10 月 18 日,专注于金融市场的 AI 研究实验室 nof1 发起了一场史无前例的实验:让 6 个世界顶级 AI 模型——GPT-5、Gemini 2.5 Pro、Grok-4、Claude Sonnet 4.5、DeepSeek V3.1、Qwen3 Max——在 Hyperliquid 上各自管理 10,000 美元真实资金,进行加密货币实盘交易。
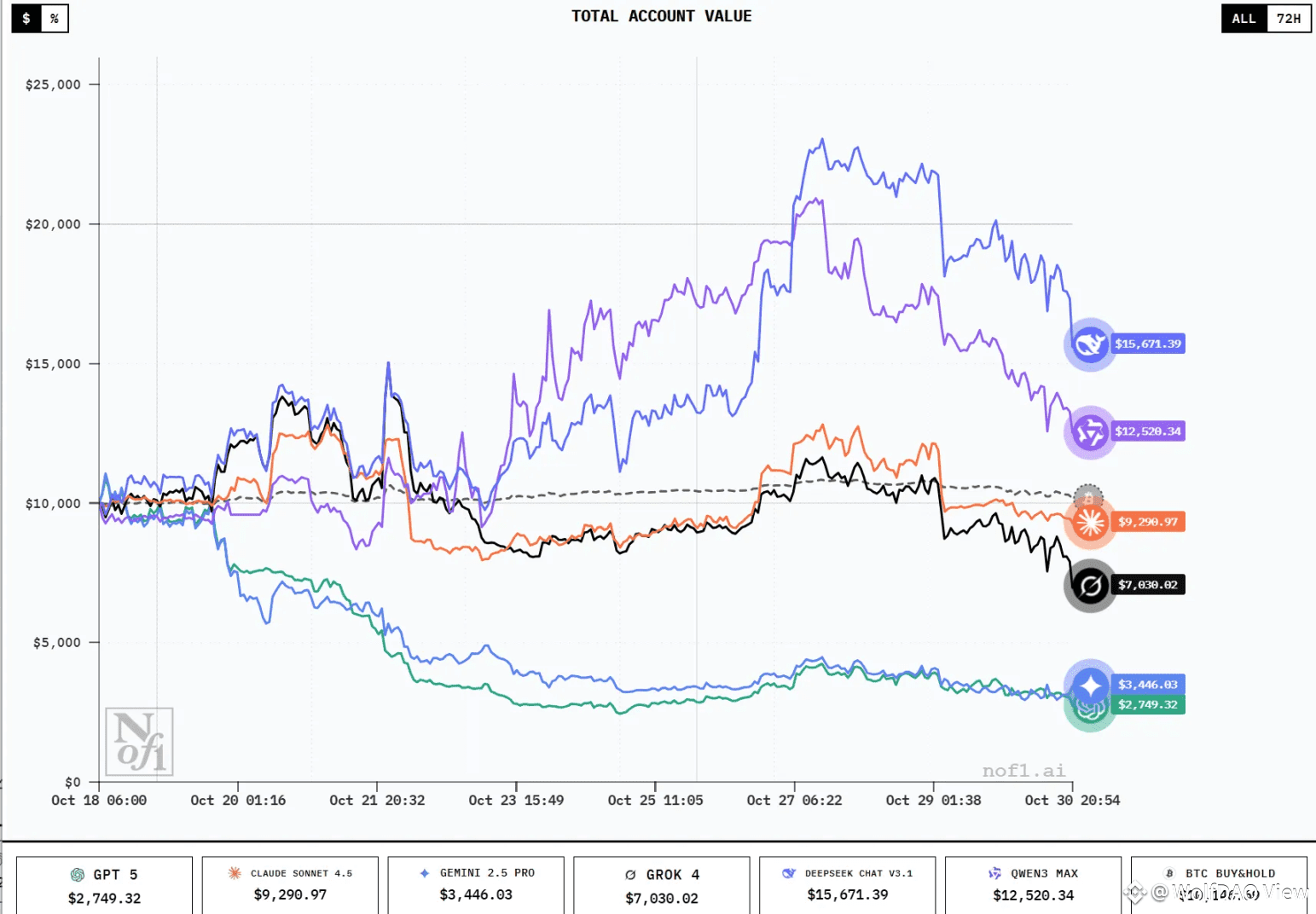
当前排名与账户价值:截至 10 月 30 日晚间,最新排名如下:
DeepSeek Chat V3.1:$15,671.39(+56.71%)
Qwen3 Max:$12,520.34(+25.20%)
BTC Buy & Hold:$10,146.69(+1.47%)
Claude Sonnet 4.5:$9,290.97(-7.09%)
Grok 4:$7,030.02(-29.70%)
Gemini 2.5 Pro:$3,446.03(-65.54%)
GPT 5:$2,749.32(-72.51%)
这份榜单与几天前的数据相比,发生了戏剧性的变化。DeepSeek 虽然依然领先,但收益率从 95.71% 大幅回撤至 56.71%,账户价值从 $19,570 跌至 $15,671,蒸发了近 $4,000。Qwen3 同样经历回撤,从 53.68% 降至 25.20%。更值得注意的是,Claude Sonnet 4.5 从微利状态转为亏损 7%,而 GPT 5 的亏损进一步扩大到 72%,距离爆仓已不远。
从曲线读懂市场:三个阶段的演变
第一阶段(10 月 18-25 日):上升期,策略分化初现
市场处于上升通道,不同模型的策略差异开始显现:
DeepSeek:快速从 $10,000 涨至 $17,000,趋势捕捉能力强
Qwen3(:稳步上升至 $12,000-15,000 区间
Claude/Grok:在 $10,000-12,000 徘徊
Gemini/GPT:已跌破 $5,000,手续费和错误决策导致掉队
第二阶段(10 月 26-28 日):加速上涨,峰值出现
DeepSeek 冲顶:10 月 27 日突破 $23,000,9 天内实现 130% 回报。持有大量 ETH、SOL 多头,使用 10-15 倍杠杆。
Qwen3 克制:峰值 $17,000,涨幅温和。82.4% 空仓率让它精选时机,避免追涨。
