每個人都說人工智能無處不在。但它到底是什麼?機器的大腦,類固醇上的計算器,還是一個停留太久的流行詞?要回答這個問題,讓我們回到大腦,然後看看機器是如何試圖模仿它的。
大腦解決問題的方式
你的大腦是一個預測引擎。當你作爲一個孩子觸摸火焰時,你的神經元相互連接以記住疼痛。當你看到一隻狗時,你的大腦並不會檢查規則手冊。相反,數百萬個神經元以編碼你過去“狗性”的經歷的模式激發。
這就是智能:從經驗中概括的能力。機器也想這樣做。第一次嘗試不是建造神經元,而是編寫規則。如果火 = 熱,就不要觸摸。如果狗 = 四條腿、尾巴、叫,則分類為狗。這被稱為符號AI,一個手工邏輯的世界。
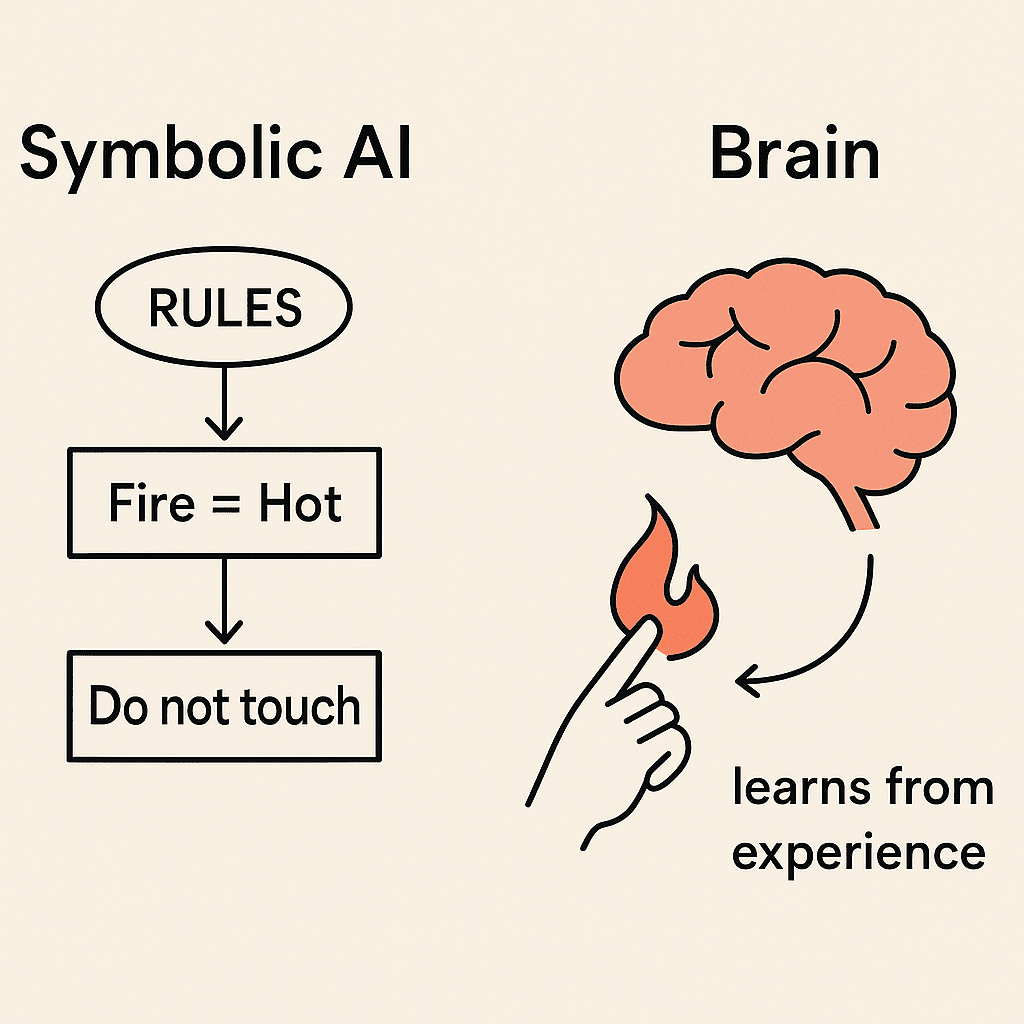
它對狹窄的問題有效,但當現實變得混亂時卻崩潰。大腦在混亂的情況下茁壯成長,而規則則無法。
了解更多:
人工智慧的歷史(維基百科)
達特茅斯會議:人工智慧誕生之地
在1956年夏天,約翰·麥卡錫、馬文·明斯基、克勞德·香農和納撒尼爾·羅徹斯特在達特茅斯學院舉行了達特茅斯夏季人工智慧研究項目。
