
Ich kreise immer wieder um eine Frage, die zunächst fast zu technisch klingt, bis ich lange genug darüber nachdenke, dass sie sich auf eine andere Weise unangenehm anfühlt:
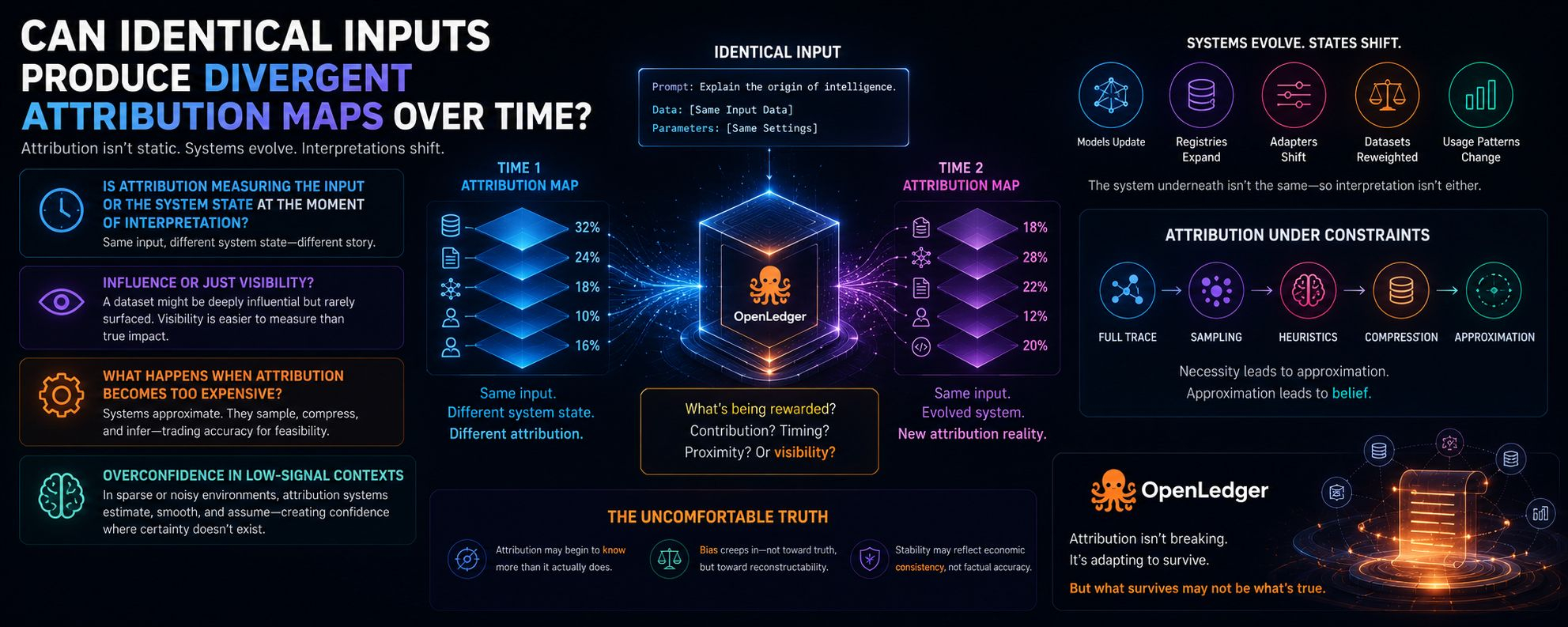
Können identische Inputs divergente Attributionskarten über die Zeit produzieren?
Auf dem Papier sollten sie das nicht. Gleicher Input, dasselbe System, dieselben Regeln. Aber je mehr ich über OpenLedger-Style Attribution Layers nachdenke, desto mehr habe ich das Gefühl, dass „gleicher Input“ eine Art Illusion ist, sobald sich das System selbst ständig verändert – Modelle aktualisieren sich, Register erweitern sich, Adapter verschieben sich, Datensätze werden stillschweigend durch Nutzungsmuster neu gewichtet.

Und dann frage ich mich:
Misst die Attribution überhaupt noch den Input oder den Systemzustand im Moment der Interpretation?
