
Wczoraj wieczorem przeczytałem coś, co szczerze mnie zaniepokoiło i od tego czasu nie mogę się od tego uwolnić.
Istnieje atak na systemy AI, który nie wymaga hakowania modelu. Nie trzeba przeprowadzać włamania na serwer. Nic zdalnego nie wygląda jak cyberatak. To jest cichsze niż to. I szczerze mówiąc — już to się dzieje w systemach, którym ludzie bezgranicznie ufają.
Nazywa się to data poisoning. I to może być obecnie najbardziej niedoceniane zagrożenie dla całej gospodarki AI.

Jak wygląda Data Poisoning
Stary, ten problem jest dla mnie dziki — to takie proste do wykonania.
Nie trzeba być wyrafinowanym. Nie trzeba rozumieć architektury modelu. Nie potrzebujesz dostępu do infrastruktury szkoleniowej. Musisz tylko zrozumieć, że modele AI uczą się na danych, na których są trenowane — a następnie ustalić, jak wprowadzić zniekształcone dane do rurociągu upstream.
Zli aktorzy nie hackują modeli. Najpierw zatruwają studnię — przed tym, jak model zacznie pić.
To może wyglądać w ten sposób — subtelne wprowadzenie dezinformacji do publicznych zbiorów danych. Celowo zniekształcone przykłady, które popychają zachowanie modelu w konkretnym kierunku. Fałszywe prace badawcze. Manipulowane dane finansowe. Treści syntetyczne, które tworzą konkretne martwe punkty w tych systemach, które są na nich trenowane.
A co jest przerażające? Nie da się tego wykryć na podstawie wyników. Zatruty model nie ogłasza, że został skompromitowany. Po prostu zachowuje się nieco nieprawidłowo. Coś, co trudno jest prześledzić do źródła. Coś, co staje się oczywiste dopiero wtedy, gdy szkody są już głęboko zakorzenione w systemach, na których polegają miliony ludzi.
Większość infrastruktury AI nie ma obrony przed tym. I nie mówię tego jako krytykę — to problem strukturalny, który nie może być rozwiązany bez fundamentalnej zmiany w sposobie pozyskiwania i weryfikacji danych szkoleniowych.
Dlaczego nieatrybuowane dane są przyczyną problemu
Spędziłem trochę czasu na mapowaniu dokładnie, dlaczego ta podatność istnieje i zawsze zatrzymuje się na tej samej fundamentalnej luce.
Gdy modele AI są szkolone na danych z internetu bez atrybucji, weryfikacji lub zapisów pochodzenia — nie ma filtra między autentyczną a celowo wprowadzoną zniekształconą treścią. Każdy element danych szkoleniowych wydaje się równie ważny, ponieważ nie jest przypisany do żadnej tożsamości.
To jest sedno zatrutej studni. To nie jest awaria techniczna. To awaria strukturalna. Studnia została zbudowana bez żadnych kontroli.
A gdy model zostanie przeszkolony na zatrutych danych — nie możesz rozwiązać problemu poprzez ponowne szkolenie, jeśli nie wiesz, które dane były zatrute. Działasz wstecz bez mapy.
To jest to, co cały czas siedzi w mojej głowie, gdy myślę o przyszłości gospodarki AI. Wyścig obliczeniowy, na którym wszyscy się koncentrują — jest poniżej tego problemu. Nawet jeśli masz najsilniejszą sieć GPU na świecie — ale jeśli dane są skompromitowane, inteligencja również będzie skompromitowana.
Więcej obliczeń nie naprawi zatrutej studni. Po prostu pompuje truciznę szybciej.
Jak OpenLedger Defense Zmienia Sytuację
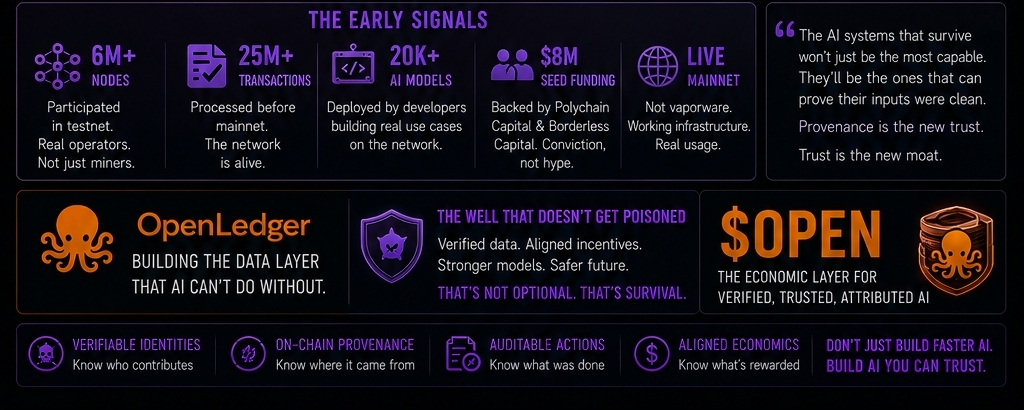
Chcę być szczery — kiedy pierwszy raz @OpenLedger widziałem, podszedłem do tego z perspektywy atrybucji i odszkodowania. Narracja Dowodu Atrybucji. Uczestnicy otrzymują wynagrodzenie. Własność danych. Wszystko to jest prawdziwe i ważne.
