

The blockchain industry has never lacked grand narratives, but very few projects can truly ground these narratives. When we talk about 'full-chain data', what most people conjure up may be fragmented block explorers, disjointed on-chain analysis tools, or isolated datasets from certain vertical tracks. This sense of fragmentation is reminiscent of the information islands of the early internet—until the emergence of Google. Now, Chainbase is attempting to play a similar role in the blockchain data space: integrating scattered on-chain data into the infrastructure for the AGI era.
How heavy is the 'full' in full-chain data?
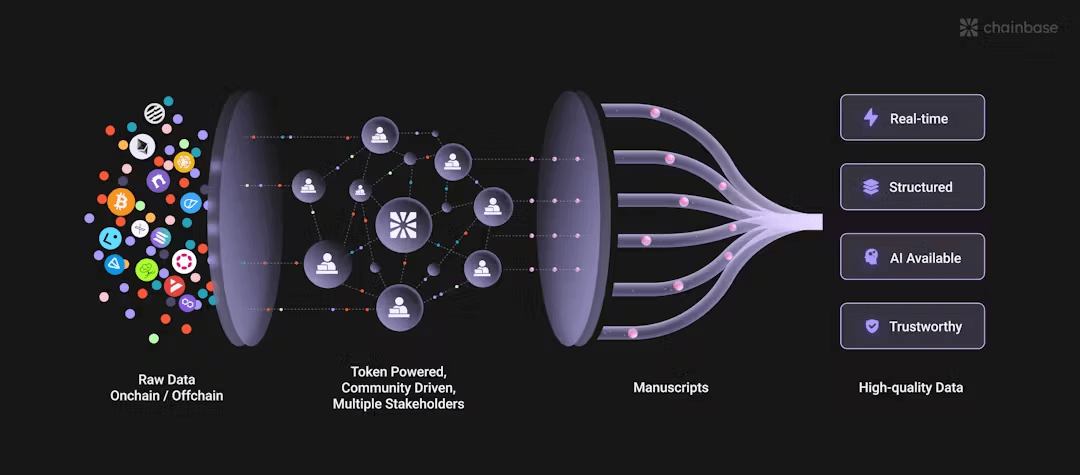
To measure the value of a data network, one must first look at its coverage breadth. Chainbase currently integrates data from dozens of mainstream L1/L2 chains, including BTC and ETH, covering both EVM and non-EVM ecosystems. This means that whether it's the UTXO model of Bitcoin, the smart contract logs of Ethereum, or the high-throughput transaction records of Solana, they are all included in the same standardized system. This ability to 'unify all chains' is by no means simple data transfer—it requires compatibility with different chains' underlying protocols and even the reconstruction of data storage logic.
More critically, it is the depth of data. Chainbase divides on-chain information into three levels:
- Raw data: The most original blocks, transactions, and contract bytecode, equivalent to 'fresh ingredients' in food;
- Decoded data: Converting raw data into human-readable formats, such as lending events in DeFi protocols;
- Abstracted data: Refined metric-level data, such as token prices, changes in NFT holdings, etc., directly serving business decisions.
This layered processing allows developers to choose data on demand, much like selecting the ripeness of ingredients. The 3-second data refresh speed (far exceeding the industry average) ensures the 'freshness' of the 'ingredients'—for high-frequency trading in DeFi or real-time monitoring scenarios, this low latency means real competitive edge.
The network effect behind the scale of data
As of the latest disclosure, Chainbase has stored PB-level data, processing an average of 110 million to 150 million calls per day, with a cumulative call volume exceeding 50 billion. Behind these numbers is the real demand of 15,000 developers and 8,000 projects. But more noteworthy than scale is its network architecture design:
1. Decentralized entry: Through an Open Data Gateway, any node operator or RPC service provider can contribute chain data, forming a distributed data source. This not only avoids centralized single points of failure but also lowers the data access threshold.
2. Token incentive-driven: Unlike traditional cloud vendors, Chainbase uses token economics to incentivize community participation in data cleaning, labeling, and computation, which is closer to a 'data DAO' collaborative model.
3. Programmable data layer: Developers can not only access data but also customize processing logic through 'data manuscripts'. For example, extracting the liquidation event chain of a specific DeFi protocol, or tracking the holder profile of a certain type of NFT.
This structure makes Chainbase more like a self-growing data ecosystem rather than a static database. As more developers join, the dimensions and value of the data will increase exponentially—this is a typical characteristic of the network effect in the Web3 era.
When crypto data meets the critical point of AGI
Chainbase's ambition is clearly not limited to serving existing crypto applications. The statement of 'the largest data source in the AGI era' in its positioning reveals a deeper strategic intent:
- Credibility: The immutable nature of blockchain is inherently suitable for training AGI models, avoiding the pollution issues of traditional internet data;
- Structured potential: On-chain behavioral data (such as transactions, voting, governance) has clear semantic labels, far exceeding unstructured internet data;
- Real-time feedback loop: Price discovery in the DeFi market and preference shifts in the NFT community can provide dynamic training materials for AGI.
Currently, projects are using Chainbase data to train predictive market models or automate trading strategies. In the future, when AGI needs to understand human economic behavior, is there a more transparent and continuous behavioral dataset than blockchain?
Reconsidering the investment value of Chainbase
Although Chainbase has completed a $15 million financing, its value is still underestimated by the market. In horizontal comparison, centralized data platforms like Chainalysis are valued at over $4 billion, while Chainbase's differentiation lies in:
- Protocol layer advantages: By standardizing data interfaces, it is essentially defining the interaction standards for full-chain data;
- Decreasing marginal costs: Each additional chain or data consumer accelerates the overall value of the ecosystem;
- Anti-capture: Open networks are more in line with the spirit of Web3 than closed data oligopolies, and are more sustainable in the long run.
If data is the oil of the new era, then what Chainbase is doing is not only drilling oil wells but also building the complete infrastructure of pipelines, refineries, and gas stations. While the industry is still debating which chain will become the 'super chain', Chainbase has quietly woven a data grid connecting all chains—this is the true infrastructure-level opportunity.
In the crypto world, we have seen too many fleeting narratives. But the demand for data has never disappeared; it is just waiting for a sufficiently robust platform to carry it. Chainbase's answer is just beginning to unfold, and its competitor may not even be similar data platforms, but rather the yet-to-be-fully-awakened future of AGI.