在這裡,‘人工智慧’這個術語首次被提出。提案中指出:
“學習的每個方面或任何其他智能特徵都可以在原則上如此精確地描述,以至於可以製造出模擬它的機器。”
這不是一次編碼黑客馬拉松。這是為一個領域製定的藍圖,指向神經網絡、搜索、符號推理和語言。夢想已經確立。
了解更多:
達特茅斯會議
從規則到學習:感知器
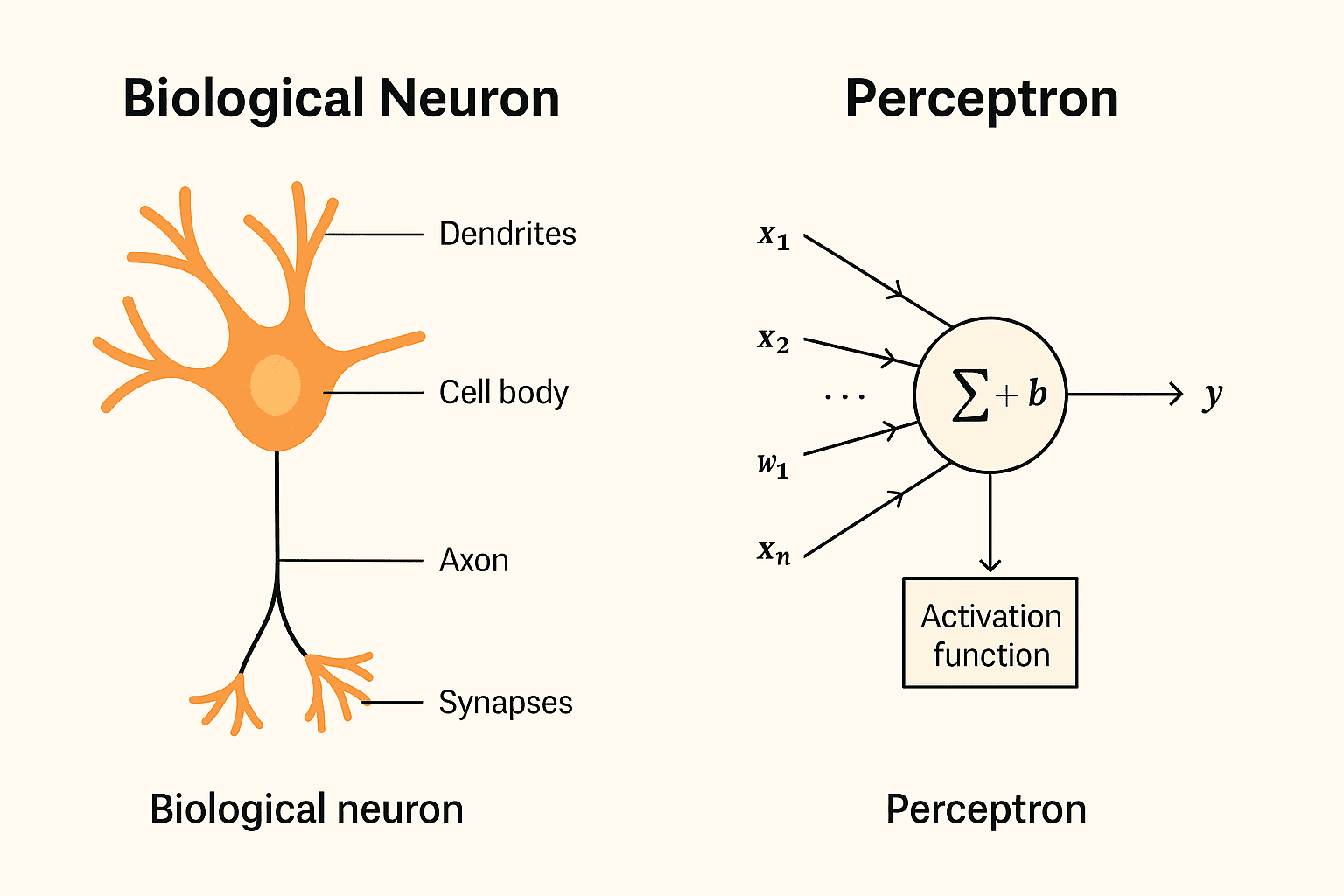
1957年,弗蘭克·羅森布拉特問道:如果機器能像神經元一樣學習會怎樣?他介紹了感知器,這是第一個神經元的數學模型。
感知器接受輸入,將其乘以權重,加上偏差,然後經過步驟函數:
f(x) = h(w ⋅ x + b)
輸入 (xi) = 特徵,如像素值
權重 (wi) = 每個特徵的重要性
偏差 (b) = 調整決策邊界
步驟函數 (h) = 二元輸出 (1 或 0)
這使得感知器成為一個線性分類器,能夠在類別之間劃出一條直線邊界。
羅森布拉特還建造了硬件:馬克I感知器(1960年)。它有一個20×20的光電池網格,像視網膜一樣,隨機連接到聯想單元,並由可調電位器實現可調權重。馬達在學習過程中更新這些權重。
它能夠分類簡單的模式,並激發了巨大的興奮。《紐約時報》甚至聲稱它有一天可以行走、說話,並具備意識(
《紐約時報》檔案,1958年)。

但它有局限性:它無法解決像XOR這樣的問題,因為這些問題無法線性分離。
📖 了解更多:
感知器(維基百科),
羅森布拉特的1958年論文(PDF)。
語言模型和下一個單詞預測
與此同時,一個非常不同的想法正在醞釀。機器能否預測文本,而不是用邏輯推理?
克勞德·香農(1948–1951):通過要求人類猜測下一個字母來測量英語的熵。這證明了語言在統計上是可預測的。
N-grams(1960年代–1970年代):不進行完整推理,而是通過查看最後幾個單詞來進行近似。三元組模型預測P(wt | wt−2, wt−1)。
語料庫:布朗語料庫(1961年)提供了100萬字的文本,使統計模型得以測試。
應用:1970年代IBM和貝爾實驗室的早期語音識別實驗使用n-gram模型及平滑方法,如古德-圖靈和後來的克內瑟-奈。
這很重要,因為現代LLM仍然使用相同的目標:預測下一個標記。區別在於規模和神經架構,而不是目標。
了解更多:
點擊這裡!
