Nobody Is Talking About What Happens to the Long Tail.
OpenLedger's vision is a distributed AI data economy where domain expertise from every corner of human knowledge becomes a monetizable, attributed asset. A clinician contributes rare disease data. A constitutional scholar contributes legal reasoning. An agricultural specialist contributes climate-specific farming knowledge. A linguist contributes grammar structures for an endangered language. All of it attributed, all of it earning, all of it contributing to AI models that would otherwise have no way to access that expertise.
The vision is compelling. It is also, as a prediction about how the economic system will actually perform, almost certainly wrong in one specific and important way.
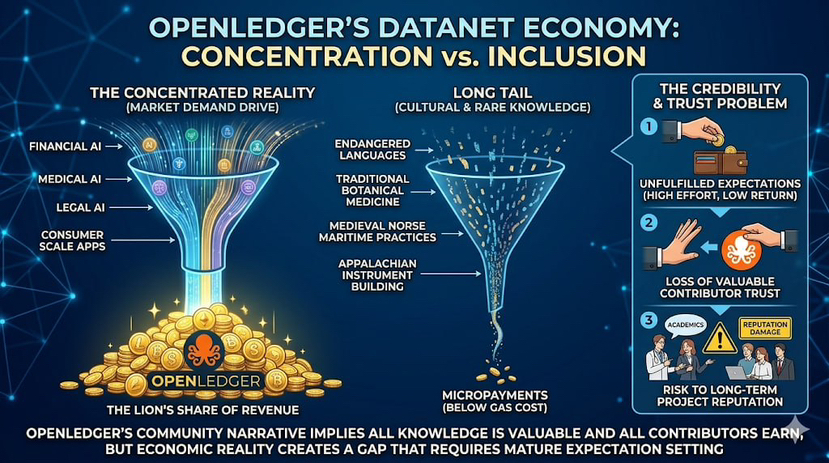
The Datanet economy will concentrate. Revenues will flow predominantly to a small number of high-demand domains while the long tail earns fractions of what contributors in those domains expected. This is not a design flaw in OpenLedger's architecture. It is a mathematical inevitability of building a contributor payment system indexed to market demand, and it creates problems for the project's community credibility that nobody in the public discourse has directly addressed.
Why Concentration Is Mathematically Inevitable
OpenLedger's contributor payments are derived from inference revenue. More inference means more revenue, which means more contributor earnings. The inference volume for a given model is determined by how many people use the products built on that model. Demand for AI products is not uniformly distributed across domains. It is highly concentrated in a small number of high-value, high-frequency application categories.
Financial AI products, trading tools, investment analysis, risk assessment, regulatory compliance, run inference constantly. Medical AI products, clinical decision support, drug discovery, patient triage tools, serve large markets with intensive usage. Legal AI, contract review, legal research, case prediction, is growing fast with high usage per session because legal tasks are time-intensive. AI tools for software development, marketing automation, and customer service run at consumer scale.
These five to eight application categories will generate the vast majority of inference volume on any AI infrastructure platform. The Datanets serving these categories will generate the vast majority of contributor revenue.
Now consider the tail. The Datanet for traditional textiles of the Central Asian steppe. The Datanet for pre-Columbian Mesoamerican botanical medicine. The Datanet for medieval Norse maritime navigation practices. The Datanet for traditional Appalachian instrument building. These are real domains of human knowledge, documented by real experts who have spent careers developing expertise that exists nowhere else. An AI model trained on any of these Datanets could be genuinely valuable to researchers, historians, and cultural preservation organizations.
But the inference volume for these models will be a fraction of what financial or medical AI generates. The contributor earnings in these long-tail Datanets will be correspondingly small, potentially so small that the micropayment per contributor per inference period fails to clear the gas cost of payment distribution.
The Credibility Problem
OpenLedger's community narrative consistently implies that all knowledge is valuable and all contributors earn. The project points to the breadth of Datanet topics as evidence of an inclusive knowledge economy. The 61.71% community token allocation is presented as evidence of distributed ownership and distributed benefit.
The economic reality will be that financial and medical Datanet contributors earn real income while long-tail Datanet contributors earn amounts that do not justify the time investment of serious contribution. This is not a temporary condition that resolves as the platform scales. It is a structural outcome of indexing contributor income to inference demand. As the platform scales, the high-demand domains scale faster because they attract more model builder investment, better products, and more users. The concentration intensifies with scale rather than diminishing.
When this becomes visible to contributors in low-volume Datanets, the credibility gap between OpenLedger's stated vision of an inclusive distributed knowledge economy and the actual economic distribution will be significant. The contributors who invested time in long-tail Datanets, believing the vision, will have contributed to an ecosystem that delivered them fractions of what contributors in high-demand domains earned.
The Trust Problem This Creates
The long-tail contributors that OpenLedger needs, the specialists in rare and underrepresented domains of human knowledge, are often the contributors with the most to offer in terms of knowledge that exists nowhere else. A linguist documenting an endangered language's grammar structures cannot find that knowledge anywhere online. An expert in a traditional agricultural practice that has never been systematically studied cannot access comparative datasets from prior work. These contributors are not adding to an existing corpus. They are creating the first systematic record of knowledge that would otherwise be lost.
These are exactly the contributors who will experience the greatest gap between the vision and the economic reality. And they are the contributors whose disillusionment will be most damaging to OpenLedger's reputation in the academic and professional communities that OpenLedger needs for long-term credibility.
A mature response to this problem acknowledges the concentration dynamic honestly, explains what mechanisms if any the platform has to support long-tail Datanets economically, and sets appropriate expectations for contributors whose domains are unlikely to generate high inference volumes in the near term. The alternative is allowing contributors to make participation decisions based on projections that the economic structure makes unrealistic, and dealing with the resulting credibility damage when reality arrives.