
Ciągle krążę wokół pytania, które na początku brzmi prawie zbyt technicznie, aż usiądę z nim na tyle długo, że zaczyna być niewygodne w inny sposób:
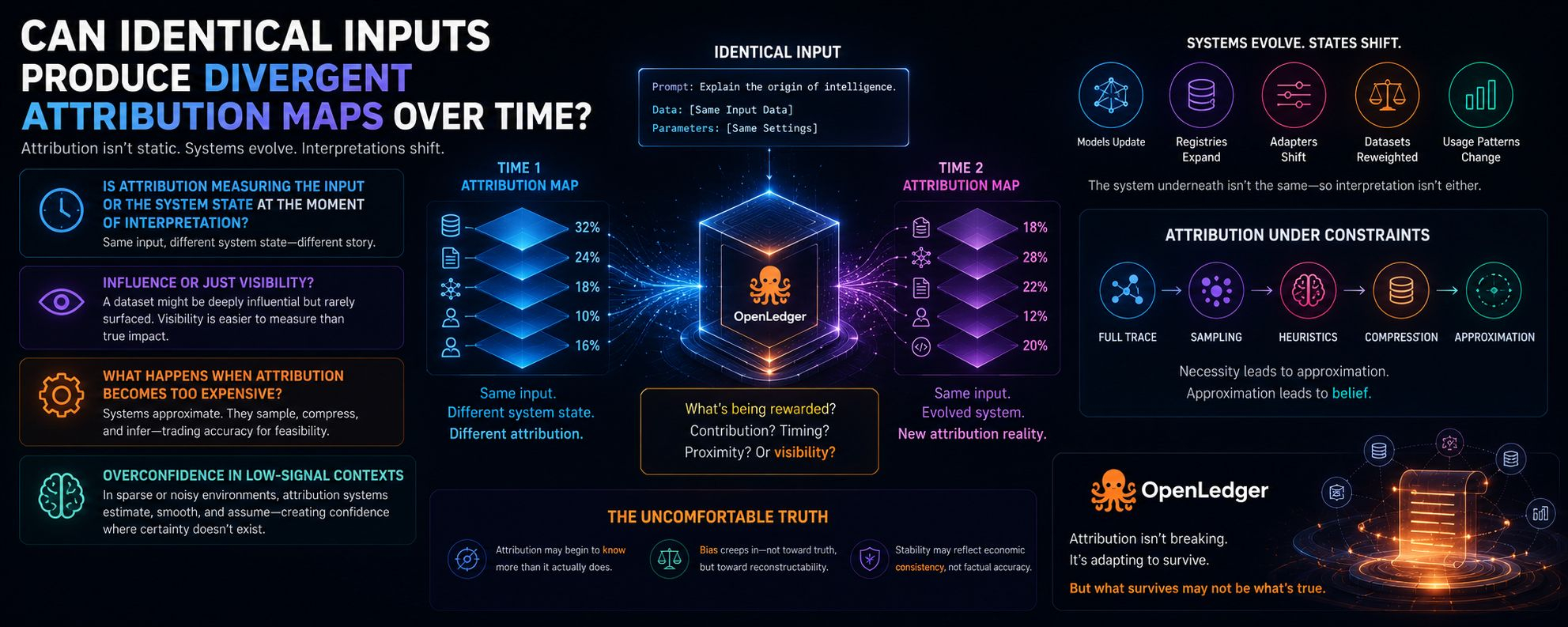
Czy identyczne inputy mogą generować różne mapy atrybucji w czasie?
Na papierze nie powinny. Ten sam input, ten sam system, te same zasady. Ale im więcej myślę o warstwach atrybucji w stylu OpenLedger, tym bardziej podejrzewam, że "ten sam input" to rodzaj iluzji, gdyż system ciągle się zmienia pod jego powierzchnią – modele aktualizują się, rejestry się rozszerzają, adaptery się przesuwają, zestawy danych są cicho ważąc ponownie przez wzorce użycia.

A potem zastanawiam się:
Czy atrybucja w ogóle mierzy wejście, czy stan systemu w momencie interpretacji?