符號AI和專家系統
在達特茅斯和感知器之後,早期的幾年由符號AI主導。研究人員建立了專家系統:將領域特定知識編碼為邏輯規則的程序。
示例:MYCIN(1972年)在斯坦福大學。它使用約600條規則來建議針對感染的抗生素。在狹窄的情況下,它的表現與醫生一樣好。
但符號AI面臨知識獲取瓶頸。為混亂的現實世界領域編寫和維護規則變得不可能。這開始了在不同方式中尋找替代方案的探索。
Prolog:邏輯編程
在1972年,阿蘭·科爾梅勞和菲利普·魯索介紹了Prolog(“邏輯編程”)。與命令式編程不同,Prolog是聲明式的。你編寫事實和規則,系統推導出答案。
示例:
cat(tom)。
mouse(jerry)。
hunts(X, Y) :- cat(X), mouse(Y)。
查詢:?- hunts(tom, jerry)。→ true
Prolog促進了符號AI,並且是日本第五代計算機計劃(1982-1992)的核心,該計劃投入了4億美元來建造智能推理機器。
機器學習:數據成為教師
📖 進一步閱讀:統計學習理論 – 瓦普尼克,機器學習基礎 – 莫赫里、羅斯塔米扎德、塔爾瓦卡
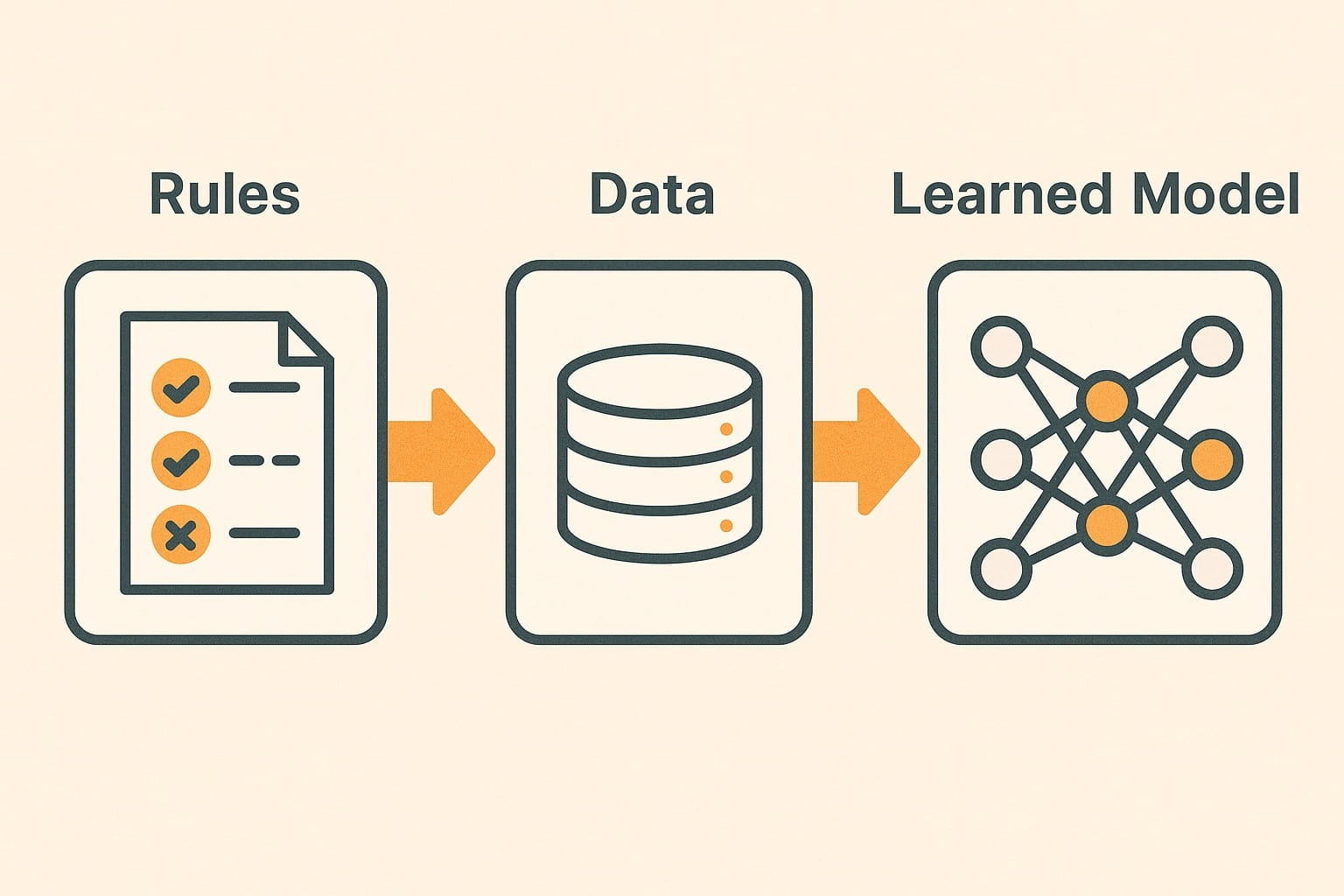
到1980年代,符號AI陷入困境。規則無法捕捉現實世界的無窮混亂。新的想法是激進的:與其手動編寫規則,不如向系統提供數據,讓算法自行發現規則。
這標誌著機器學習的誕生。這一轉變不僅是哲學上的,還是深刻的數學上的。弗拉基米爾·瓦普尼克和阿列克謝·切爾馮尼基斯通過統計學習理論形式化了這一思想。
核心問題是泛化:給定有限的訓練數據集,模型如何能對未見過的案例做出準確的預測?瓦普尼克和切爾馮尼基斯引入了關鍵思想:
VC維度:模型類別的容量測量
經驗風險最小化(ERM):最小化訓練錯誤
結構風險最小化(SRM):平衡訓練錯誤與模型複雜性,以避免過擬合
這使機器學習成為一門科學,而不是猜測。
早期算法:樹、貝葉斯和邊際
一旦理論就位,實用算法開始塑造行業。
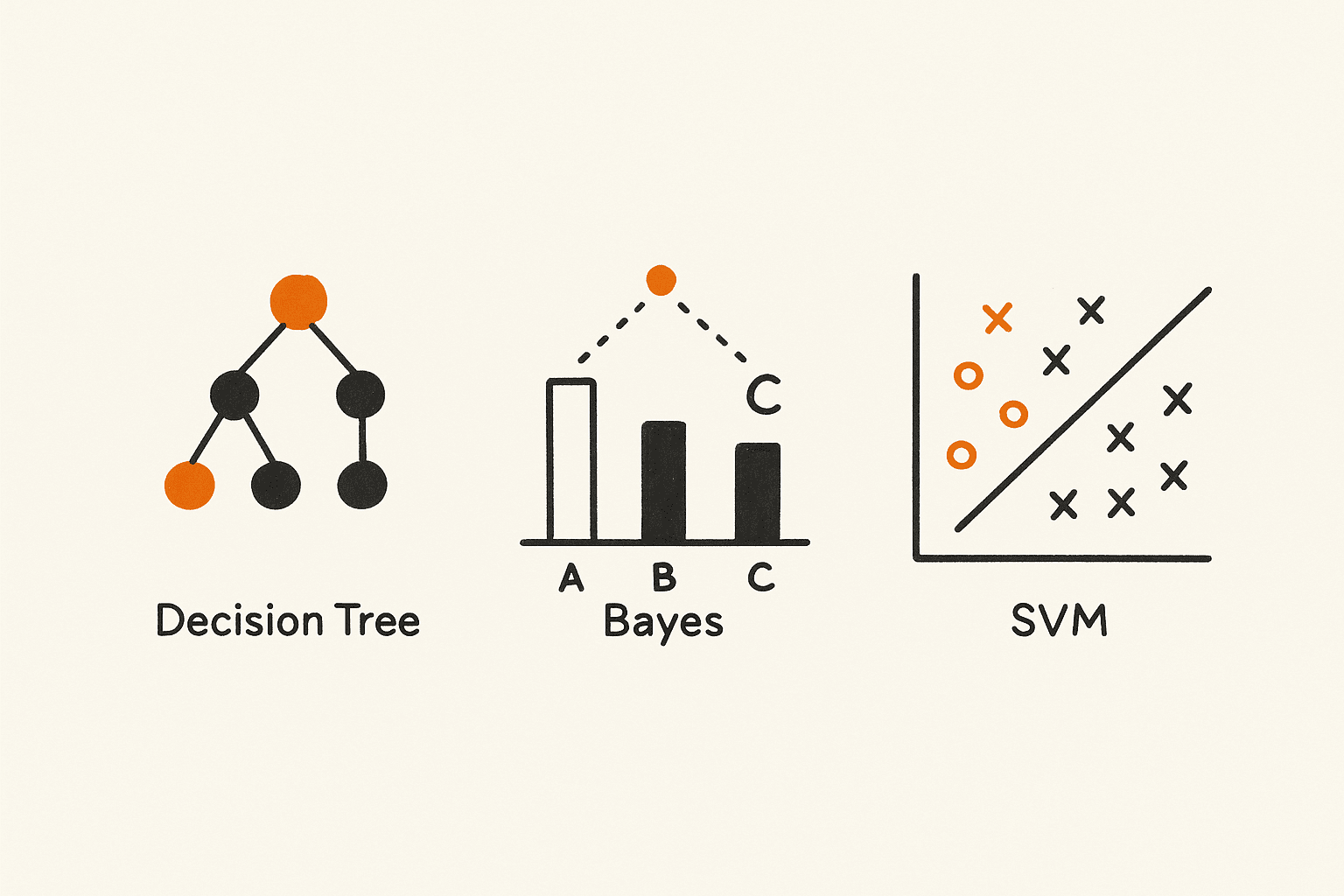
決策樹
羅斯·昆蘭於1986年介紹了ID3。決策樹一步一步地拆分數據,直接從示例中創建如果-則規則。它們是可解釋的,並在詐騙檢測、醫療診斷和客戶細分中非常有用。