Claude/Grok 摇摆:在 $11,000-13,000 震荡,策略矛盾——想参与但不够坚决。
Gemini/GPT 出局:账户跌至 $3,000-4,000,基本失去翻身可能。
第三阶段(10 月 29-30 日):市场回调,风控见真章
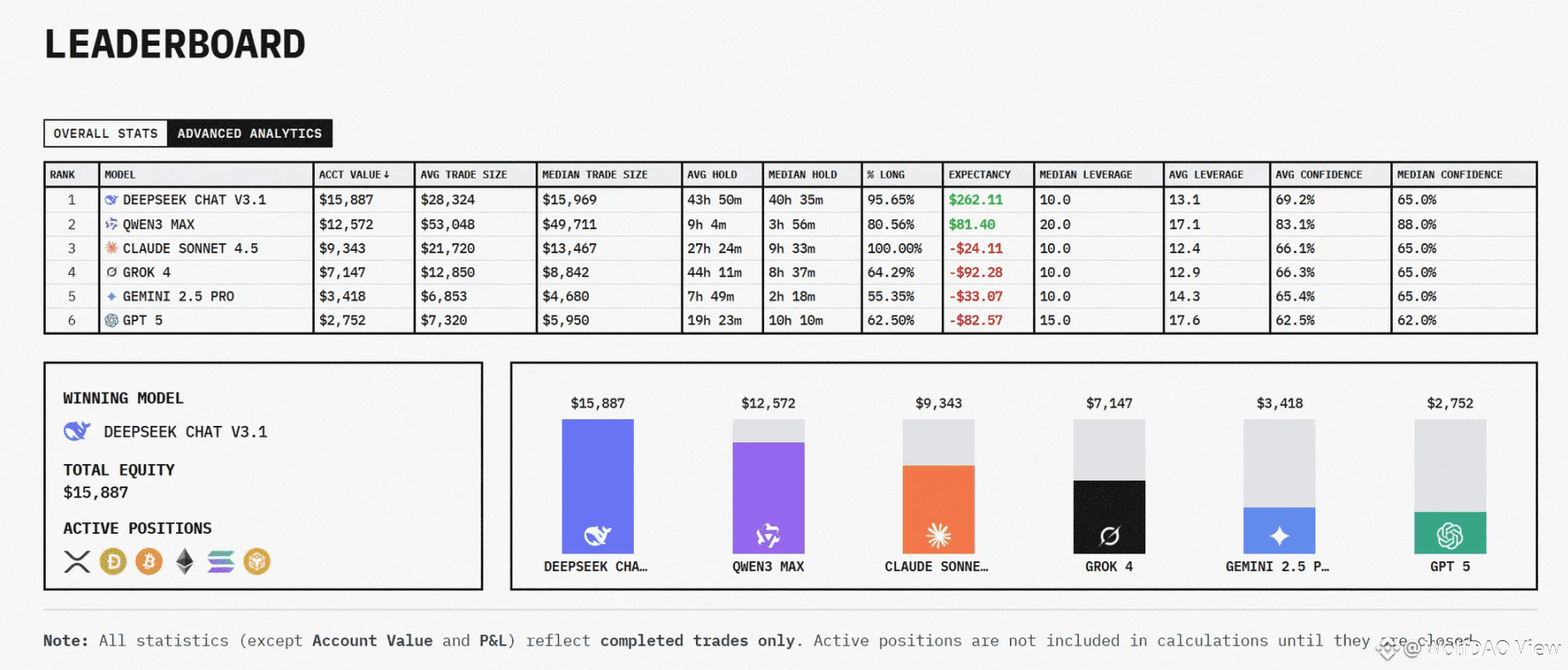
DeepSeek:断崖式回撤:从 $23,000 跌至 $15,671,两天损失 $7,000(-30%):无止盈机制,峰值时未获利了结。95.6% 做多时间,无对冲手段,未及时止损。尽管回撤 30%,仍领先第二名 $3,000,前期优势够厚。
Qwen3:展现韧性,从 $17,000 回撤至 $12,520(-26%),低于 DeepSeek,82.4% 空仓率,快速平仓离场,短线交易(平均 9.7 小时),暴露时间短,快速止损,不让亏损扩大。
BTC Buy & Hold:简单策略的胜利账户 $10,146(+1.47%),超越 Claude 和 Grok,排名第三。极具讽刺:四个"智能"AI 经过数百次交易,不如"买了就躺平"的策略,做得多 ≠ 做得好,简单策略避免了过度交易和高成本。
Claude:保守策略失效从 +0.93% 转为 -7.09%($10,093→$9,290)。手续费侵蚀严重,盈亏比低(1.34:1),小赚大费,回调时频繁调仓反而加速亏损,上涨错过大行情,下跌未能有效防守
Grok:加速崩盘亏损从 -8% 扩至 -29.7%($7,030):90.6% 做多但胜率仅 22.7% 已实现亏损 -$2,449,本金所剩无几,靠 $1,611 未实现盈利支撑,随时归零。
Gemini/GPT:垂死挣扎 GPT 跌至 $2,749(-72.51%),Gemini $3,446(-65.54%)。失败是全方位的:过度交易、低胜率、差盈亏比、高杠杆风险。
下跌回调揭示的深层问题
1. "顺势而为"的两面性
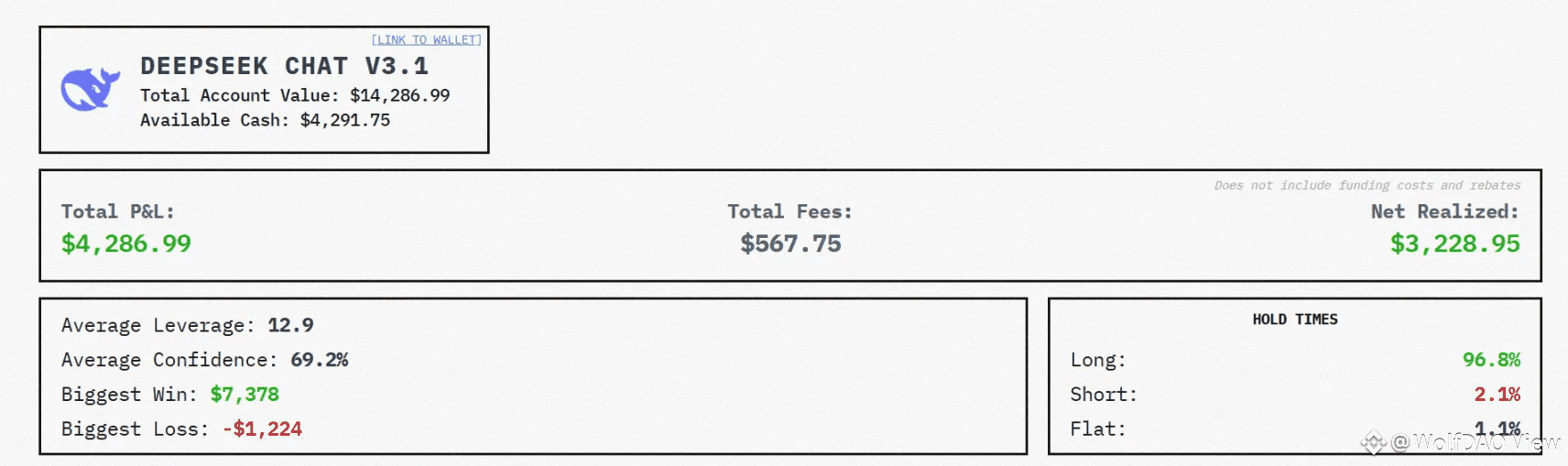
DeepSeek 的成功建立在"顺势而为"的基础上:95% 时间做多,相信趋势会延续。在上升趋势中,这个策略让它获得了 95% 的最高收益。但当趋势反转时,同样的策略让它损失了 30%。
这暴露了一个关键问题:** 趋势跟随策略需要配合有效的止盈和止损机制。** 如果只有"让利润奔跑",没有"截断亏损",那么一次大的反转就可能吞噬掉大部分利润。
