Ich werde ehrlich sein, kein Zugang zu Chatbots.
Dieser Teil ist bereits normal geworden.
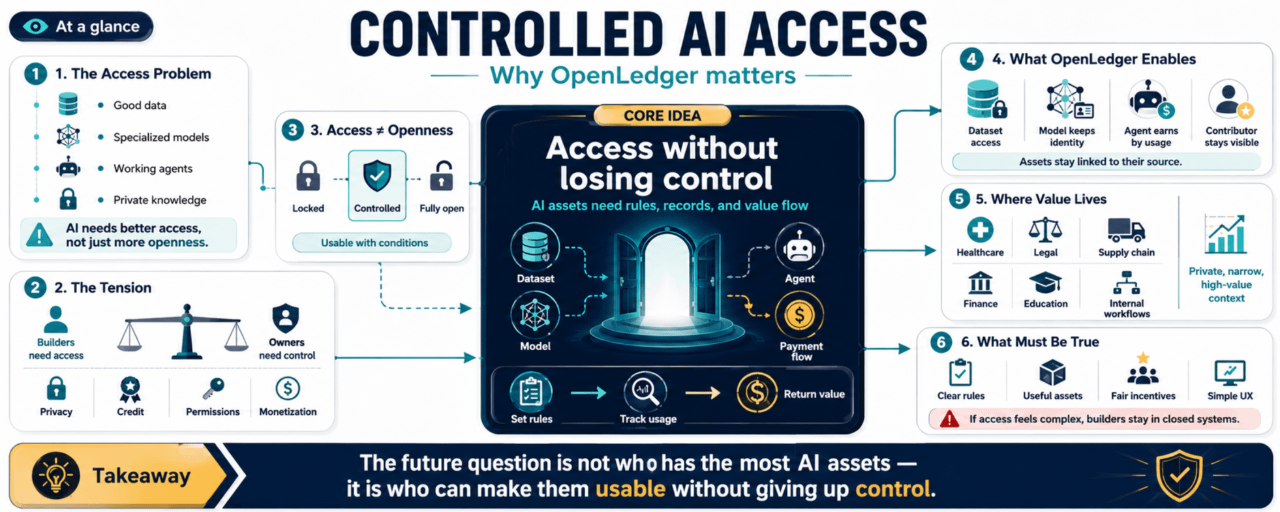
Das tiefere Problem ist der Zugang zu den Dingen, die KI nützlich machen.
Gute Daten.
Spezialisierte Modelle.
Arbeitsfähige Agenten.
Saubere Feedback-Schleifen.
Fachwissen, das nicht aus dem offenen Internet stammt.
Diese Dinge sind nicht gleichmäßig verfügbar.
Einige Unternehmen haben jahrelange private Informationen in ihren Systemen. Einige Teams haben kleine Modelle entwickelt, die sehr spezifische Probleme lösen. Einige Entwickler haben Agenten, die in engen Workflows gut funktionieren. Einige Gemeinschaften haben Wissen durch wiederholte Diskussion, Korrektur und Nutzung geschaffen.
Aber die meisten dieser Assets bewegen sich nicht leicht.
Sie sind nützlich, aber nicht immer erreichbar.
Da kommt @OpenLedger es wertvoll vor, es aus einer anderen Perspektive zu betrachten.
Es geht nicht nur darum, KI-Assets zu monetarisieren. Es geht auch darum, den Zugang strukturierter zu gestalten.
Denn Zugang ist nicht dasselbe wie Offenheit.
Das ist ein wichtiger Unterschied.
Ein Datensatz muss nicht vollständig öffentlich sein, um nützlich zu sein.
Ein Modell muss nicht für alle kostenlos sein, um Wert zu haben.
Ein Agent muss nicht überall laufen, um Auswirkungen zu erzielen.
Manchmal ist die bessere Frage nicht: „Kann das jeder nutzen?“
Es ist: „Können die richtigen Leute das unter klaren Regeln nutzen?“
Da wird es interessant.
KI-Entwickler benötigen oft spezifische Inputs. Nicht nur mehr Daten, sondern besser abgestimmte Daten. Nicht nur größere Modelle, sondern Modelle, die für die Aufgabe trainiert sind. Nicht nur allgemeine Agenten, sondern Agenten, die einen bestimmten Workflow verstehen.
Gleichzeitig möchten die Eigentümer dieser Assets sie möglicherweise nicht einfach übergeben.
Und das macht Sinn.
Ein Unternehmen möchte möglicherweise keine Rohdaten von Kunden offenlegen.
Ein Forscher möchte möglicherweise nicht, dass ein Modell ohne Anerkennung wiederverwendet wird.
Ein Entwickler möchte vielleicht verdienen, wenn ein Agent weiterhin genutzt wird.
Eine Community möchte möglicherweise Kontrolle darüber haben, wie ihr geteiltes Wissen angewendet wird.
Also gibt es eine Spannung.
KI benötigt Zugang.
Asset-Eigentümer benötigen Kontrolle.
#OpenLedger scheint zwischen diesen beiden Bedürfnissen zu sitzen.
