進入幣圈10年了,才進圈的時候虧得一塌糊塗,中途呢有虧有賺,到現在全靠幣圈養家🛫
總結了也下經驗分享給大家,希望對你有所幫助,只要你能做到想虧都難,僅供參考!
如果給幣圈一個定義,你會怎麼描述它?可能每個人都有不同的答案,但誰也無法證明自己的定義究竟是對還是錯。任何的說法都有它合理性的條件,任何說法也都有它不能適用的境遇,這就是“混沌”的本質。
在混沌的市場中很多人總是試圖去看清一切,但越是在市場中生存的時間久了,越能體會到市場本身就是無序的,“大道至簡”也許是面對市場最有效的原則。
那麼如何把炒幣做好呢?人一旦進入金融市場就很難回頭了,如果你現在虧損卻依舊迷茫,未來還打算把炒幣當做第二職業,就一定要知道“DPO指標戰法”,讀懂悟透一定能少走很多彎路, 都是切身經歷和感受,建議收藏,反覆揣摩!
DPO=優化chosen-rejected
DPO的計算過程大概如下
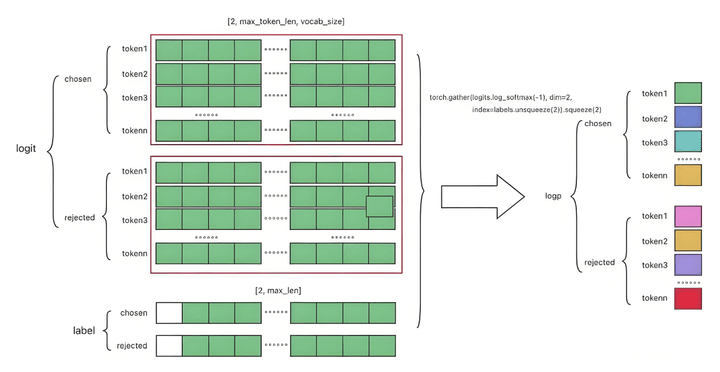
在DPO優化過程中, 對於chosen優化的方向是有不確定性的,DPO優化只保證整體的margin增大 ,而不是單一的讓chosen prob增大。
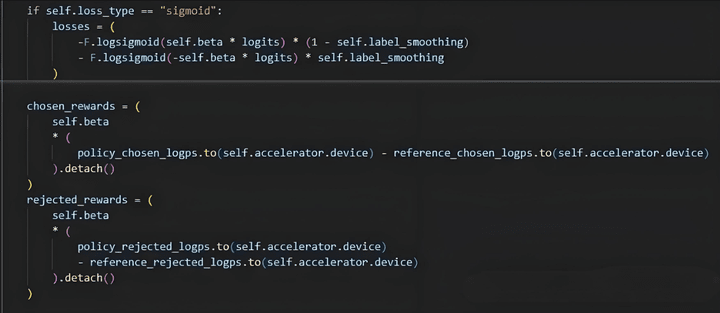
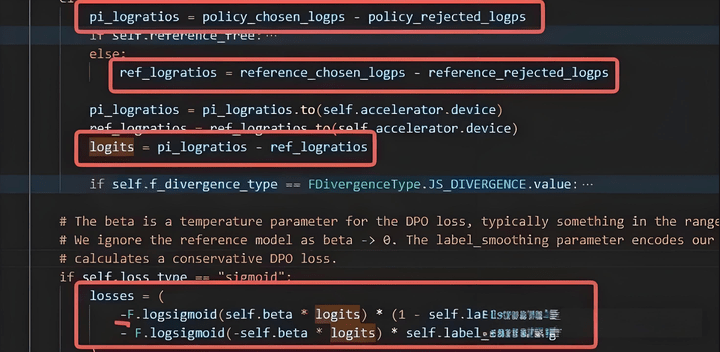
loss和chosen、rejected公式如下。
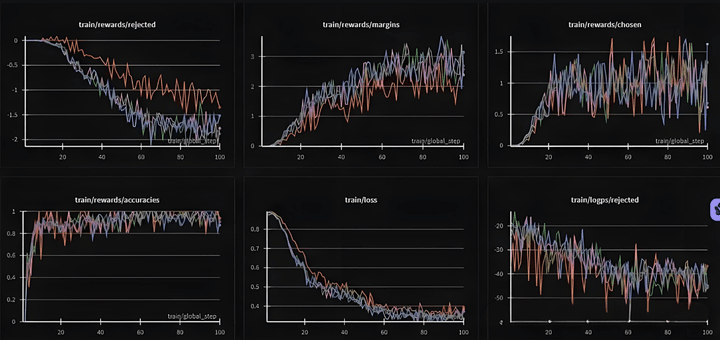
這裏採用了llama-factory自帶的dpo_en_demo數據集進行DPO訓練,可以看出rejected和chosen都是上升的,margin也在增加。
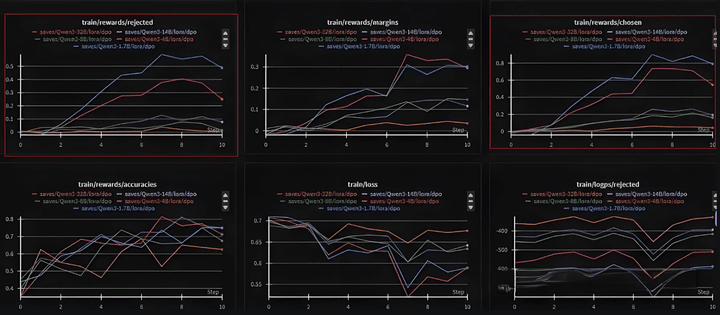
理想情況是chosen增大、rejected降低。但在數據不好/參數設置不合理的時候,就會出現chosen/rejected同時上升或者下降的情況。
下面更換Qwen2.5模型進行DPO訓練,可以看到chosen和rejected都在降低。
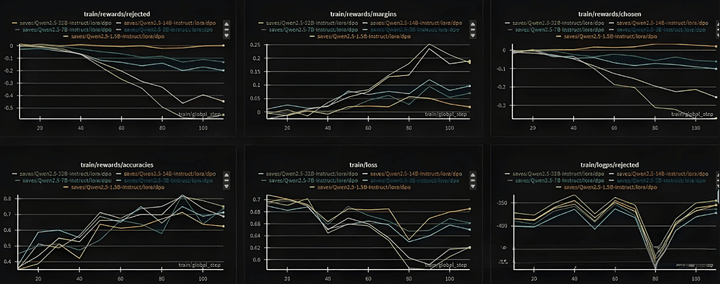
