Ich habe mich damit beschäftigt, wie Openledger die Datenattribution handhabt, und ich versuche immer noch, die saubere Architekturgeschichte von der chaotischen operativen Realität zu trennen. Was meine Aufmerksamkeit erregte, ist, dass Openledger nicht nur "AI-Daten on-chain" anbietet, was für sich genommen bedeutungslos wäre. Die interessantere Idee ist, On-Chain-Aufzeichnungen zu verwenden, um zu koordinieren, wer Daten beigetragen hat, wer sie genutzt hat und wie die Belohnungen fließen sollten, wenn diese Daten Modelle oder Anwendungen unterstützen.
Die meisten Leute denken, Openledger ist nur ein weiteres AI + Krypto-Token, bei dem Nutzer Datensätze hochladen, Belohnungen verdienen und hoffen, dass später Modellbauer auftauchen. Ehrlich gesagt, das könnte immer noch das Haupt-Risiko sein. Aber die wohlwollendere Lesart ist, dass Openledger versucht, eine Koordinationsschicht für AI-Lieferketten aufzubauen: Mitwirkende, Kuratoren, Modellentwickler und Anwendungen, die alle über ein gemeinsames Attributions- und Abrechnungssystem interagieren.
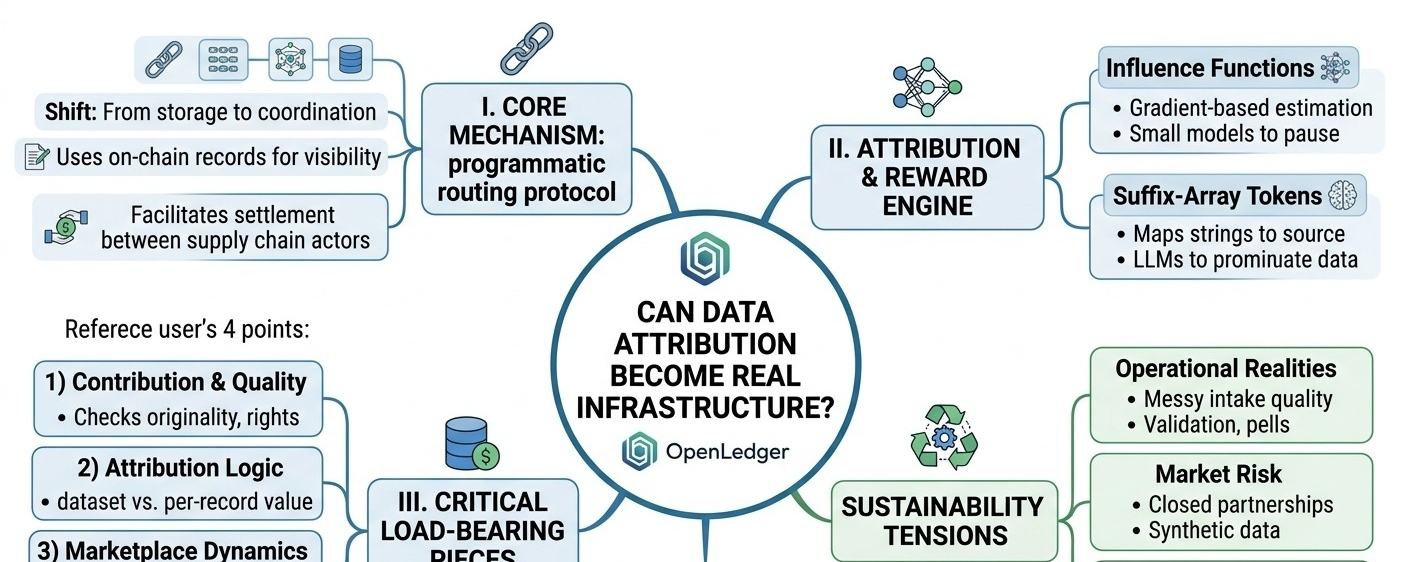
Einige Teile scheinen tragend zu sein:
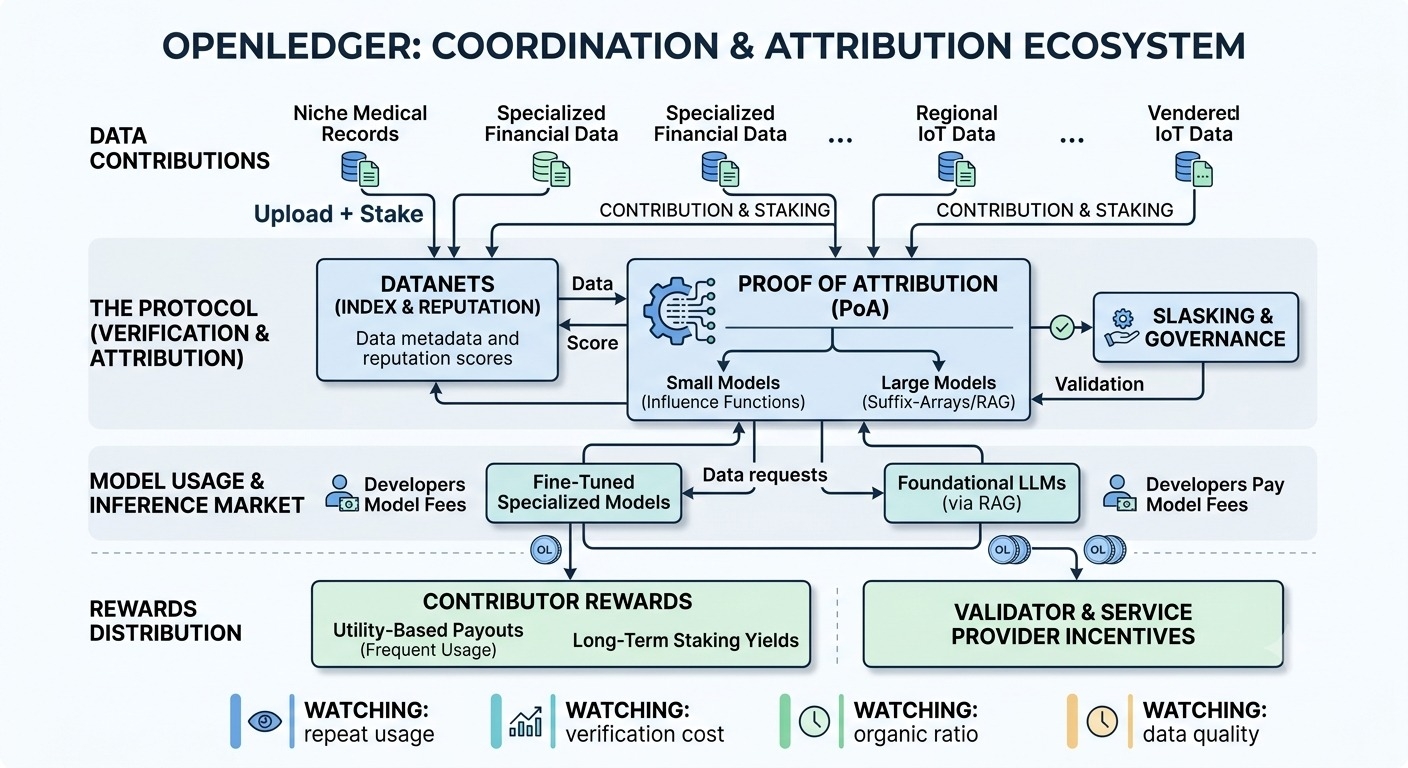
1) Dezentralisiertes Datensystem für Beiträge