Es deutet auf ein System hin, in dem Daten, Modelle und Agenten verfügbar gemacht werden können, ohne vollständig von ihrer Quelle getrennt zu werden. Das Asset kann Regeln haben. Die Nutzung kann aufgezeichnet werden. Der Wert kann zurückfließen, wenn das Asset hilft, etwas Nützliches zu schaffen.
Das mag klein erscheinen, aber es verändert die Beziehung.
Anstatt KI-Assets als Dinge zu behandeln, die entweder abgeschottet oder vollständig aufgegeben werden müssen, gibt es einen Mittelweg. Kontrollierter Zugang. Nachverfolgbare Nutzung. Laufende Monetarisierung.
Das ist wahrscheinlich der Punkt, an dem Blockchain eine praktischere Rolle spielt.
Nicht als Ersatz für KI.
Nicht als Slogan, der an KI angehängt ist.
Eher wie eine Koordinationsschicht für Assets, die Berechtigungen, Aufzeichnungen und Zahlungen benötigen.
Man kann normalerweise erkennen, wenn es an Koordination fehlt, weil die Leute anfangen, manuell um das Problem herum zu bauen. Private Deals. Individuelle Lizenzen. Geschlossene Partnerschaften. Einmalige Integrationen. Lange Genehmigungszyklen. Vertrauen basiertes Teilen.$AIA
Diese Dinge können funktionieren, aber sie skalieren nicht sauber.
KI entwickelt sich zu schnell, als dass jedes nützliche Asset eine private Verhandlung erfordern sollte.
Wenn OpenLedger helfen kann, die Regeln klarer zu machen, dann könnten mehr Assets nutzbar werden, ohne die Eigentümer dazu zu zwingen, alles aufzugeben. Das ist die praktische Idee, die dahintersteckt.
Und es ist wichtig, weil die Zukunft der KI möglicherweise nicht nur aus öffentlichen Daten und riesigen Modellen besteht.
Ein großer Teil des nächsten Wertes könnte aus privaten, engen, schwer zugänglichen Kenntnissen stammen.
Gesundheitsarbeitsabläufe.
Rechtsdokumente.
Daten aus der Lieferkette.
Finanzmuster.
Industrielle Protokolle.
Bildungsfeedback.
Support-Gespräche.
Interne Geschäftsprozesse.
Das sind nicht immer glamouröse Quellen. Aber oft ist dort der echte Nutzen zu finden.
Das Problem ist, dass sie sensibel, fragmentiert und schwer zu bewerten sind.
Also bleiben sie hinter Wänden.
Der Ansatz von OpenLedger legt nahe, dass diese Wände nicht immer entfernt werden müssen. Vielleicht brauchen sie einfach bessere Türen.$PLAY
Das ist eine ruhigere Art, darüber nachzudenken.
Nicht alles sollte offen sein. Nicht alles sollte versteckt sein. Einige Dinge sollten unter Bedingungen zugänglich sein.
Und wenn Bedingungen klar ausgedrückt werden können, werden neue Märkte möglich.
Ein Entwickler könnte auf einen Datensatz zugreifen, ohne ihn vollständig zu besitzen.
Ein Modell könnte in einem größeren System verwendet werden, während es seine Identität behält.
Ein Agent könnte innerhalb eines Workflows operieren und von der tatsächlichen Nutzung profitieren.
Ein Mitwirkender könnte teilnehmen, ohne im Endprodukt zu verschwinden.
Natürlich muss das System sich beweisen.
Die Regeln müssen verständlich sein. Die Assets müssen nützlich sein. Die Anreize müssen fair genug sein, damit die Leute sich dafür interessieren. Und die Erfahrung muss einfach genug sein, damit Entwickler es nicht meiden.
Das ist immer der schwierige Teil.
Dennoch ist das Zugangsproblem real.
KI möchte mehr Kontext, aber der beste Kontext ist oft in Orten eingeschlossen, die nicht einfach alles öffnen können. Das ist die Lücke, um die sich OpenLedger bemüht.#BNBBreaks740USDTUp12Percent
Vielleicht ist das der Blickwinkel, der am meisten Sinn macht.
Nicht KI-Daten als etwas, das man extrahieren kann.
Nicht Modelle als Dateien, die man einmal verkauft.
Nicht Agenten als isolierte Werkzeuge.
Eher wie eine kontrollierte Zugangsschicht für die nützlichen Teile von KI, die derzeit schwer zu erreichen sind.
Und wenn diese Schicht funktioniert, selbst stillschweigend, beginnt sich die Frage zu verschieben.
Von „Wer hat die meisten KI-Assets?“
zu
„Wer kann seine KI-Assets nutzbar machen, ohne die Kontrolle zu verlieren?“
Das fühlt sich an wie das echte Gespräch, das zu entstehen beginnt.
$OPEN
Artikel
Eines der stillen Probleme in der KI ist der Zugang.
Haftungsausschluss: Enthält Meinungen von Drittanbietern. Keine Beratung. Binance Ai wird ohne Gewähr bereitgestellt. Siehe AGB.