下面是採用實際業務數據得到的pair對,訓練SFT的Qwen2,5,並加權了部分SFT的loss,以使得模型權重結果不偏離原始模型太多。
其中chosen和rejected同時上升or下降的原因分析可參考:
小冬瓜AIGC:爲什麼DPO裏Chosen和Rejected概率會同時下降???
ChenShawn:【不靠譜】有關DPO訓練時,爲什麼chosen和rejected的reward一起下降的猜想
Sonsii:DPO及其衍生算法XX-ODPO訓練過程中出現chosen reward下降
從理論上分析,chosen_reward是model_chosen_logp - ref_chosen_logp,又因logp是每個next token的logits概率。chosen_reward變大就表示,相比於原始模型來說,更新後的模型在輸出next token=chosen token的概率變大,也就意味着模型的輸出正在接近chosen樣本。rejected增大同理。
那麼反過來講,chosen_reward減小,表明模型更新後,離chosen樣本輸出越遠。rejected也同理。
因此好的訓練效果是chosen_reward增大(輸出logits更接近),rejected_rewards變小(輸出logits離bad更遠)。除此之外,表明訓練數據pair對模型來說沒有足夠好的區分度。(總結來說,reward分數是相同樣本下,update_model和ref_model的變化方向(接近還是原理))#ETH突破4600
loss分數是update_model好壞之差和ref_model好壞之差的變化量。
loss變小意味着logits變大,若ref_logratios不變,則意味着update_model的好壞之差變大,若再假設policy_rejected_logps不變,則意味着更加接近chosen輸出policy_chosen_logps。#主流币轮动上涨
通常dpo訓練時,rejected樣本是模型輸出的,chosen是better模型優化的。那麼這裏就有一個問題,rejected是不是當前模型輸出的,對訓練效果有什麼影響?