Die tatsächlichen Daten können wahrscheinlich nicht vollständig on-chain leben, daher ist das praktische Setup Off-Chain-Speicherung mit On-Chain-Hashes, Metadaten, Lizenzbedingungen und Mitwirkendenaufzeichnungen. Das ist normal. Der schwierige Teil ist nicht die Speicherung, sondern die Qualität der Eingabe. Wer überprüft, ob ein Datensatz original, korrekt beschriftet, rechtefrei und nicht einfach als Schrott unter einem neuen Namen verpackt ist? Openledger kann Validatoren, Staking, Reputation und Audits nutzen, aber diese Systeme müssen stark genug sein, um Spam zu stoppen, ohne sich in eine kleine Gruppe inoffizieller Torwächter zu verwandeln.
2) Zuordnung + Belohnungsmechanismus
Und das ist der Teil, über den ich immer wieder nachdenke. Zuordnung klingt einfach, bis man fragt, was tatsächlich zugeordnet wird. Wenn ein Modell auf fünf Datensätze trainiert, die Hälfte der Proben filtert, den Rest anpasst und dann später erneut feinabstimmt, wie weist man den Wert zu? Echte pro-Datensatz-Beiträge sind sehr schwer. Die realistischere Version ist wahrscheinlich die Zuordnung auf Datensatz- oder Tranchenebene: Ein Trainingslauf verweist auf bestimmte Datensatz-Hashes, die Nutzung wird protokolliert oder bestätigt, und die Belohnungen werden gemäß einer vereinbarten Formel aufgeteilt. Nützlich, ja, aber kein Zauber. Es hängt stark von ehrlicher Nutzungsberichterstattung, Audits und Strafen für Unterberichterstattung ab.