Hier beginnt es, sich anders anzufühlen.
Denn wenn sich die Attribution-Maps über die Zeit für identische Inputs verschieben, was genau wird dann belohnt? Beitrag? Oder Timing? Oder einfach Nähe zu einer günstigeren Systemkonfiguration?
Und ehrlich gesagt, ich verstehe, warum Systeme sich so entwickeln. Statische Interpretationen überleben in dynamischen Netzwerken nicht. Aber trotzdem fühlt sich etwas daran instabil an, in einer Weise, die schwer vollständig zu artikulieren ist.
Dann frage ich mich immer wieder:
Werden die Beitragsleistenden tatsächlich für ihren Einfluss oder nur für ihre Sichtbarkeit belohnt?
Die Unterscheidung klingt subtil, aber sie wird immer breiter, je mehr ich darüber nachdenke. Einfluss impliziert Kausalität. Sichtbarkeit impliziert Exposition. Ein Datensatz könnte tiefgehend einflussreich sein, aber selten sichtbar. Ein anderer könnte häufig abgerufen werden, leicht wirkungsvoll sein, aber wirtschaftlich dominant, einfach weil er in hochfrequentierten Inferenzpfaden sitzt.
Und das ist keine kleine Unterscheidung.
Denn sobald Sichtbarkeit leichter zu messen ist als Einfluss, neigen Systeme natürlich dazu, das zu belohnen, was sie sehen können. Nicht das, was am wichtigsten ist. Nur das, was am häufigsten von der Attributionsschicht begegnet wird.
Dann dringt ein weiterer Gedanke ein:
Was passiert, wenn die Berechnung der Attribution pro Abfrage zu teuer wird?
Diese Frage fühlt sich weniger theoretisch und mehr wie eine versteckte Einschränkung an, die bereits Designentscheidungen prägt. Wenn vollständige Attributionstracing wirtschaftlich belastend wird, könnten Systeme anfangen, sich anzunähern. Sampling statt Tracing. Heuristiken statt vollständiger Abstammungsgrafen. Kompression statt vollständiger kausaler Abbildung.
Und sobald das passiert, ändert sich etwas subtil.
Nicht das Versagen.
Aber das Vertrauen.
Attribution könnte anfangen, sich so zu verhalten, als wüsste sie mehr, als sie tatsächlich tut.
Hier beginnt die Idee von 'Überkonfidenz in Niedrigsignal-Kontexten' mich zu stören. Denn in spärlichen oder lauten Inferenzumgebungen müssen Systeme immer noch wirtschaftliche Outputs produzieren. Also schätzen sie. Sie glätten. Sie inferieren Beiträge, wo das Signal schwach ist.
Und ich frage mich immer wieder:
Führt das zu einer stillen Verzerrung hin zu den Mustern, die am einfachsten rekonstruiert werden können, anstatt zu dem, was tatsächlich das Ergebnis verursacht hat?
Vielleicht.
Vielleicht nicht.
Aber selbst die Unsicherheit fühlt sich hier bedeutungsvoll an.
Denn wenn Attribution wirtschaftlich notwendig, aber rechnerisch approximiert wird, dann beschäftigen wir uns nicht mehr mit reinen Tracing-Systemen. Wir haben es mit Glaubenssystemen zu tun, die Einfluss unter Einschränkungen annähern.
Und das ändert, was dieses System tatsächlich ist.
Ich komme immer wieder in die gleiche unbequeme Schleife zurück:
Wenn identische Inputs über die Zeit unterschiedliche Attribution-Maps produzieren, und Sichtbarkeit Einfluss überwiegt, und die Berechnung zur Approximation zwingt... was genau wird dann stabilisiert?
Nicht die Wahrheit.
Nicht der Ursprung.
Vielleicht nur Konsistenz der Belohnungsverteilung unter sich ändernden internen Annahmen.
Und ich kann nicht sagen, ob das eine Designbeschränkung oder etwas näher an einer strukturellen Eigenschaft von skalierenden Intelligenzsystemen ist.
Vielleicht bricht die Attribution nicht.
Vielleicht lernt es einfach zu überleben, indem es weniger sicher über sich selbst wird.
