą:
➢ Amerykańskie firmy korzystające z chińskich interfejsów API płacą jedną trzecią ceny za milion słów w porównaniu do OpenAI.
➢ Programiści z Azji Południowo-Wschodniej, Ameryki Łacińskiej i Afryki mogą bezpośrednio tworzyć lokalne aplikacje, korzystając z modelu chińskiego.
➢ Nie jest wymagana żadna deklaracja celna, żadna logistyka, ani nawet fizyczna obecność.
To nowy rodzaj „eksportu cyfrowego”: nie sprzedajemy towarów, lecz sprzedajemy samą inteligencję.
Ale pojawia się pytanie: czy Stany Zjednoczone ograniczą obieg słów tak jak ograniczają chipsy? Czy zostanie wprowadzone „embargo na słowa”? To pytanie zasługuje na dalszą uwagę.
Od strony aplikacji: kto zużywa najwięcej tokenów?
Trzy scenariusze z największym zużyciem leksyki:
① Inteligentny agent obsługi klienta
Przedstawiciel obsługi klienta oparty na sztucznej inteligencji obsługuje 1000 rozmów dziennie, zużywając średnio 5000 słów kluczowych na rozmowę, co daje łącznie 5 milionów słów kluczowych dziennie. Średniej wielkości firma e-commerce może zużywać ponad 100 milionów słów kluczowych miesięcznie.
② Generowanie kodu
Programista korzystający z Copilota zużywa od 100 000 do 200 000 jednostek tekstu dziennie. Firma technologiczna zatrudniająca 100 pracowników może zużywać nawet 500 milionów jednostek tekstu miesięcznie.
③ Generowanie treści
Portale własne wykorzystują sztuczną inteligencję do generowania artykułów, scenariuszy wideo i opisów obrazów, zużywając dziennie od 200 000 do 300 000 jednostek wyrazów.
W przyszłości sprawozdanie finansowe każdej firmy SaaS będzie mogło uwzględniać „koszt symboliczny”, tak jak obecnie koszty usług w chmurze.
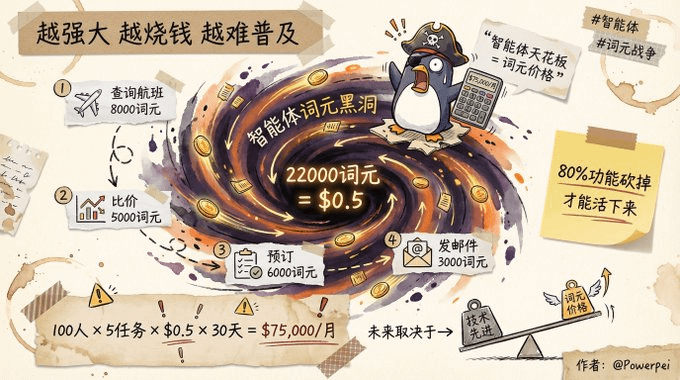
„Czarna dziura leksykalna” inteligentnych agentów
Na szczególną uwagę zasługują inteligentni agenci. Znam zespół startupów, który stworzył asystenta administracyjnego opartego na sztucznej inteligencji, aby pomóc firmom w codziennych zadaniach. Brzmiało to świetnie, ale w pierwszym miesiącu po premierze byli oniemiali:
Podział kosztów w rzeczywistym przypadku
Zadanie: Zarezerwuj dla swojego szefa lot, hotel, taksówkę i salę konferencyjną na wyjazd do Szanghaju w przyszłym tygodniu.
Krok 1: Sprawdź informacje o locie
→ Model wywołano 3 razy, co kosztowało 8000 tokenów.
Krok 2: Porównaj ceny i czas
→ Model został wywołany dwukrotnie, co pochłonęło 5000 tokenów.
Krok 3: Zarezerwuj i potwierdź
→ Model został wywołany dwukrotnie, co pochłonęło 6000 tokenów.
Krok 4: Wygeneruj plan podróży i wyślij go e-mailem
→ Model został wywołany jeden raz, co pochłonęło 3000 tokenów.
