If you trade long enough, you learn that price isn’t the only thing that moves markets. Infrastructure does too. In October, two shocks made that painfully clear. First came the record liquidation cascade on October 10–11, which wiped out roughly $19.3B in leveraged positions within hours. Ten days later, a fresh AWS outage rippled through core crypto services, throttling APIs and reminding everyone how much of “decentralized finance” still leans on a few centralized pipes. Put together, these events form a single lesson: your edge is not just your thesis—it’s your plumbing.
The First Event
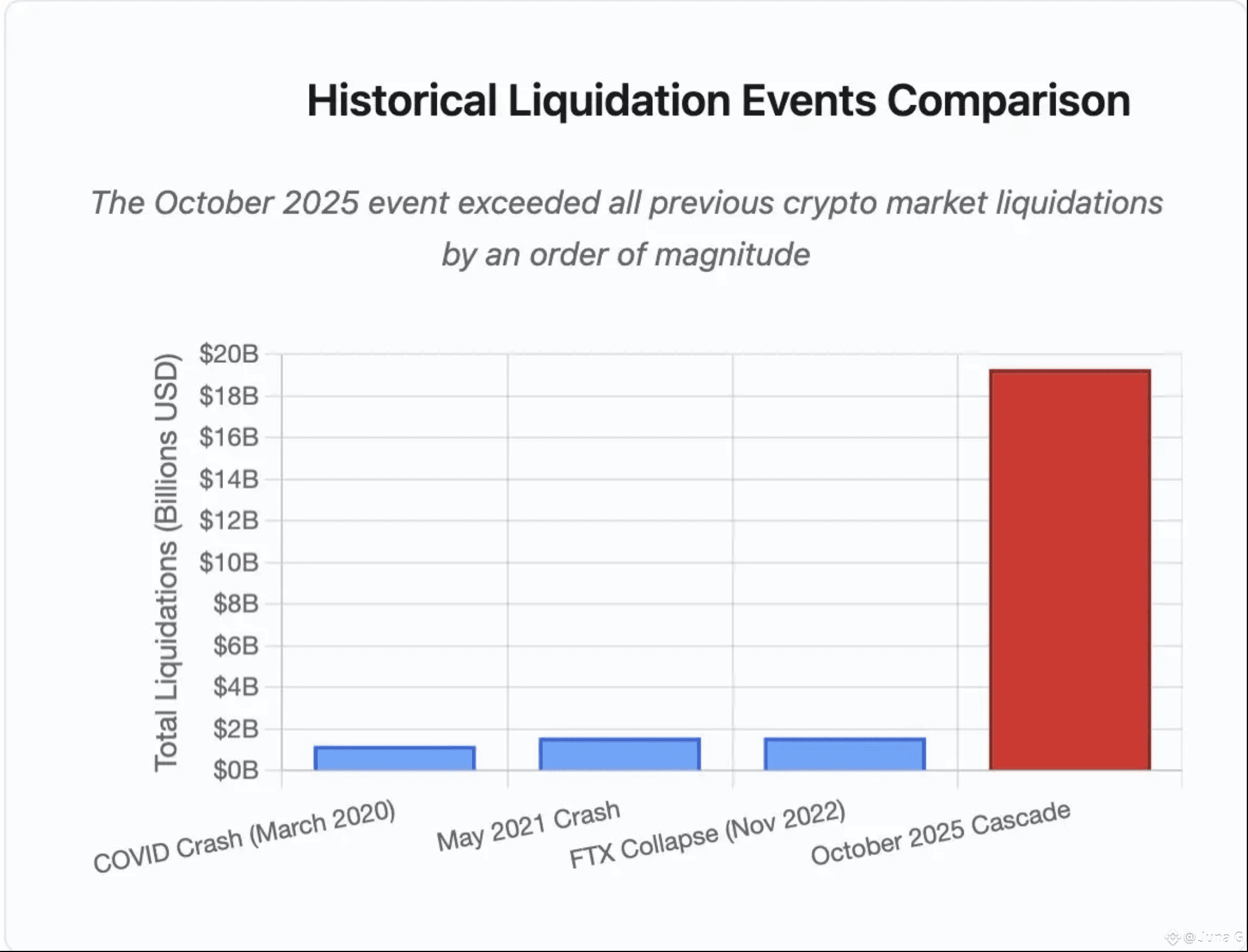
On October 10–11, a waterfall of forced unwinds spread across venues. Open interest was high, liquidity was thin, and a handful of mechanical failures turned volatility into a cascade. Multiple analyses put the total at about $19–20B in forced liquidations—an order of magnitude larger than prior episodes in 2020, 2021, and 2022. The most damaging pathways weren’t only price-driven; they were infrastructure-driven: API throttling during peak stress, fragile oracle design, and last-resort mechanisms like ADL that socialize losses to profitable accounts.