基於上面分析,考慮ref_logratios不變的情況下,loss更新後,會導致update_model更接近chosen或者遠離rejected或者both(實際上肯定是both)。不管樣本如何,接近chosen肯定是ok的。但如果rejected不是sft模型產生的,那麼遠離一個本來就不會輸出的rejected(如同降低一個發生概率本身就爲0的概率)就沒有多大意義,這部分效果就丟失了,因此整個DPO的效果就打折了。
更直觀的說明就是:如同margin=chosen-rejected=0.5-(-0.3)=0.8,現在這-0.3的學習沒啥意義,0.8中只有0.5是真實有效的。
KTO:DPO->單邊學習
KTO: Model Alignment as Prospect Theoretic OptimizationLLM RLHF 2024論文(八)KTO
考慮到dpo的loss是優化margin,也就是chosen-rejected的差。可能會存在兩邊同時上升/下降,但margin仍然增加的情況。那麼考慮固定一邊,就可以優化另一部分的效果。比如rejected爲0,那麼優化margin就變成了優化chosen,固定chosen同理。

此時從reward優化方式變成了類似sft的優化方式(不再需要偏好數據),因爲接近SFT方式,所以可以在base模型上直接KTO訓練,但相比SFT來說,KTO需要有ref_model。#以太坊创历史新高倒计时
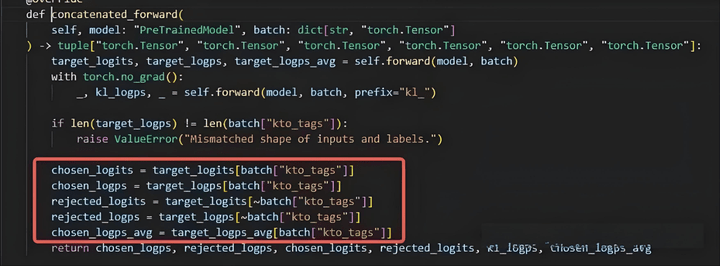
設置kto_tag,若爲true,則chosen數據保持不變,rejected_logits設置爲0,反過來則一樣。從而使得獨立處理兩種數據均有SFT效果,可以對正負樣本不均衡的數據進行訓練。
論文中說的HALO方法,其實可以不用管。
KTO和SFT對比:SFT的數據只能是good case,而KTO的數據可以是bad case。KTO需要ref_model。
DPO和KTO對比:且DPO可能會出現chosen_reward降低導致效果差的問題,而KTO則能保證模型一定更接近chosen的效果。DPO適合於chosen明顯都比rejected更好的pair數據。
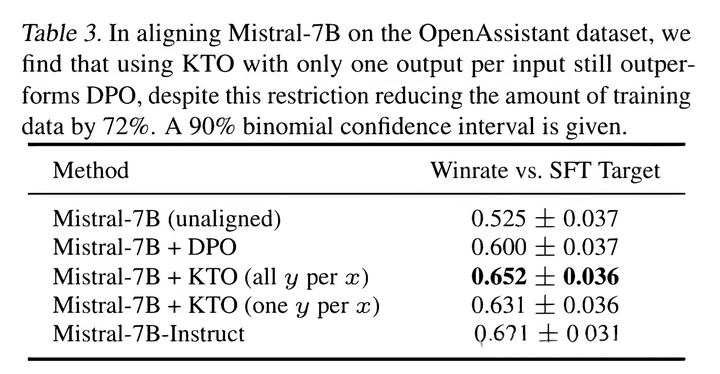
論文中說KTO的效果均比DPO要強。實際效果還是要看數據質量(目前個人實測是DPO要更好一點)。
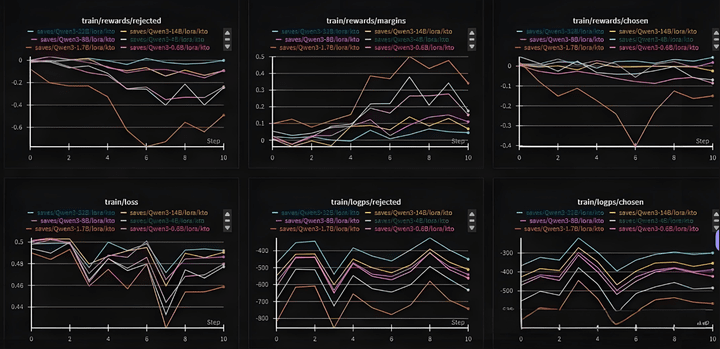
實際測試,chosen還是會略有下降。
ORPO:SFT+k*RL
ORPO: Monolithic Preference Optimization without Reference Model大模型的PPO、DPO偏好優化算法玩不起?那建議你看一下ORPO(更有性價比!)