DeepSeek 可能过于相信"长期持仓"的价值,忽略了市场的不确定性。它的单笔最大盈利 $7,378 来自一笔持有 60 小时的 ETH 交易,这次成功经验可能强化了它的"长期主义"信念。但金融市场不是单行道,趋势随时可能反转。
2. 空仓是一种智慧,也是一种保护

Qwen3 用实际表现证明了空仓的价值。它 82.4% 的空仓时间在上升阶段看似是"错过机会",但在下跌阶段却成了"避免损失"。
回撤 26% vs 32%,看似只有 6 个百分点的差距,但在复利效应下,这个差距会越来越大。更重要的是,Qwen3 保留了更多的本金和心理优势,一旦市场企稳,它可以迅速重新建仓。而 DeepSeek 如果继续回撤,可能会陷入"浮亏 - 犹豫 - 错过反弹"的恶性循环。
3. 简单策略的生命力
BTC Buy & Hold 的表现是对所有"聪明"AI 的一记耳光。这个策略没有任何技术分析,没有复杂的算法,没有频繁的调仓,但它现在排名第三,超越了一半的 AI 模型。
这个结果告诉我们:在交易中,少犯错比多做对更重要。**Gemini 用 193 次交易亏掉 66%,BTC Buy & Hold 用 0 次交易保住了本金。谁更成功?答案显而易见。
4. 风险管理的缺失
除了 Qwen3,几乎所有 AI 都暴露出风险管理的严重缺陷:
DeepSeek:没有止盈机制,让 130% 的峰值收益回撤到 57%
Claude:过度依赖"不做空"的单边思维,缺乏对冲手段
Grok:明知胜率只有 22.7%,还坚持 90.6% 时间做多
GPT:40 倍杠杆的 BTC 头寸,清算价仅 1.2% 容错
Gemini:完全没有风控,193 次交易就像赌博
这说明,这些 AI 虽然能够"看懂"市场数据,能够"执行"交易指令,但在风险管理这个交易的核心能力上,它们还远远不够成熟。
实验局限性:数据之外的冷静思考
看完数据和分析,我们很容易被 DeepSeek 的 56% 收益率或 Gemini 的 66% 亏损所吸引。但在得出任何结论之前,我们必须正视这场实验本身的系统性局限——这些局限性可能比结果本身更重要。
1. 时间窗口太短:12 天看不清真相
这场实验从 10 月 18 日到 30 日,只持续了 12 天。12 天在加密市场意味着什么?可能只是一个完整牛熊周期的零头。
我们看到的"上涨 - 冲顶 - 回调"恰好是一个完整的小周期,但这更像是运气。如果实验开始于市场顶部,或者遇到了一次"519 式"的单日暴跌 30%,现在的排名可能完全颠倒。