 Source: PANewLab
Source: PANewLab
A particularly sharp edge case involved wrapped and synthetic collateral on at least one major venue. When local spot books for assets like USDe gapped—briefly trading around $0.65 in a stressed market while staying closer to $1 elsewhere—systems that marked collateral strictly to their own venue’s spot price began writing down otherwise sound positions. That haircut triggered margin calls, which triggered liquidations, which shoved more sells into the same thin books, a circular amplifier we’ve seen before in traditional markets, but with crypto-speed reflexes. Post-mortems since then have corroborated the local depeg and the pricing-model gap.
As the dust settled, venues started to adjust. Binance, for example, said it would review affected accounts and announced changes to how wrapped assets are priced—moving toward conversion-ratio or more robust oracle-style inputs to avoid reflexive write-downs during venue-specific distortions. For traders, the headline is simple: when your collateral valuation depends on a single venue’s spot tick, you are exposed to “local truth” instead of “network truth.” In panics, local truth can be dangerously wrong.
Then AWS sneezed and half the internet caught a cold
On October 20, Amazon Web Services had a bad morning in its US-EAST-1 region. Increased error rates and latency around core services like DynamoDB, EC2, and Lambda caused outages and degraded performance across countless apps, including trading-adjacent infrastructure. Even outside of crypto, the incident disrupted household names; inside crypto, it slowed or stalled critical services that traders depend on for price discovery, portfolio syncing, alerts, and execution. AWS identified the fault domain and began recovery within hours, but the point was made: a lot of “on-chain life” still flows through a very off-chain throat. Source: PANewsLab
Source: PANewsLab
If you think of the October 10–11 liquidation as an exchange-layer failure mode, the October 20 outage was a cloud-layer failure mode. Both bottlenecks create the same trading outcome: when you most need to act, you can’t. Orders time out. Stop-losses fail to trigger. Position summaries lag your real risk. And each delayed packet is a subsidy to the side of the market that can still act.
On-chain wasn’t immune either
Stress revealed brittle points at multiple protocol layers. High-throughput chains like Solana have taken visible steps forward, but history shows that spam floods and voting bottlenecks have, at times, pinned throughput or stalled finality for hours. Rollups introduced their own chokepoints: when a single sequencer or sorter takes all the inbound traffic (think airdrop claim tsunamis), it becomes a heat sink for the entire L2. Meanwhile, when Ethereum fee markets turn into bidding wars, MEV competition pushes gas into the stratosphere exactly when retail needs to add collateral or close positions. None of these dynamics are new; October just stacked them on the same timeline.
What this means for us traders
1. Reduce dependence on a single truth source. If a venue’s mark price is your margin gospel, consider routing or hedging on a second venue that uses cross-venue TWAP or a resilient multi-source oracle. A small cross-venue hedge can be the difference between “margin call” and “minor drawdown.”
2. Treat API rate limits as a market-structure variable. During stress, exchanges throttle endpoints to keep systems alive. Assume you will get fewer position updates and more timeouts. Plan around it: queue fewer, larger risk actions (flatten, reduce leverage, add collateral) rather than spamming small orders that all die in the same bottleneck.
3. Know the venue’s ADL and insurance-fund mechanics. If insurance funds are small relative to open interest, profitable positions can be forcibly closed to plug holes. Read the venue’s current parameters before you size. “ADL risk” is not theoretical; it’s a line item in your P&L variance during extremes.
