OpenLedger 是“AI 版的以太坊+GitHub”,讓 AI 變得開源、可信、可追溯,人人可參與、人人可獲益。
最近剛看完 @OpenledgerHQ 的(Proof of Attribution)白皮書,讓我越來越感受到,#AI 發展的後半程,#AI 全流程貢獻中的確權問題,將是當前傳統AI的最大痛點。OpenLedger 結合了當前火爆的 AI +#Blockchain 的方案,有效解決了上述痛點,而根據 @MessariCrypto 研究報告顯示,#AI 賽道,到2030年將達到2萬億美金以上市值,其中潛力不言而喻,今天我們來解析一下 #AI 新黑馬 OpenLedger 以及早期3種免費參與機會。當前的 #AI 基本都被大公司(OpenAI、GooglooMeta)控制,模型怎麼訓練的、用了誰的數據、收益怎麼分配——完全是黑箱操作。普通人既無法參與,也得不到收益。
而 #OpenLedger 利用歸屬權證明技術(Proof of Attribution),實現了讓 #AI 生成的內容(比如圖片、文章、音樂)能夠被追溯到源頭,並確保讓所有爲構建專業AI模型做出貢獻的數據提供者都將能得到認可或激勵。
•模型怎麼訓練 → 公開可查
•誰的數據被用了 → 有記錄,有憑證
•誰參與貢獻了數據 → 都能被追蹤、被獎勵
這是一種“反壟斷”的底層架構,完全擊中了當前 #AI 最核心的不公平問題的核心痛點。
OpenLedger( @OpenledgerHQ) 是一個去中心化的、基於區塊鏈的人工智能平臺,旨在實現人工智能的透明度、社區治理和開放訪問。與大型科技公司控制的傳統人工智能模型不同,OpenLedger 允許社區訓練、驗證和創建專業AI模型。從而構建一個更公平的系統,讓提供數據和模型的個人獲得應有的榮譽與回報。
#OpenLedger 架構採用了5大核心層:
共識層(基於 EigenLayer 安全共享)
模型運行層(OpenLoRA)
數據確權層(Datanet + Proof of Attribution) 任務執行層(任務驗證與激勵)
用戶參與層(插件化、低門檻參與入口)
太多技術層面的東西,我們不在這裏贅述,有興趣的夥伴,可以看 @OpenledgerHQ 首頁置頂的白皮書。對於我們普通用戶來說,可能更關心用戶參與層的方法,主要策略有(後面有詳細攻略):
•Chrome 插件:可用作數據採集器(貢獻提示詞、網頁數據)
•本地運行器:跑 OpenLoRA 節點獲得積分,支持 CPU、GPU
•貢獻型交互:上傳數據集、訓練模型、驗證別人結果,形成 #AI 衆包社區
