
Модели ИИ получают наибольшее внимание. Больше моделей. Умнее выходные данные. Быстрее реакции.
Но есть более тихая проблема, которая скрыта под всем этим: качество данных.
ИИ полезен только настолько, насколько полезна информация, на которой он обучается. И сегодня большая часть этих данных находится в закрытых системах, контролируемых небольшим количеством платформ. По мере того как контент, созданный ИИ, заполняет интернет, найти надежные, специализированные и качественные данные становится все труднее.
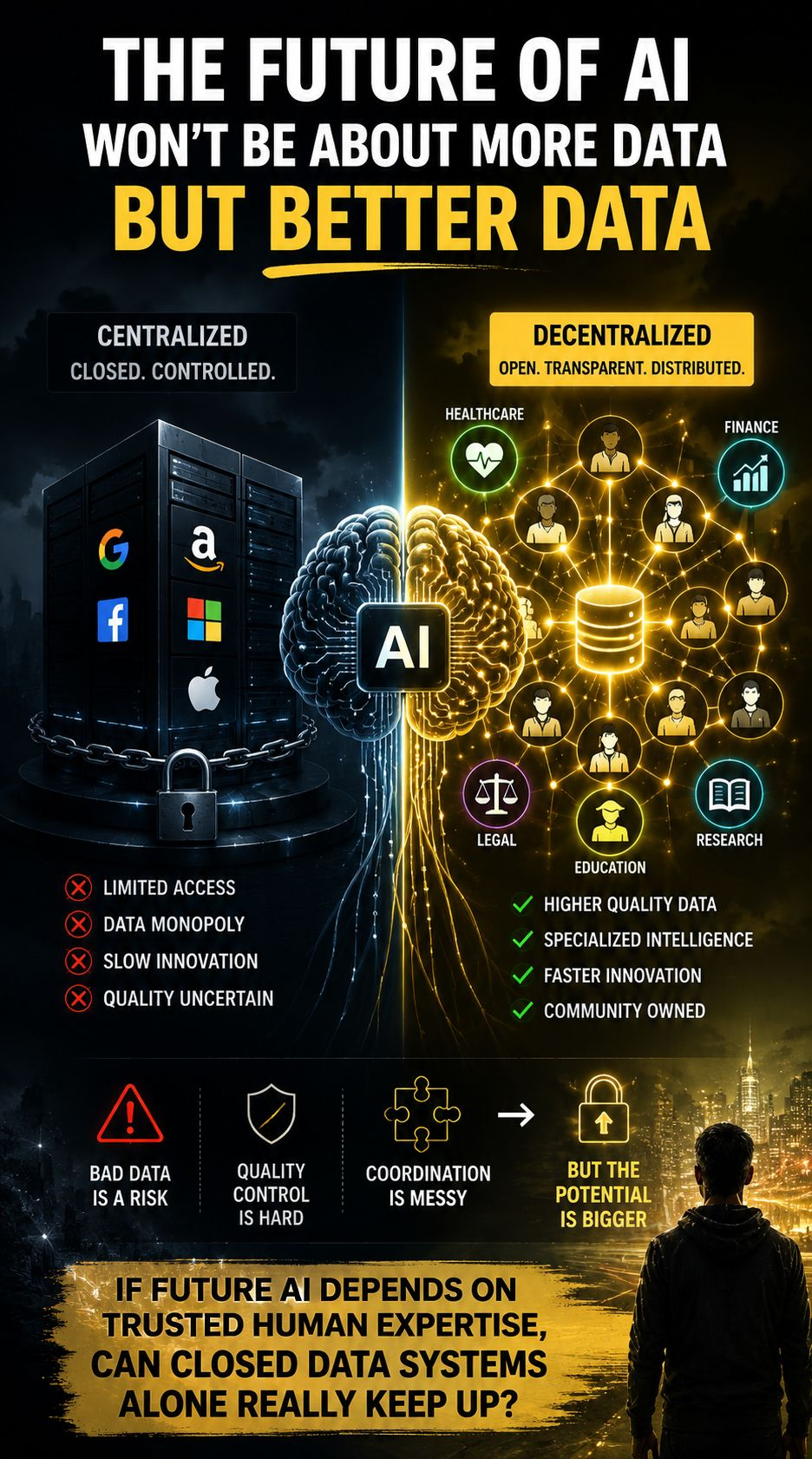
Вот почему децентрализованные данные ИИ имеют значение.
Аргумент прост: будущее ИИ может не выиграть за счет большего объема данных, а за счет их качества.
Искусственный интеллект в здравоохранении не может полагаться на случайный контент из интернета. Финансовая модель нуждается в точной информации о рынке. Юридический ИИ зависит от надежной экспертизы. Специализированный интеллект требует специализированных датасетов.
Децентрализованные системы данных пытаются решить эту проблему, делая вклад более открытым, прозрачным и распределенным, вместо того чтобы полностью зависеть от централизованных каналов.
Более глубокий смысл часто игнорируется: если качественные человеческие знания становятся самым ценным ресурсом для ИИ, то системы, собирающие и организующие этот интеллект, могут быть не менее важными, чем сами модели.
Конечно, децентрализация создает проблемы. Контроль качества затруднен, координация запутана, а плохие данные остаются риском.
Тем не менее, один вопрос становится все более громким:
Если будущий ИИ зависит от надежной человеческой экспертизы, могут ли закрытые системы данных действительно справиться?