ORPO在DPO的基礎上,去掉了ref_model,增加了賠率比(odds ratio)的loss。又結合了SFT的loss,將SFT和RLHF的過程合併成一個。
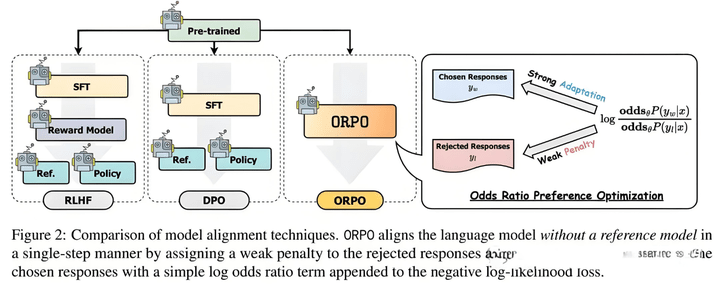
loss如下,首先定義odds,就是將原本的概率放的更大(加速模型更新)。然後定義OR loss,最終疊加SFT loss。
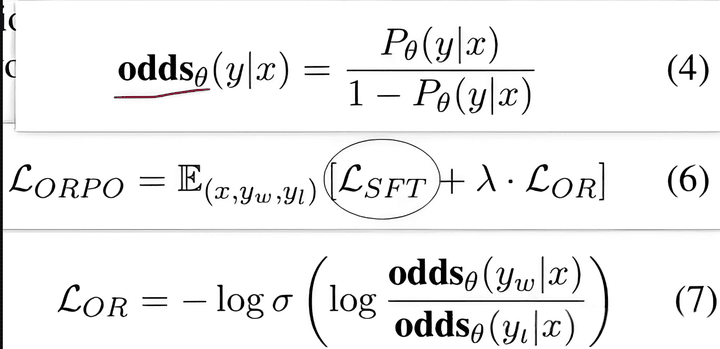
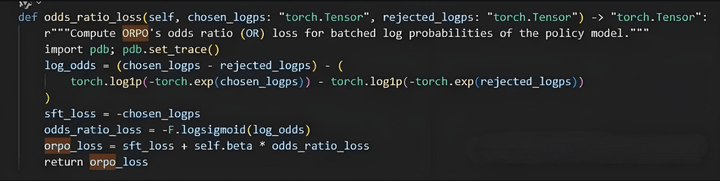
ORPO從本質上來說和DPO在解決的是同一個問題:拉遠正負樣本的距離,讓模型更好地區分正負樣本。
這裏有個加權係數,實驗中通常取0.1,那麼實際上主要起作用的還是SFT。也就是在SFT上多引入了一點對比loss。
ORPO和DPO的區別:
1、ORPO沒有ref_model,DPO有。
2、ORPO的加權通常是pair_loss*0.1,可以看作是SFT訓練中增加一點對比學習效果。而DPO是sft_loss*0.1,是對比學習中引入一點sft效果,讓模型不至於跑太偏。如果ORPO去掉sft_loss,那麼就是一個去掉ref_model的激進RL方法,更容易跑偏。
ORPO的缺點:通常來說SFT階段需要幾萬~幾十萬的數據集,RL階段需要幾千~幾萬條pair數據。衆所周知,pair數據比sft數據難獲取。而ORPO是SFT+RL階段二合一,需要大量的pair數據。
Simpo:DPO簡化
SimPO: Simple Preference Optimization with a Reference-Free Reward

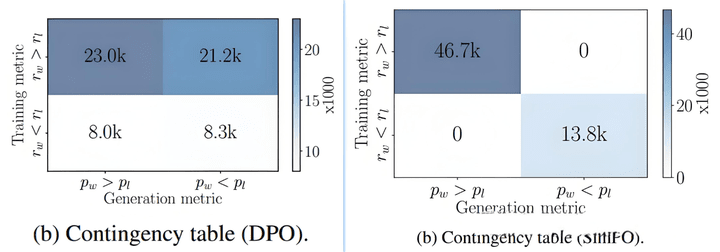
可以看出DPO的訓練結果中,有一半是不符合推理目標的要求的。
也就是說原始sft模型很難生成pair數據中的chosen數據,相比來說,更容易生成rejected。
實際項目中的DPO訓練數據通常就是這個樣子,rejected是sft模型生成的bad case(生成概率更大),而chosen是其他better model生成的(sft模型生成概率很低)。
SimPO對此做了優化。從獎勵函數可以看出相比於DPO,SimPO少了ref model。訓練顯存佔用更少,並增加了長度歸一化項,解決chosen通常比rejected更長導致的rl model輸出長度增長的問題。

簡單推理過程可以理解爲

Simpo中沒有KL散度約束,通過降低lr進行簡單約束模型偏差。

SimPO vs DPO:
總結就是,DPO是優化(當前model比ref model更接近chosen - 當前model比ref model更遠離rejected),目標太複雜,優化的結果不一定是最佳推理結果。
Simpo是優化(當前model生成chosen-當前model生成rejected),目標簡單明瞭。
缺點:沒有ref模型,沒加KL散度,容易巡飛。。。實測效果一般。
總結
1、DPO是PPO的簡化版,目的是優化max(chosen-rejected),對於不是自己生成的數據,容易產生chosen和rejected同時上升和下降的情況,效果不夠穩定(雖然比PPO已經好很多了)。
2、KTO把DPO的優化目標從max(margin)變成了max(chosen) or max(-rejected),保證了RL的效果,數據集質量一般的情況下,效果比DPO好。但方法的能力上限比DPO低。
3、ORPO的核心還是SFT loss,同時對pair數據的需求變大。
4、Simpo相比DPO,去掉了ref model,沒加KL散度,容易巡飛。
總的來說,在當前所做對話項目中還是DPO用的較多,常用於針對某類具體問題糾正模型回覆內容,其他任務類型不確定,完全需要具體任務具體分析。
提升對話質量方面,整體還是比較難搞的,畢竟沒辦法準確定義什麼樣的對話質量高,調prompt洗出“高質量”數據是最核心的工作內容。數據質量對結果的影響比RL方法的影響要大得多。
參考文章
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
小冬瓜AIGC:爲什麼DPO裏Chosen和Rejected概率會同時下降???
