Regarding its newly released Grok 4, Musk proudly stated at the launch: 'We have run out of test questions to ask, reality is the ultimate reasoning test.'
Today, let's follow Suki to see how Grok 4 performs in various tests. Is it really the most perfect AI answer sheet at present?
Unmatched reasoning and computational ability: when the 'top student' enters 'chaotic kill' mode.
If the intelligence of an AI model can be measured by its ability to solve complex problems, then Grok 4 undoubtedly stands at the top of the pyramid. It has demonstrated breathtaking 'dominance' in multiple benchmark tests known for their difficulty!
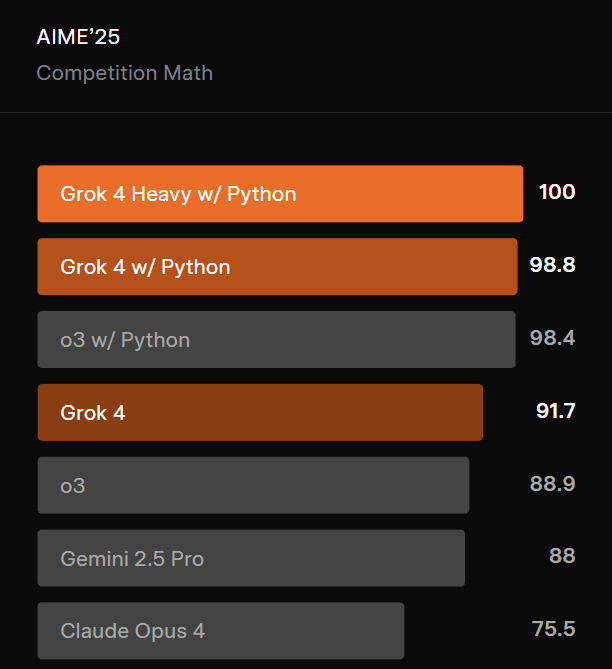
First and foremost is its performance on the AIME25 math competition benchmark. AIME is the American Mathematics Invitational Exam, which is far more difficult than regular math tests. On this list, the Heavy version of Grok 4 achieved a perfect score of 100%. This is not just a high score; it feels like the end of an era. It declared its absolute leading position in such pure mathematical logic reasoning tasks with an indisputable perfect performance.
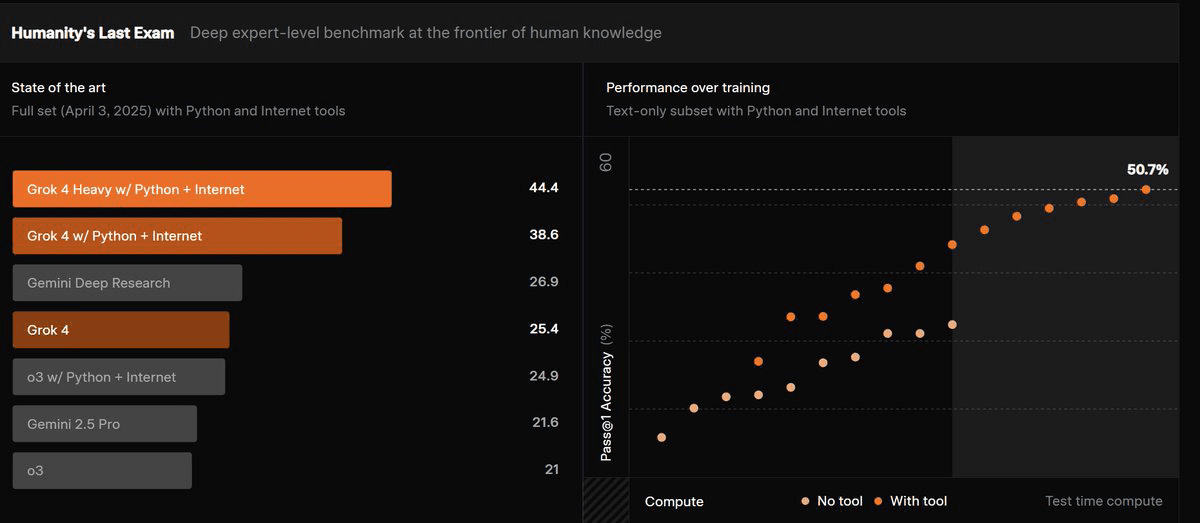
Secondly, in the test known as 'Humanity's Last Exam', Grok 4 once again proved itself. This is a comprehensive and highly challenging test set. Without using external tools, Grok 4 achieved an accuracy rate of 25.4%, already ahead of Gemini 2.5 Pro's 21.6%. And once tools were allowed, its 'Heavy' version soared to an astonishing height of 44.4%, leaving all competitors far behind, truly achieving a 'decisive victory'.