Ale im więcej wchodzę w architekturę, tym bardziej uświadamiam sobie, że istnieje wymiar bezpieczeństwa, który prawie nigdy nie jest omawiany.
Dowód atrybucji to nie tylko mechanizm płatności. To warstwa weryfikacyjna.
Gdy każdy zestaw danych, który przyczynia się do modelu, ma zapis na łańcuchu — gdy każda tożsamość uczestnika jest powiązana z ich wkładami — gdy każdy element danych szkoleniowych niesie zapis pochodzenia, który można audytować — powierzchnia ataku na zniekształcenie danych dramatycznie się kurczy.
Nie można anonimowo zatruć studni, gdy każdy kropla wody ma zarejestrowane źródło.
Zły aktor, który chce wprowadzić zniekształcone dane do systemu opartego na atrybucji — natychmiast staje przed problemem, który nie występuje w systemach nieatrybuowanych. Ich wkład jest śledzalny. Tożsamość jest przypisana. Istnieje zapis pochodzenia do sprawdzenia, jeśli wyniki zachowują się w sposób nieoczekiwany.
To nie jest idealne zabezpieczenie. Nic nie jest. Ale to jest zasadniczo inny model zagrożenia, w którym większość infrastruktury AI obecnie działa.
$OPEN warstwa ekonomiczna również ma znaczenie — ponieważ atrybucja działa jako mechanizm bezpieczeństwa tylko wtedy, gdy uczciwe wkładanie jest bardziej racjonalne ekonomicznie niż złośliwe wkładanie. Projekt tokena tworzy tę samą zachętę. Zweryfikowani uczestnicy zarabiają. Zniekształcone wkłady są oznaczane i wyłączane. System staje się coraz trudniejszy do zatrucia z upływem czasu — nie łatwiejszy.
Tak naprawdę, co jest na szali?
Nie chcę przesadzać, bo może mylę się co do skali. Może zniekształcenie danych pozostanie teoretycznym problemem, a nie praktycznym kryzysem. Może za bardzo zagłębiam się w wczesne sygnały.
Ale szczerze — to wydaje się mieć niepokojącą trajektorię, a nie wydaje się, by można było to zignorować.
Systemy AI są integrowane w decyzje zdrowotne, systemy finansowe, infrastrukturę prawną i platformy edukacyjne. Stawki dla zachowań modeli, które są skompromitowane, rosną z każdym kwartałem. A rurociągi danych, które zasilają te systemy — są w większości niesprawdzone, nieatrybuowane i wciąż nieobronione przed celową korupcją.
Postanowienia dotyczące przejrzystości danych szkoleniowych w EU AI Act nie powstają w próżni — są odpowiedzią na prawdziwe obawy dotyczące tej klasy problemów. Litigacja dotycząca praw autorskich związana z danymi szkoleniowymi dotyczy częściowo odszkodowania, ale również pochodzenia.
Presja regulacyjna rośnie w kierunku tego, co wymaga argument bezpieczeństwa — zweryfikowanych, atrybuowanych, audytowalnych danych szkoleniowych.
To jest środowisko, dla którego @OpenLedger zostało stworzone. Nie w odpowiedzi na regulacje — ale jako infrastruktura, która ekonomicznie racjonalizuje zweryfikowane dane, zanim regulacje zmuszą do ich wprowadzenia.
Studnia, która nie jest zatruta
Tutaj ląduję po spędzeniu czasu w czasie rzeczywistym.
Systemy AI, które będą miały znaczenie w dłuższej perspektywie, nie będą tylko najbardziej zdolne. Będą tymi, które będą w stanie udowodnić, że ich wkłady są czyste. Które będą w stanie śledzić dane szkoleniowe do zweryfikowanych źródeł. Które będą w stanie wykazać on-chain, że studnia, z której piły, nie była zatruta.
To jest bariera, której obecna infrastruktura AI nie jest w stanie pokonać. Nie dlatego, że nie pomyśleli — ale dlatego, że powstały przed istnieniem tej infrastruktury.
@OpenLedger to ta sama infrastruktura. Działający mainnet. Działająca warstwa atrybucji. $OPEN przepływa przez system, w którym zapis pochodzenia danych nie jest myślą drugorzędną — to fundament.
Może rynek nie wyceni tego odpowiednio przez jeszcze rok. Może mylę się co do tego, jak szybko staje się to krytycznym różnicującym czynnikiem.
Ale problem zatrutej studni nie znika. Staje się coraz gorszy, gdy AI coraz bardziej integruje się w systemy, które naprawdę mają znaczenie.
A jedyną prawdziwą obroną jest dokładne wiedzieć, skąd pochodzi woda.
Szczerze — to nie jest opcjonalna infrastruktura. To jest infrastruktura przetrwania.