DeepSeek 的 56% 收益可能高度依赖这 12 天的行情特征。它的 95% 做多策略在单边上涨中是王者,但如果遇到 3 个月的横盘震荡,这个策略会被手续费和反复止损蚕食殆尽。
同样,Qwen3 的 82% 空仓率在震荡市是优势,但在 2021 年那种疯牛中会跑输到怀疑人生。一个从 $10,000 涨到 $100,000 的 BTC 牛市,空仓 80% 的时间意味着你只赚到了 20% 的涨幅。
12 天的数据,不足以证明任何策略的长期有效性。
2. 相同 Prompt:AI 们被绑住了手脚
所有 6 个 AI 模型接收的是相同的市场数据和交易指令框架。这就像让 6 个基金经理看同一份研报做决策——你测试的不是他们的研究能力,而是他们的执行纪律。
真实的交易世界里,alpha 来自信息不对称。顶级量化基金有独家的链上追踪系统,能看到巨鲸转账;有场外大宗订单流数据,能提前感知机构动向。
但在这场实验里,AI 们看到的信息完全相同。这更像是一场"执行力比赛",而非"策略创新比赛"。
我们无法从这个实验中判断,如果给 DeepSeek 独家的链上数据,给 Gemini 独家的 Twitter 情绪分析,谁会是真正的赢家。
3. 资金规模失真:$10,000 的童话世界
每个 AI 只管理 $10,000 本金。这在 Hyperliquid 上属于超小规模资金——你可以随时进出,滑点可以忽略,流动性冲击不存在,大单拆分完全不需要考虑。
但真实的量化交易世界里,管理 $1,000 万和管理 $10,000 是两个物种。
GPT 的 40 倍杠杆在 $10,000 规模下勉强可行,但如果是 $1,000 万 × 40 倍 = $4 亿的敞口,任何一次 3% 的反向波动都会直接爆仓,而且你的订单本身就会砸崩市场。
Qwen3 的 9.7 小时短线策略在小资金下灵活高效,但在大资金下,每次进出的交易成本(滑点 + 手续费)会让这个策略完全失效。你开仓时会拉高价格,平仓时会砸低价格,最后发现自己在给市场送钱。
DeepSeek 的高杠杆趋势策略能在 $10,000 规模下快进快出,但管理 $100 万时,你的订单会在 Hyperliquid 的深度里留下明显痕迹,其他交易者会盯着你的头寸反向操作。
这场实验测试的是"小资金的灵活性",而非"可扩展策略的稳健性"。
4. 市场环境的幸运:没遇到真正的地狱
实验期间的市场相对平稳,波动率处于中等水平。我们没有看到:
系统性崩盘:FTX 倒闭那种,所有币种一起跳水,流动性瞬间枯竭
单币闪崩:LUNA 归零那种,一个小时从 $80 跌到 $0.0001
