i went through the inference API documentation a few days ago expecting the usual minimal developer experience that most AI blockchain projects ship at the infrastructure layer. it was more complete than i expected actually. endpoint documentation clear. authentication straightforward. response formatting consistent. for a protocol six months into mainnet this is more developer tooling than most comparable projects bother to produce before they have significant adoption.
then i tried to find how the API handles model version changes.
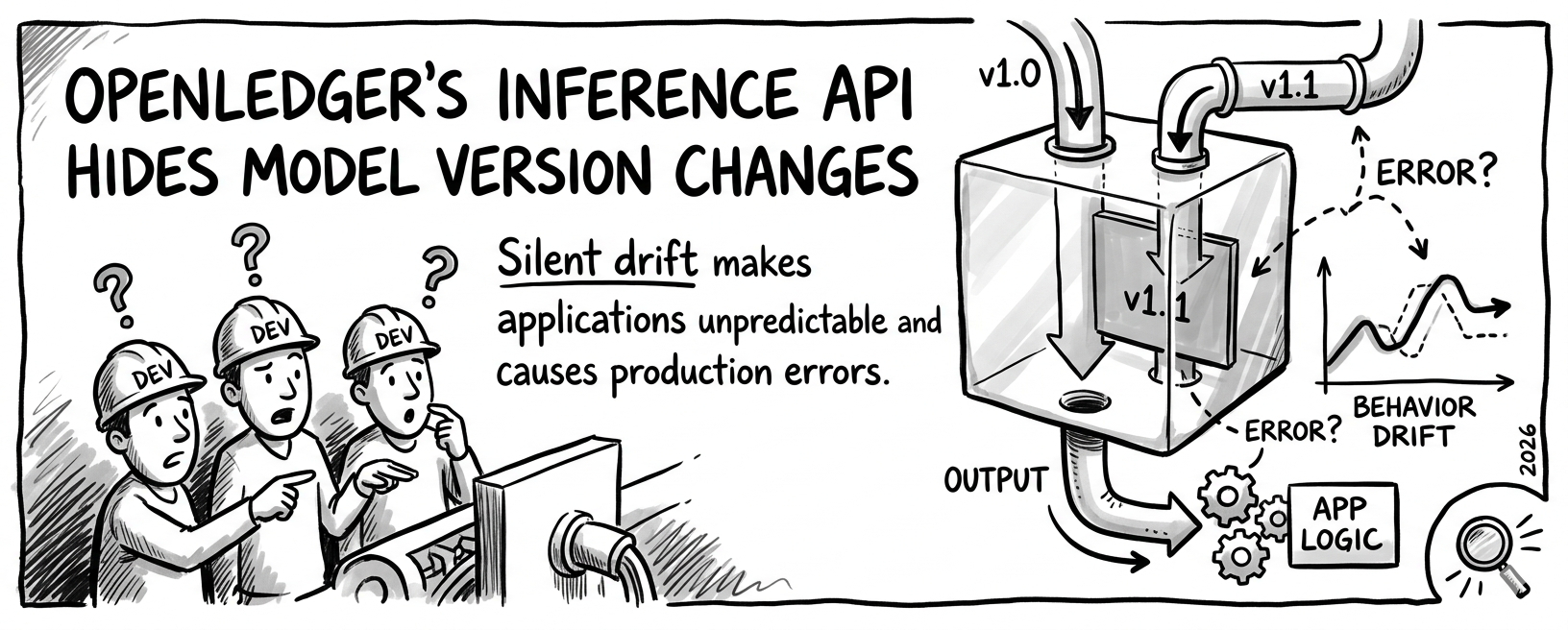
when a developer integrates openledger's inference API into their application, they call a model by identifier. the API returns an output. the developer builds application logic around that output parsing it, feeding it into downstream systems, using it to generate responses for their users. that integration assumes a specific relationship between input and output. it assumes the model behavior is stable enough that the same input produces meaningfully similar outputs over time.
but openledger's models get updated. datanets improve. ModelFactory fine-tuning cycles run. the attribution engine update from january 2026 was specifically designed to maintain data-output links as models evolve which means model evolution is expected, designed for, and actively happening. every improvement to a model is a legitimate and valuable update. the problem is that the API documentation doesn't clearly specify what happens to active integrations when the model they're calling gets updated. does the same model identifier always serve the same version? or does it serve the latest version? that distinction determines whether a developer's application behavior can change silently beneath them. 🔍
the consequence is specific and quiet. a developer builds a legal document review application using openledger's inference API. they tune their application logic around the model's output patterns the specific way it structures responses, the confidence levels it expresses, the edge cases it handles or doesn't handle. the model gets improved through a new fine-tuning cycle. the improvements are genuine. the model is better at its domain task. but the output patterns shift in ways the developer didn't expect and wasn't notified about. their downstream application logic, built around the previous output patterns, starts producing errors. not catastrophic failures subtle behavioral drifts that take time to diagnose because the developer's code hasn't changed and the model identifier they're calling hasn't changed.
i watched this exact pattern create significant pain for developers building on social media APIs between 2012 and 2015. the APIs were well-documented. the authentication worked. the endpoints were stable. what changed silently were the response schemas fields added, removed, restructured without versioning or deprecation notices. developers discovered the changes through broken applications rather than through documentation updates. the platforms understood this was happening. they didn't have strong versioning infrastructure. developers learned to defensively code around an API that might change its behavior without announcement.
openledger's inference API may be at exactly that same early infrastructure stage. the endpoints work. the authentication is solid. what isn't clearly documented is whether model updates propagate silently to all active integrations or whether the API provides version pinning the ability for a developer to specify they want to remain on a specific model version until they explicitly choose to upgrade. version pinning is standard practice in production API design precisely because it protects developers from behavioral changes they didn't request. its presence or absence in openledger's inference API is the difference between an API that developers can build production applications on and one that requires constant defensive monitoring.
the genuinely strong element here is that the layerzero integration across 130 chains demonstrates the team's capacity for sophisticated infrastructure engineering. the story protocol compliance partnership from january 2026 creates real incentive for enterprise developers who need behavioral consistency legal AI applications can't have silent output drift because the downstream consequences are significant. those are both reasons to believe the team understands why version stability matters and may already be building it.
there is a version of this where i'm wrong. openledger could have implemented model version pinning in the inference API without documenting it prominently meaning developers who know to ask for it can access it, but the feature doesn't surface in the standard documentation flow. the attribution engine update from january 2026 addressed model evolution tracking, which suggests the team was already thinking about how to manage model changes in ways that protect downstream systems. if version pinning exists and is accessible, the silent update problem is solved for developers who know to use it.
what i'd want to see is not a general statement about API stability. a specific documentation page showing whether the inference API supports version pinning, what the syntax is for requesting a specific model version, and what the policy is for communicating breaking changes to developers with active integrations. that documentation, appearing in any API update since mainnet launched in november 2025, would tell me whether openledger built its inference layer for developers who need production stability or for developers who are still experimenting and whether an enterprise developer can safely bet their application on a model that might improve without warning. its absence means the inference API isn't unreliable it's underdocumented. unreliable gets fixed. underdocumented just keeps surprising developers who assumed stability because nothing in the docs said otherwise.