Łącznie: 22 000 słów, koszt około 0,50 USD
Jeśli firma zatrudnia 100 pracowników i każdy pracownik ma 5 takich zadań dziennie:
Ostatecznie zespół musiał wyciąć 80% funkcji, pozostawiając tylko najistotniejsze scenariusze, aby utrzymać koszty w akceptowalnym zakresie.
Założyciel powiedział mi coś:
„Nie chodzi o stworzenie produktu, ale o zarabianie na życie. Pułapem dla inteligentnych agentów nie jest technologia, ale cena jednostek leksykalnych”.
Oto paradoks inteligentnych agentów: im potężniejsi są, tym drożsi stają się; im drożsi stają się, tym trudniej ich spopularyzować. Dlatego przyszłość inteligentnych agentów może zależeć nie od stopnia zaawansowania technologii, ale od tego, jak bardzo uda się obniżyć cenę jednostek leksykalnych.
W pewnym sensie wojna cenowa dopiero się rozpoczęła.
Zatem zasady gry uległy zmianie.
Dla firm: ➢ Obliczenia zwrotu z inwestycji (ROI) stały się dokładniejsze.
W przeszłości trudno było oszacować korzyści i koszty przy ocenie projektów z zakresu sztucznej inteligencji.
Teraz możesz dokładnie obliczyć: ile jednostek jest potrzebnych do zastąpienia przedstawiciela obsługi klienta, ile jednostek jest potrzebnych do przetworzenia umowy i ile jednostek jest potrzebnych do wygenerowania raportu.
Struktura kosztów ulega zmianom: część pracy ludzkiej jest zastępowana przez automatyzację, a praca niezwiązana z podstawową działalnością jest szybko mechanizowana. W raportach finansowych, wolumen przetwarzania tekstu może stać się nowym kluczowym wskaźnikiem.
W branży sztuczna inteligencja przeszła już ze „sceny pokazowej” do „sceny infrastruktury”.
Inteligencja nie jest już tajemniczą zdolnością ukrytą w czarnej skrzynce, lecz powszechnie dostępnym zasobem, który można mierzyć, handlować nim i optymalizować, tak jak elektryczność, wodę i przepływ.
Z makroekonomicznego punktu widzenia ➢ Jednostki leksykalne, jako nowy typ czynnika produkcji, zmieniają funkcję produkcji.
Łączy energię, moc obliczeniową, dane i aplikacje, dając początek nowemu systemowi wartości.
Przewaga Chin w dziedzinie zielonej energii, kosztów mocy obliczeniowej i scenariuszy zastosowań umożliwiła jednostkom gospodarczym osiągnięcie globalnego zasięgu.
W istocie polega to na eksporcie energii elektrycznej i mocy obliczeniowej w postaci cyfrowej inteligencji.
Ale zawsze czułem, że coś jest nie tak.
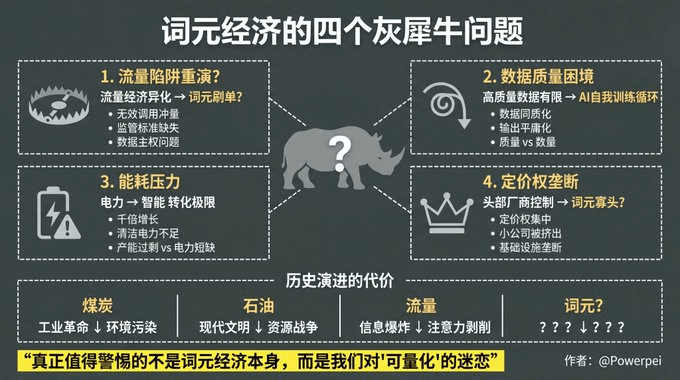
Cztery niewygodne kwestie
„Szary nosorożec” metagospodarki
Po pierwsze, czy słowo metaekonomia stanie się nową „pułapką drogową”?
W dobie Internetu jesteśmy świadkami rozwoju i zniekształcenia gospodarki opartej na ruchu drogowym.
Początkowo ruch był miarą uwagi użytkownika, ale później stał się grą liczbową, którą można manipulować, kupować i fałszować.