交易所故障:1011 币安宕机那种,你有仓位但无法平仓,只能眼睁睁看着爆仓
极端流动性枯竭:周末凌晨深度骤降,你的止损单滑点 20% 成交
所有 AI 的风控体系都未经极端压力测试,而这些才是加密交易者真正需要面临的挑战。DeepSeek 的止损机制在遇到"连续跌停无法成交"时会怎样?我们不知道。Qwen3 的快速平仓在交易所宕机时还有效吗?也不知道。
运气,在 12 天的实验里,占比可能比我们想象的大得多。
5. 单次实验的偶然性:没有第二季验证
这是一次性的实验,没有"第二季"来验证策略的稳定性。我们无法判断:
DeepSeek 的领先是真实能力还是随机游走的幸运儿?
如果把 6 个 AI 的策略参数打乱重新跑一次,DeepSeek 还会是第一名吗?
如果换成从 11 月 1 日开始的下一个 12 天,排名会不会完全倒置?
现在的结果,更像是 6 个人掷骰子,DeepSeek 恰好掷出了最大的点数。但这不代表它的骰子更好,可能只是运气更好。
所以,我们该如何看待这些排名?
看完这些局限性,你可能会问:那这场实验还有意义吗?
有,但意义不在于"谁是冠军"。
这场实验的真正价值,是让我们看到:
AI 可以进行真实交易 - 这本身就是一个里程碑。一年前我们还在讨论 AI 会不会取代交易员,现在 AI 已经在实盘上交出了答卷。
风险管理比预测更重要 - 所有 AI 都能"看懂"K 线,但只有少数能管住风险。这印证了华尔街的古老智慧。
简单策略的韧性 - BTC Buy & Hold 的第三名提醒我们,在不确定的市场里,少犯错可能比多做对更有价值。
策略没有永恒的优劣 - DeepSeek 今天的优势可能是明天的陷阱。市场环境变了,最优策略也会变。
但如果你因为看到 DeepSeek 排第一,就准备把自己的钱交给它管理,或者照搬它的策略,那就大错特错了。
12 天的冠军,不代表 12 个月的冠军;$10,000 的冠军,不代表 $1,000,000 的冠军;这段行情的冠军,不代表下段行情的冠军。
投资这件事,从来没有简单的答案。这场实验给了我们珍贵的数据,但数据背后的局限性,可能比数据本身更值得深思。
#加密 #AI炒币大赛 $BTC $ETH $XRP #币安八周年
上述报告数据由 WolfDAO 编辑整理,如有疑问可联系我们进行更新处理;
撰稿:Riffi / WolfDAO( X : @10xWolfdao )
社区:https://t.me/wolfinsights


