
 去年AI爆火的时候,大家可能都感觉到了一种焦虑——生成式AI越来越厉害,但普通人的数据被用了、创意被学了、工作被替代了,钱却被平台赚走了。这种"贡献者白嫖"的逻辑,我觉得迟早要出问题。
去年AI爆火的时候,大家可能都感觉到了一种焦虑——生成式AI越来越厉害,但普通人的数据被用了、创意被学了、工作被替代了,钱却被平台赚走了。这种"贡献者白嫖"的逻辑,我觉得迟早要出问题。
前几天晚上,我正准备加仓OPEN,又仔细读了一遍OpenLedger关于"可支付AI"的文档...然后我停住了,只开了个小测试仓位。不是因为想法弱——恰恰相反。有时候当一个项目试图重构整个价值分配逻辑时,我会更谨慎,而不是更冲动。
被忽视的"贡献者资本主义":谁创造,谁受益
现在,工程师标注数据、开发者优化模型、创作者生产内容...但价值主要流向拥有算力和平台的人。OpenLedger的论点不同:如果人类生成的数据训练了AI,那人类应该参与经济产出。
有趣的部分不是口号,是背后的机制。
他们的"可支付AI"系统本质上是在做一件事——把AI代理的每次调用都变成一次链上交易。数据提供者按次收费,模型开发者按调用分成,验证者按服务质量拿奖励。这不是"更聪明的AI",这是"更公平的AI经济"。
因为一旦AI代理开始自主接单(自动化交易、内容生成、客户服务),谁来确保创作者不被白嫖?谁来保证中间商不抽走大头?OpenLedger用智能合约回答这些问题——代码即规则,没有谈判桌,没有维权成本。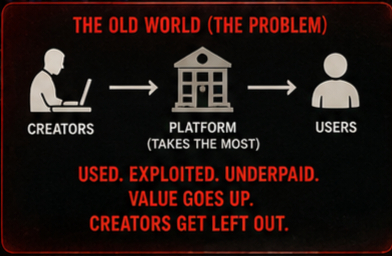
四大角色的价值循环:不是生态,是经济
在OpenLedger的框架里,我看到一套清晰的价值网络,不是抽象的"生态",是可算账的经济:
第一,数据提供者。把自己的高质量数据通过Datanet灵活定价。比如一家券商可以把高频交易数据上链,按次收OPEN;医疗领域的稀有病例数据集,用户群小但价值高,单次授权费相当可观;一个加密货币KOL把过去几年的行情分析文章打包上链,每次被AI调用都能收到小额OPEN。谁参与,谁受益,参与越多受益越多。
第二,模型开发者。把训练好的专用模型部署在OpenLedger上。企业调用一次付一次钱,开发者坐享分成。特别是实用性广泛的模型——比如为电商训练的小模型,每天被调用上千次,收益积少成多。这比卖API订阅更公平,因为每次调用都自动结算,没有拖欠。
第三,AI代理与应用方。他们是AI时代的消费者。一个AI驱动的交易机器人,为了精准决策,需要实时调用链上可信的价格数据。每调用一次,消耗一点OPEN支付给数据提供方。有消耗才有上升空间,有付费才有真实需求。
第四,验证者。他们是整个生态的裁判员。质押OPEN运行节点,验证AI推理的归因证明是否真实有效。验证通过拿奖励,乱来就罚没。这套机制把AI的可信度交给去中心化网络维护,不是信任单一机构。
链上数据证实了这套经济模型的可行性
根据我查到的公开信息,OpenLedger测试网节点已超过10万个,日活贡献者超4万,日均处理推理请求超10万次。 � 社区与生态分配占比高达61.71%,团队和投资人设有12个月锁仓期。
更关键的是代币经济设计:每笔交易固定销毁约1%的OPEN,协议还将部分交易费用用于公开市场回购并永久销毁。使用就是消耗,消耗代表通缩,成功将代币价值与生态实际使用量深度绑定。
动态通胀模型从初期8%逐步递减至2%,20%交易手续费用于回购销毁,30%平台收入分配给质押者。这为长期持有者提供了看得见的潜在收益。