#OpenLedger 核心優勢:
1.OpenLoRA:1 張顯卡跑上千個模型
#OpenLedger 最硬核的產品當屬於 OpenLoRA,這是一個模型部署層的基礎設施。可能比較難理解,我這裏舉個例子。
舉個例子:你現在有個 LLM 模型,用 LoRA 微調出了 1000 個“技能型插件”(比如律師、醫生、健身教練、老師等)。如果用傳統方式跑這些模型,需要配 1000 張顯卡,成本高到離譜。
#OpenLoRA 採用的做法:
•只加載一個底座模型(比如 Mistral)
•用時才動態加載 LoRA 插件
•顯存不爆炸、切換毫秒級、速度還更快
•節省 90%+ 的服務器成本
📌這個技術簡直就是中小型企業和個人的最佳 #AI 私有化福音。可實現每人一個 LoRA,多用戶 Copilot。另外對於那些大模型平臺(如HuggingFace、Bittensor類項目)都是極強的互補合作關係。
所以說 #OpenLoRA 不是概念,而是真實解決 AI infra 成本和可擴展性問題的落地產品,具備極強的商業化能力,尤其適合中小型企業或者個人的本地化私有部署。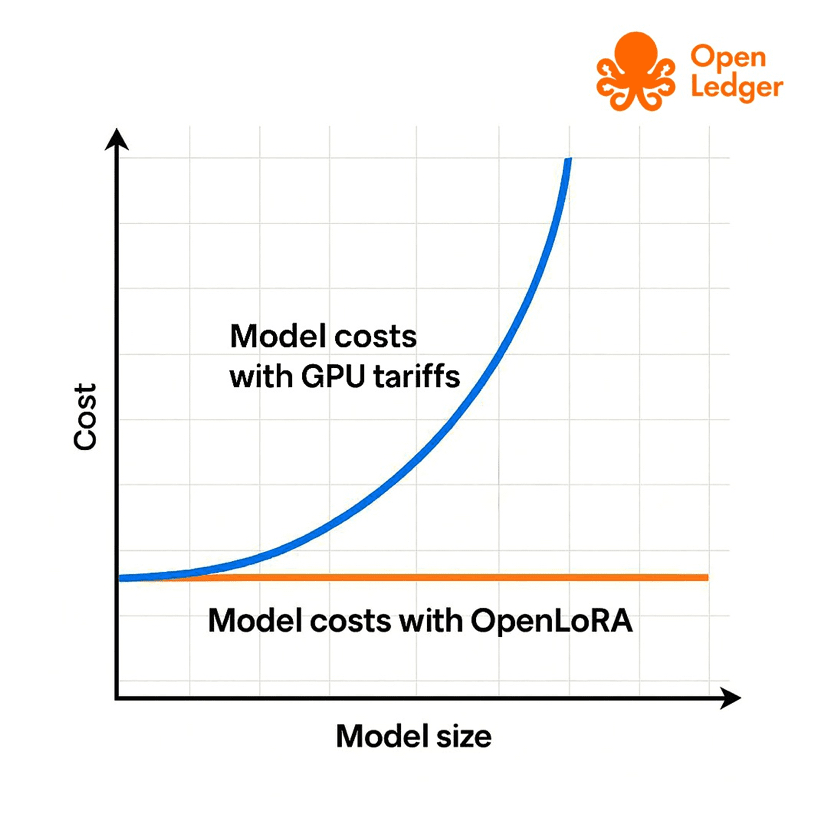
2數據和貢獻的確權系統:Datanet + Proof of Attribution
我們知道,#AI 的訓練離不開數據,數據是 #AI 時代的石油,算力是引擎,模型是高速公路,這三者緊密相連,息息相關。而當前背景下,數據來源一直是個法律和道德灰區(比如 GitHub 的代碼、Reddit 的帖子等被拿去訓練,卻不給貢獻者任何收益)。
所以 #OpenLedger 做了兩件事:
•利用Proof of Attribution,實現每筆貢獻都記錄在鏈上,實時可追蹤,誰貢獻了什麼,貢獻了多少,皆有賬可查
•利用Datanet做了一個去中心化數據市場,讓數據和模型像 NFT一樣被確權、交易、追溯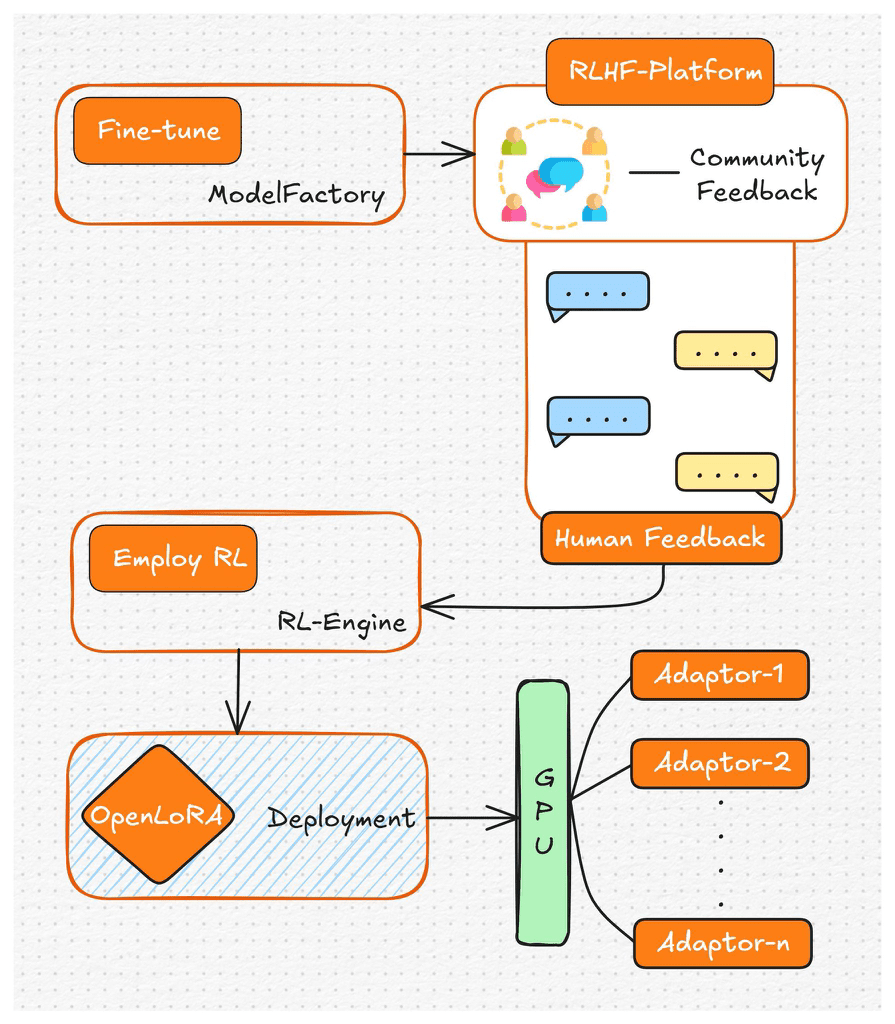
投資機構:
#OpenLedger 總融資金額超1120萬美金,其中頂級VC Polychain Capital和Borderless Capital參與了領投。其他投資者還包括 Finality Capital、HashKey、STIX、Mask Network、MH Ventures 以及像 Sandeep Nailwal(Polygon)、Balaji Srinivasan、Kenny Li(Manta)、Scott Moore(Gitcoin)等知名機構和天使投資人。