3) Dynamik des KI-Modells / Marktplatzdaten
Der Marktplatz funktioniert nur, wenn es echte Käufernachfrage gibt, nicht nur Aktivität von Mitwirkenden. Ein realistischer Anwendungsfall könnte ein Team sein, das ein Kundenservicemodell für unterversorgte Sprachen aufbaut. Sie benötigen genehmigte Audioaufnahmen, Transkripte, Korrekturen und domänenspezifische Labels. Zentrale Anbieter können einiges davon bereitstellen, aber die Herkunft ist oft undurchsichtig und Mitwirkende teilen selten im nachgelagerten Wert. Das Angebot von Openledger ist im Grunde: Mach die Datenversorgungskette sichtbar genug, damit Zahlungen zurückgeleitet werden können, wenn das Modell trainiert oder verwendet wird. Das ist eine kohärente Idee, aber Käufer müssen immer noch glauben, dass die Daten besser, sicherer oder günstiger sind als bestehende Beschaffungswege.
4) Token-Anreize + Verifizierung/Skalierbarkeit
Der Token scheint mehrere Aufgaben zu erfüllen: Die Bereitstellung von Mitwirkenden, die Belohnung von Validatoren, die Koordination von Staking/Slashing und möglicherweise die Abwicklung von Marktplatz-Zahlungen. Ich bin ein wenig skeptisch, wenn ein Token jedes Koordinationsproblem lösen muss. Frühe Emissionen können Aktivität erzeugen, aber sie können auch Leute anziehen, die auf Belohnungen optimieren, anstatt auf Nützlichkeit. Bei der Skalierbarkeit erfolgt die Modellnutzung off-chain, daher benötigt Openledger wahrscheinlich eine gebündelte Abwicklung: unterschriebene Nutzungsquittungen, regelmäßige Zwischenstände, vielleicht vertrauenswürdige Ausführung oder Drittanbieter-Bestätigungen. Wenn die Verifizierung schwach ist, wird die Zuordnung mehr wie Buchhaltungs-Etikette als durchsetzbare Infrastruktur.
Wer schafft hier tatsächlich Wert? Nicht "jeder, der Daten hochlädt." Wert kommt von Mitwirkenden mit knappen, rechtlich nutzbaren Daten; Kuratoren, die das Corpus sauber halten; Validatoren, die die Herkunft vertrauenswürdig machen; und Käufern, die echten Geldfluss bringen. Openledger trifft eine ziemlich spezifische Annahme: dass die Nachfrage nach KI weiterhin auf spezialisierte Modelle zusteuert, die frische, nachverfolgbare, domänenspezifische Daten benötigen. Plausibel, aber nicht garantiert. Wenn Modellbauer mehr auf geschlossene Partnerschaften, synthetische Daten oder interne Datensätze angewiesen sind, könnte die Nachfrage auf dem offenen Marktplatz dünner sein, als es das Anreizdesign erwartet.
Die Spannung ist Nachhaltigkeit. Wenn die Auszahlungen an Mitwirkende überwiegend Token-Emissionen zu lange sind, kann das Netzwerk gesund aussehen, während es qualitativ minderwertigen Bestand ansammelt. Duplizierte Datensätze, faules Labeln, gefälschte Nutzung und subtile Datenvergiftungen sind rational, wenn die Belohnungen auf flachen Metriken basieren. Und wenn die Zuordnung nur funktioniert, wenn ein paar vertrauenswürdige Validatoren alles genehmigen, könnte das System leise wieder in das zentrale Plattformmodell abdriften, das es zu vermeiden versucht.
Noch keine perfekte Schlussfolgerung. Openledger könnte eine echte KI-Koordinationsschicht aufbauen, aber es muss beweisen, dass die Zuordnung im großen Maßstab vertrauenswürdig ist und dass Käufer Belohnungen mit tatsächlicher Nutzung finanzieren, nicht nur mit zukünftigen Erwartungen.
Beobachtung:
- Anteil der Mitwirkendenbelohnungen, finanziert durch Käufergebühren vs. Token-Emissionen
- Ablehnung von Datensätzen, Duplizierung und Label-Audit-Raten
- Konzentration von Validatoren und echte Streitigkeiten
- Wiederholungskäuferaktivität, die mit Produktionsschulung oder Inferenz verbunden ist
Die Frage für mich ist: Kann Openledger ehrliche Zuordnung zum einfachsten Weg für Modellbauer machen, oder wird es ein zusätzliches Übergewicht, das sie umgehen, wenn echtes Geld im Spiel ist?