Czy jednostki leksykalne pójdą tą samą drogą? Kiedy jednostki leksykalne staną się podstawowymi metrykami, czy niektórzy będą tworzyć nieprawidłowe wywołania, aby je podwyższyć? Czy powstanie łańcuch branżowy „manipulacji jednostkami leksykalnymi”? Czy środki pomocnicze, takie jak regulacje, standardy międzynarodowe i suwerenność danych, nadążą za tym?
Po drugie, czy podaż wysokiej jakości danych nadąży?
Wartość jednostki leksykalnej zależy nie tylko od jej ilości, ale także, a może nawet przede wszystkim, od jej jakości. Jednak dane wysokiej jakości są ograniczone.
Czy w obliczu gorączkowej produkcji jednostek leksykalnych źródła danych nie staną się coraz bardziej homogeniczne? Czy sztuczna inteligencja nie wpadnie w pułapkę „samouczenia się”?
Czy można szkolić sztuczną inteligencję za pomocą treści generowanych przez sztuczną inteligencję i otrzymywać coraz bardziej przeciętne wyniki?
Po trzecie, jak rozwiązać problem presji związanej ze zużyciem energii?
Istotą metaekonomii jest przekształcanie elektryczności w inteligencję. Ale elektryczność nie jest nieskończona, zwłaszcza czysta.
Czy przy tysiąckrotnie większym zużyciu słów podaż energii nadąży? Czy pojawi się sprzeczność między nadmiarem słów a niedoborem mocy?
Po czwarte, kto ma władzę nad ustalaniem cen?
Obecnie ceny jednostkowe za słowa są ustalane głównie przez kilku wiodących dostawców modeli. Ale czy w miarę jak jednostki słów staną się infrastrukturą, koncentracja siły cenowej doprowadzi do powstania nowego monopolu?
Czy powstanie „oligopol leksykalny”? Czy małe firmy i indywidualni deweloperzy zostaną wyparci z rynku?
Te pytania pozostają na razie bez odpowiedzi. Myślę jednak, że zanim zaczniemy świętować „Pierwszy Rok Metagospodarki”, powinniśmy przynajmniej poddać te pytania pod dyskusję.
Podsumowując
Od węgla i ropy naftowej w epoce przemysłowej, przez ruch uliczny i dane w epoce informacji, aż po słowa w epoce inteligencji, ludzka ekonomia zawsze ewoluowała wokół „podstawowej energii i jednostek miary”. Ta logika jest słuszna.
Ale każdej ewolucji towarzyszą nowe nierówności, nowe marnotrawstwo i nowe wyobcowanie:
Węgiel spowodował rewolucję przemysłową, ale przyniósł też zanieczyszczenie środowiska.
Ropa naftowa dała początek nowoczesnej cywilizacji, ale przyniosła też wojny o zasoby.
Ruch uliczny spowodował eksplozję informacji, ale także stał się przyczyną wykorzystywania uwagi.
Co przyniosą elementy leksykalne? Za wcześnie, żeby wyciągać wnioski.
Mam po prostu niejasne przeczucie, że gdy „myślenie” i „tworzenie” zostaną określone jako towary podlegające obrotowi,
Gdyby każdy wynik sztucznej inteligencji był precyzyjnie rozliczany, moglibyśmy stracić coś o wiele ważniejszego.
Tego rodzaju eksploracja bez względu na koszty, tego rodzaju inspiracja, której nie da się zmierzyć, tego rodzaju wartość, która wykracza poza wydajność.
Być może powinniśmy być ostrożni nie tyle ze względu na samo słowo „gospodarka”, ile z powodu naszej fascynacji rzeczami, które da się zmierzyć.
Nie wszystko co wartościowe da się zmierzyć i nie wszystko co da się zmierzyć ma wartość.
Ostatnie pytanie do Ciebie:
Czy Twoja firma zaczęła budżetować zużycie leksykaliów? Kiedy agenci pochłaniają leksykali jak wodę, czy zdarza Ci się zatrzymać i pomyśleć: co właściwie te leksykale dla nas tworzą?