Wtedy zaczyna to wyglądać inaczej.
Bo jeśli mapy atrybucji dryfują w czasie dla identycznych wejść, to co dokładnie jest nagradzane? Wkład? Czy timing? Czy po prostu bliskość do bardziej korzystnej konfiguracji systemu?
I szczerze mówiąc, rozumiem, dlaczego systemy ewoluują w ten sposób. Statyczna interpretacja nie przetrwa w dynamicznych sieciach. Ale mimo to, coś w tym wydaje się niestabilne w sposób, który trudno w pełni wyartykułować.
Wtedy ciągle zadaję sobie pytanie:
Czy uczestnicy są rzeczywiście nagradzani za wpływ, czy tylko za widoczność?
Rozróżnienie wydaje się subtelne, ale w miarę jak o tym myślę, wciąż się poszerza. Wpływ implikuje przyczynowość. Widoczność implikuje ekspozycję. Zbiór danych może być głęboko wpływowy, ale rzadko ujawniany. Inny może być często dostępny, lekko wpływowy, ale ekonomicznie dominujący po prostu dlatego, że znajduje się na ścieżkach inferencyjnych o dużym ruchu.
I to nie jest małe rozróżnienie.
Bo gdy tylko widoczność staje się łatwiejsza do zmierzenia niż wpływ, systemy naturalnie dryfują w stronę nagradzania tego, co mogą zobaczyć. Nie tego, co jest najważniejsze. Tylko tego, co najczęściej spotykane przez warstwę atrybucji.
Wtedy pojawia się inna myśl:
Co się stanie, jeśli obliczanie atrybucji stanie się zbyt kosztowne na zapytanie?
To pytanie wydaje się mniej teoretyczne, a bardziej jak ukryte ograniczenie, które już kształtuje wybory projektowe. Jeśli pełne śledzenie atrybucji staje się ekonomicznie kosztowne, systemy mogą zacząć przybliżać. Próbkowanie zamiast śledzenia. Heurystyki zamiast pełnych grafów genealogicznych. Kompresja zamiast pełnego mapowania przyczynowego.
A gdy to się stanie, coś subtelnego się zmienia.
Nie porażka.
Ale pewność.
Atrybucja może zacząć zachowywać się, jakby wiedziała więcej, niż w rzeczywistości wie.
To tam zaczyna mnie niepokoić idea „przesadnej pewności w kontekstach o niskim sygnale”. Bo w rzadkich lub hałaśliwych środowiskach inferencyjnych systemy wciąż muszą generować wyniki ekonomiczne. Więc oszacowują. Wygładzają. Wnioskowanie o wkładzie tam, gdzie sygnał jest słaby.
I ciągle się zastanawiam:
Czy to wprowadza cichą stronniczość w kierunku wzorców, które są najłatwiejsze do rekonstrukcji, a nie tego, co faktycznie spowodowało wynik?
Może.
Może nie.
Ale nawet niepewność wydaje się tu znacząca.
Bo jeśli atrybucja stanie się ekonomicznie konieczna, ale obliczeniowo przybliżona, to już nie mamy do czynienia z czystymi systemami śledzenia. Mamy do czynienia z systemami wierzeń, które przybliżają wpływ pod ograniczeniami.
I to zmienia, czym ten system naprawdę jest.
Ciągle wracam do tego samego nieprzyjemnego kręgu:
Jeśli identyczne wejścia produkują różne mapy atrybucji w czasie, a widoczność przeważa nad wpływem, a obliczenia wymuszają przybliżenie... to co dokładnie jest stabilizowane?
Nie prawda.
Nie pochodzenie.
Może to po prostu spójność rozkładu nagród przy zmieniających się wewnętrznych założeniach.
I nie mogę powiedzieć, czy to ograniczenie projektowe, czy coś bliższego strukturalnej właściwości skalowania systemów inteligencji.
Może atrybucja się nie psuje.
Może po prostu uczą się przetrwać, stając się mniej pewnymi siebie.