In addition to these iconic victories, Grok 4 has almost always ranked first or second in a series of high-difficulty academic and reasoning benchmarks such as GPQA, LCB, HMMT25! In short, in academic and reasoning tests, Grok 4 has won overwhelmingly!
However, Grok 4's strength is not merely reflected in cold numbers, but in the way it solves problems. Evaluations show that Grok 4 exhibits significant advantages in handling spatial geometry problems and complex logic puzzles. In a chessboard problem with more than 10 solutions, while other top models could only find two or three solutions, Grok 4 managed to find all the solutions.
Moreover, in some questions that test human intuition, such as finding numerical patterns or playing '24-point calculation', Grok 4 also performs astonishingly, able to quickly find the correct approach with very few attempts. This performance makes it seem not just like a calculating machine but more like an intelligent agent endowed with some 'inspiration' or 'epiphany' ability.
In other words, Grok 4 resembles a clever 'human' rather than a clever AI!
Achilles' heel: the triple dilemma of programming, instruction adherence, and stability.
Just as we marvel at Grok 4's extraordinary reasoning capabilities, its weaknesses are equally glaring.
The first and most serious shortcoming is its 'coding bias'. Programming ability is one of the core indicators of the versatility of modern large models, and this has traditionally been a weak point of the Grok series. Unfortunately, Grok 4 has not been able to completely turn this situation around. In a test covering six mainstream programming languages such as Python, Java, and C++, Grok 4's performance was astonishingly disappointing.
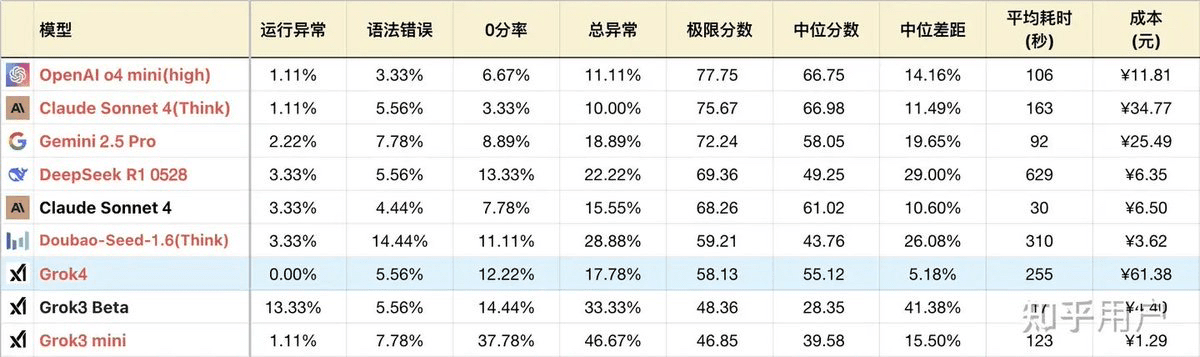
The second weakness is its unstable 'instruction adherence' ability. A reliable AI assistant must be able to accurately understand and execute user instructions. However, Grok 4 often 'drops the ball' in this regard. For example, in tasks requiring it to abbreviate words according to specific rules, it can get it right most of the time but occasionally ignores individual instructions without warning. This instability sharply contrasts with the robust performance of competitors, greatly limiting its practical value in serious and precise tasks.
The third issue is its 'failures' in some seemingly basic questions. Precisely because of its overly powerful logical abilities, when faced with tasks that require strict adherence to procedures rather than deep reasoning, Grok 4 tends to perform poorly. It seems that the AI is too smart, leading it to trust its solutions more and neglect to follow basic rules.
'Benchmark cheating' or true intelligence?
Grok 4's peculiar performance of 'having both strengths and weaknesses' just confirms a profound insight from Microsoft CEO Nadella: many large models today are caught in the trap of 'Benchmark Hacking'. They are over-optimized to achieve high scores in specific, structured tests but may not cope well with the complex problems of the real world filled with variables and ambiguities.
Grok 4 is an excellent case of this phenomenon. It is unbeatable in clearly defined and logically rigorous math and reasoning tests, but it struggles in tasks that require creativity, following cumbersome instructions, or rigorous code generation.
In summary, Musk's claim that Grok 4 is 'the smartest AI on Earth' may be a selective narrative. It is undoubtedly one of 'the best problem-solving AIs' and a milestone that has reached new heights in logic and computation. But it is far from an all-round player.
Comprehensive recent detailed evaluation reports and data charts paint a complex and contradictory image of Grok 4: it is a genius that excels in logic and computation but also exposes significant shortcomings in other key abilities that cannot be overlooked.
Grok 4 resembles a typical 'specialized top student': its emergence has pushed AI's reasoning capabilities to a new frontier, while also sharply reminding us that the road to Artificial General Intelligence (AGI) requires not only the intelligence to solve problems but also comprehensive, balanced, reliable, and easily collaborative competencies. Grok 4 is an important step in this great journey, a glimpse towards AGI, but clearly, there is still a long way to go!