验证者:守护价值链条的裁判,不是无脑质押的机器
很多人知道数据提供者和模型开发者,但容易忽略验证者群体。他们不只是打包交易,需要验证AI代理的每次推理是否准确、归因证明是否真实有效。
收入结构也不是单一质押回报,而是三部分:基础奖励+性能奖励+治理奖励,与在线率、响应延迟、验证准确性直接挂钩。在线率99%+的节点,收入远高于三天打鱼两天晒网的节点——多劳多得。
普通用户门槛并不高,可以质押OPEN委托给可靠节点运营商,分享验证奖励。官方还推出零Gas费质押活动,早期验证者享受更高年化收益。 
实际案例:医疗数据合规调用
验证者最惊艳的应用场景是合规数据调用。一家医院把患者数据注册到OpenLedger,只允许在带欧盟合规证明的可信执行环境节点上运行。AI团队想用这批数据训练模型时,系统先验证节点地理位置和运行环境,合规后才放行,OPEN费用自动结算给医院和验证者。
整个流程既保护患者隐私,又让沉睡数据产生价值。这是传统区块链和中心化AI平台都做不到的事——验证者就是负责把关的关键角色。
我的保留:基础设施的残酷现实
不过...我不是盲目看涨。
AI基础设施brutally expensive,加密叙事alone don't create sustainable revenue。企业客户关心正常运行时间、延迟、可靠性——不仅仅是去中心化口号。这可能是OpenLedger未来最大的挑战。
"可支付AI"在演示中运行漂亮,但在真实推理经济中扩展是完全不同的问题。这种不确定性正是我只开小仓位的原因。
"产品交付、价格睡觉":基本面被叙事压制
让我意外的是:主网跑了6个月,1月跟Story Protocol谈了合规AI数据合作,测试网节点超10万,日均推理10万次。产品节奏在动,但代币价格完全没反应。
这种"产品交付、价格睡觉"的脱钩说明——当下定价逻辑由情绪和宏观主导,基本面还没轮到发言。这不是坏事,是观察期。
我的原创框架:接下来6个月的"价值证明窗口"
如果你认可"贡献者资本主义"的长线逻辑,现在不是抄底期,是验证期。因为你赌的不只是OpenLedger跑不跑得通,还是两个问题:
第一,真实企业付费意愿。不是测试网交互量,是像Sony、LA Times、Walmart这样的企业客户是否真正为"可支付AI"买单。
第二,验证者网络的去中心化程度。1200多个节点分布全球是起步,但能否抵抗女巫攻击?能否在AI推理高峰时保持稳定?这决定了"链上结算层"是玩具还是基础设施。
我盯的信号有三个:
看企业客户从"试点"变"量产"的时间表;
看Datanet的实际付费调用量,不是免费测试;
看OPEN质押率是否随生态增长而上升。
我的铁血研判:代码比口号诚实
OPEN的价格波动,表面是市场情绪,实际是"可支付AI"叙事与真实采用之间的时差。团队和社区61.71%的分配不是"恶意控盘",是写进合约的规则。
但更深一层,市场也在测试一个命题:当AI代理开始替代人类工作时,价值分配能否比旧世界更公平? OpenLedger的"可支付AI"是在为这个问题写代码答案——每次调用自动结算,每个贡献链上可追溯,没有中间商抽水。
这让我重新理解了一个老道理:在AI经济里,代码比口号诚实,结算比模型重要。
所以,当你盯着OPEN的K线,犹豫要不要进场时,不妨问问自己:你愿意生活在一个AI白嫖你的数据、平台赚走所有钱的世界,还是一个每次调用都自动给你分润的世界?
这话我说给自己听的,也可能算走眼了。但在一个贡献者越来越清醒的市场里,假装看不见价值分配问题的人,往往是最后被问题教育的人。