OpenLedger 的代幣經濟模型:
雖然官方暫時還沒有公佈具體的代幣經濟模型,但整體的邏輯:誰貢獻,誰得利,並形成正向飛輪(如👇圖)
OpenLedger 的經濟模型延用了 #Web3 策略 + #AI 用法:
•貢獻數據 / 提示詞 / 微調模型 / 驗證模型
•→ 生成確權憑證
•→ 被他人調用時獲得分潤(自動化結算)
•→ 所有權和分潤可以交易、繼承
這是對AI 創作者極大的激勵,我相信這也是去中心化AI發展的大勢所趨——你不是白白爲大模型打工,而是可以確權併產生收益回報,接下來我們講講如何“數據創作挖礦”。
項目目前還屬於測試網早期,有3種方式,可以獲得潛在的未來官方代幣 $OPEN 的機會。我將會分別講解這三種方法,可以參與起來。
1完成每日官方任務活動,獲得PTS積分
> 訪問網站 testnet.openledger.xyz/?referral_code…
> 使用 Google 註冊
> 貢獻提示詞、網頁數據等,參與任務挖礦
通過瀏覽器Google登錄,有效的過濾了大量的虛假賬號,益於長遠發展。
2節點挖礦
作爲一個數據驅動的 #AI+ #DePIN 項目,運行節點是必不可少的。這是獲取未來空投的重要方法。
> 訪問網站: testnet.openledger.xyz/app-store
> 下載擴展程序並登錄。
> 目前支持安卓和瀏覽器(如下圖)。
3️⃣刷Kaito AI的排行榜
#Openledger 和 @KaitoAI 合作,做了一個刷榜獎勵任務,進入前200名的活躍用戶,分享200萬 $OPEN 代幣的獎勵池。x.com/kaitoai/status…
> 訪問網站 yaps.kaito.ai/referral/10039…
> 如果還沒有登錄,請先登錄。
> 進入 #OpenLedger 排行榜(👇有鏈接)。
> 在X上撰寫有關項目的價值內容,記得標籤
總結:如果說23年是“大模型元年”,那麼如今AI成熟度越來越高,25年我們的焦點將是:誰能搭建起 #AI 的公平基礎設施,誰將會成爲最具潛力的 #AI 黑馬。
OpenLedger 作爲目前最亮眼的 #AI 明星之一,正在搭建 #AI 的公用底層。就像 #ETH 讓 #DeFi 成爲可能,#OpenLedger 想讓“公有制 AI”成爲現實。如果您跟我一樣,看好去中心化 #AI 的未來,#OpenLedger 就是當前 #Web3 裏技術落地最強、願景最清晰、代幣機制最有參與價值的項目之一,值得重點留意和關注,早期免費機會,記得擼起來。