dpo 的侷限性
ChenShawn:【不靠譜】有關DPO訓練時,爲什麼chosen和rejected的reward一起下降的猜想
Sonsii:DPO及其衍生算法XX-O
人人都能看懂的DPO數學原理
KTO: Model Alignment as Prospect Theoretic Optimization
LLM RLHF 2024論文(八)KTO
大模型對齊技術,各種什麼O:PPO,DPO, SimPO,KTO,Step-DPO, MCTS-DPO,SPO
2024年大模型Alignment偏好優化技術PPO,DPO, SimPO,KTO,Step-DPO, MCTS-DPO,SPO
ORPO: Monolithic Preference Optimization without Reference Model
大模型的PPO、DPO偏好優化算法玩不起?那建議你看一下ORPO(更有性價比!)
SimPO: Simple Preference Optimization with a Reference-Free Reward
最後再總結一套炒幣心得:
第一點:那就是要懂得止損止盈
我們買賣幣是爲了交易,是爲了炒作,而不是永遠的拿着!當你賺錢的時候,想的是賺更多,虧損的時候,你又不願意把它賣掉,這種想法是肯定不可取的。當倉位的走勢走錯的時候,那就需要果斷地賣出。
第二點:不要總想着低點買入、高點賣出。
因爲市場只會有更低的點和更高的點。我們普通人做不到這種機制,所以不要去追求所謂的高低。而我們真正要做的就是在底部區域和頂部區域買入賣出就行了。
第三點:量和價要配合完美。
對於那些上漲無量或者是說創新高無量的一些倉位,我們一定要警惕。它很有可能是一種主力出不了貨上漲衰竭的一種信號,千萬不要去追,寧願錯過也不能夠做錯。
第四點:反應要快。
當一個信息出現的時候,我們要馬上找到他利好的板塊和公司都有哪一些。如果第一梯隊你跟不上,那麼我們就要及時的去做,第二個梯隊同樣也會有不小的收穫。
第五點:要學會休息。
俗話說見底三個月、見頂三天。也就是說,已知幣價上漲週期的主升浪只有那麼一點點時間。所以我們要學會抓住這個主聲浪,其他的時間通常休息。
第六點:市場最大的利好就是暴跌,因爲暴跌之後往往會迎來很多更大的機會。別人貪婪的時候,你要學會恐懼,別人恐懼的時候我們就要貪婪。所以當市場出現暴跌的時候,不要怕,這個時候我們選擇優質的倉位及時建倉。
這六點說起來比較簡單,但是真正能夠做到並不多,爲什麼呢?如果你不能克服人性的弱點,你就永遠賺不到你人生中的第一個五百萬。
最後,淋過雨的人,總想給別人撐傘。自己經歷過孤立無援的日子,所以看到別人虧損纔會感同身受。會想要伸出援助之手,會想要彌補那個當時渴望被拉一把的遺憾,像是穿越時空給曾經淋雨的自己撐傘一樣。
這也是我分享的初心,希望能幫助廣大散戶朋友們少走一些彎路!
爲了讓大家少走彎路,這次也是把特意自己炒幣十年總結的感悟分享給大家,希望有緣人能看到並加以重視。無論你是新手還是老手,身家幾何又或者處在怎樣層次,都會對你有所幫助。覺得我分享有用的朋友可以轉發給身邊的人,讓更多人受用!
再勤奮的漁夫,也不會在狂風暴雨的季節出海捕魚,而是用心地守護好自己的漁船,這個季節總會過去,陽光明媚的一天總會到來!關注我,授你以魚還有漁,幣圈的門永遠都是開着的,順勢而爲,才能擁有順勢的人生,收藏起來,謹記於心!