4. Have a “cloud outage” mode. Keep at least one broker/exchange and one data/alert stack that do not share identical cloud dependencies, and have mobile + desktop fallbacks. It’s not perfect diversification, many services use the same providers, but partial independence beats none.
5. Pre-commit your “do less” button. Tighten maximum leverage and auto-reduce position sizes during defined stress signals: latency spikes, order rejections, or a pre-set spread threshold between venues. When the pipes narrow, throttle yourself before the venue throttles you.
6. Stagger stops, don’t cluster them. If your stops sit at the same levels as everyone else’s, you become the fuel for the next thin-book air pocket. Layer stops and use alerts to opportunistically reduce rather than binary flushes.
7. Keep a small cash buffer on multiple rails. A little dry powder on a second venue or chain can save a good position when the primary rail jams. The spread you pay in quiet hours is the premium for speed in loud hours.
What this means for builders and venues
Price the network, not the book. If a wrapped or synthetic asset’s collateral value is marked to a single order book, your users are implicitly short your local liquidity. TWAP across multiple venues, use well-designed decentralized oracles, and add “circuit-breaker” logic for abnormal venue divergence. Several large venues have already moved in this direction or announced transitions post-crash; keep pushing.
Declare and test failure modes. Publish rate-limit policies up front. Run war-games that include 100× normal order flow and 1,000× positions queries. Share recovery SLOs: how long until additional gateways spin up? What’s the path if your primary cloud region dies? Traders can price risk if you disclose it; they can’t if you hide it.
Diversify your cloud and cache layers. Multi-region, multi-provider redundancy is expensive, but so are mass liquidations and reputational hits. Even partial independence—warm standby in a second region/provider for core services like matching, risk, and mark pricing—can remove the single-point-of-failure tail. October’s outage made that trade-off concrete.
Strengthen ADL alternatives. Larger, transparently funded insurance pools; properly parameterized auto-deleveraging bands; and fair social-loss rules reduce the chance that profitable accounts become sacrificial. It’s not enough to promise coverage thresholds during quiet markets. Stress tests should reflect real open interest and liquidity distributions observed in panics.
Give users a status page that tells the truth. When a chain or venue is struggling, the worst experience is silence. Third-party monitors help, but first-party transparency is better. Status pages with latency, error rates, API health, and clear RCA updates turn chaos into information.
The deeper pattern: trilemma meets reflexivity
Developers talk about the decentralization-security-scalability trilemma, but traders live inside its trade-offs. Centralized exchanges scale cheaply and feel smooth, until throttles kick in. High-throughput chains fly, until spam cannons arrive and consensus stalls. Ethereum’s base layer is resilient, until MEV competition plus a rush for blockspace prices out the very users who most need to act. Rollups cut fees, until a single sequencer becomes a choke point. These are not contradictions; they’re the bill for design choices. October simply presented the invoice all at once.
How to turn this into an edge
Most traders chase alpha by getting better at ideas. In the next cycle, a quieter edge may come from getting better at operations. If your playbook assumes perfect data, instant execution, and cheap gas, you’re optimized for yesterday’s conditions. The traders who thrive will do unglamorous things: test failovers; maintain two alert stacks; practice “panic drills” on small size; know exactly how their venue prices collateral; and automate leverage caps that shrink when latency and slippage spike.
You can’t fix the cloud. You can’t eliminate MEV. You can’t force an exchange to triple its insurance fund tomorrow. But you can design your strategy so that when the pipes narrow, your downside narrows with them. That won’t make headlines. It will, however, keep you in the game, and in markets where liquidity disappears and returns concentrate in a handful of sessions per year, survival is alpha.
October’s double-punch wasn’t just a scare. It was an audit. The mark was not for your market view; it was for your system’s resilience. If you didn’t like the grade, the fix is clear: diversify your truth sources, pre-commit to doing less in chaos, and build operational depth before you need it. The next “invisible bomb” is already ticking somewhere in the stack. Your job isn’t to guess the hour; it’s to make sure that, when it goes off, you’re still standing.