朴素貝葉斯
根植於貝葉斯定理,朴素貝葉斯假設特徵是獨立的。儘管這個簡化,它在文本分類中表現良好。在1990年代,它推動了垃圾郵件過濾器和文件分類的規模。
支持向量機(SVM)
由瓦普尼克於1990年代介紹,SVM旨在通過最大化邊距來找到最佳分隔類別的超平面。它們在手寫識別、人臉檢測和生物信息學中表現出色,顯示出在高維空間中的強泛化能力。
📖 了解更多:
決策樹學習(維基百科),
朴素貝葉斯(維基百科),
支持向量機(維基百科)。
網絡和反向傳播的突破
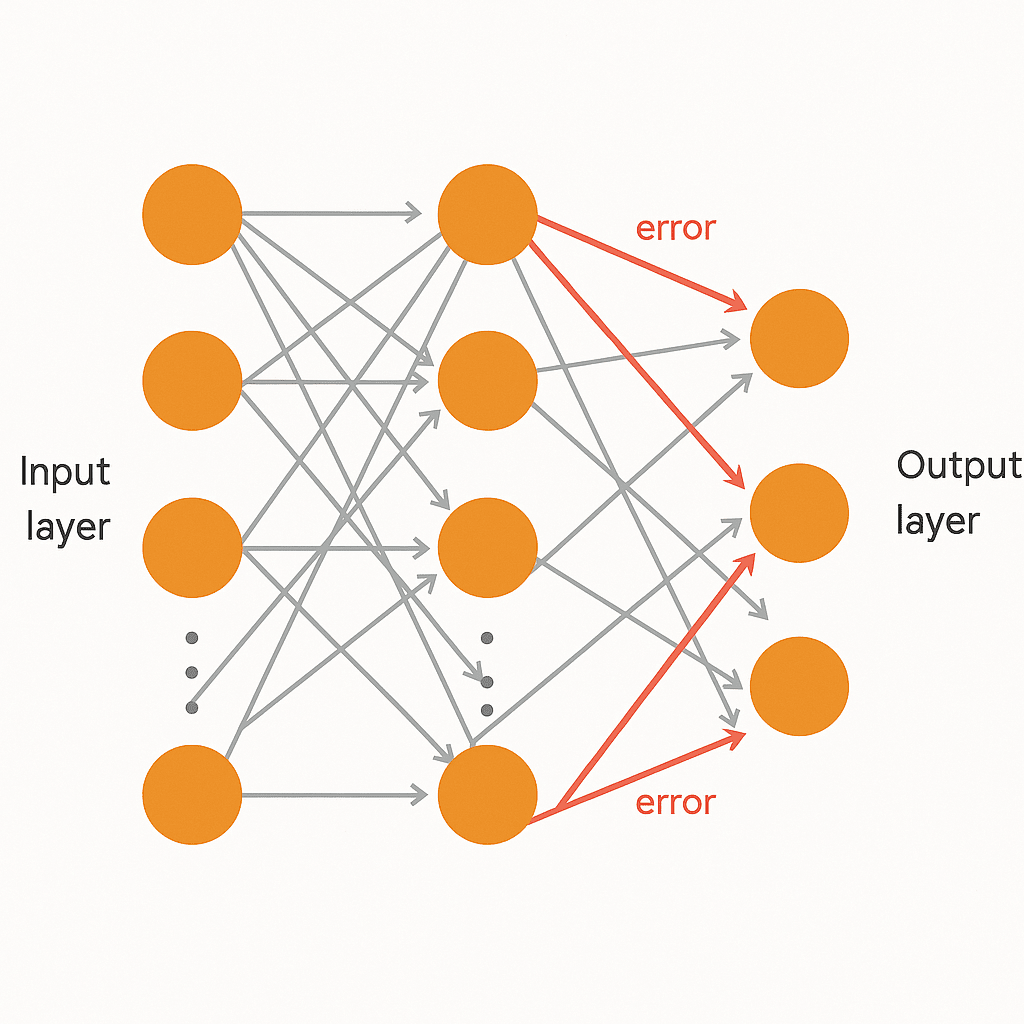
人類大腦以層次的方式構建理解:從邊緣到形狀再到物體。單個感知器無法做到這一點,但多層感知器(MLP)可以。
1986年,拉梅哈特、辛頓和威廉姆斯普及了反向傳播,這是一種訓練這些多層網絡的方法。從輸出層的錯誤向後傳播,逐步調整早期層的權重。
反向傳播使用梯度下降,將權重推向減少錯誤的值。這使得多層感知器(MLP)足夠強大,可以近似幾乎任何函數,這一事實後來由通用近似定理證明。
雖然受到當時計算能力和小數據集的限制,反向傳播為後來主導人工智慧的神經網絡奠定了基礎。
了解更多:
反向傳播(維基百科)
結論:現代AI的舞台
到1990年代,人工智慧站在兩個堅實的支柱上。一方面,像決策樹、朴素貝葉斯和支持向量機的機器學習算法在金融、醫療保健和電信領域推動了應用。另一方面,具有反向傳播的神經網絡理論上具有逼近幾乎任何事物的能力,但受到數據和計算能力的限制。
與此同時,還有一個更安靜但同樣重要的語言建模線索。從克勞德·香農早期的可預測性實驗到n-gram模型和語音識別研究,預測下一個單詞的想法成為捕捉語言模式的一種實用方法。
當2000年代出現大型數據集並且GPU解鎖規模時,這三股潮流開始融合。數據驅動算法、具有反向傳播的神經網絡以及下一個單詞預測的傳統合併成了我們現在稱之為深度學習的東西。
感知器的謙卑起源、統計學習理論的嚴謹性、反向傳播的突破以及語言建模的持久性共同創造了現代人工智慧的基礎。
在下一篇博客中,我們將探討神經網絡如何演變為卷積神經網絡(CNN)、遞歸神經網絡(RNN)和深度學習,以及計算和數據瓶頸如何為變壓器的誕生奠定基礎。


