
Ostatnio myślę o czymś, co spokojnie leży pod większością rozmów o AI.
Spędzamy dużo czasu na rozmowach o modelach, wydajności i możliwościach, ale znacznie mniej czasu poświęcamy na dyskusję o tym, skąd tak naprawdę pochodzi ta inteligencja.
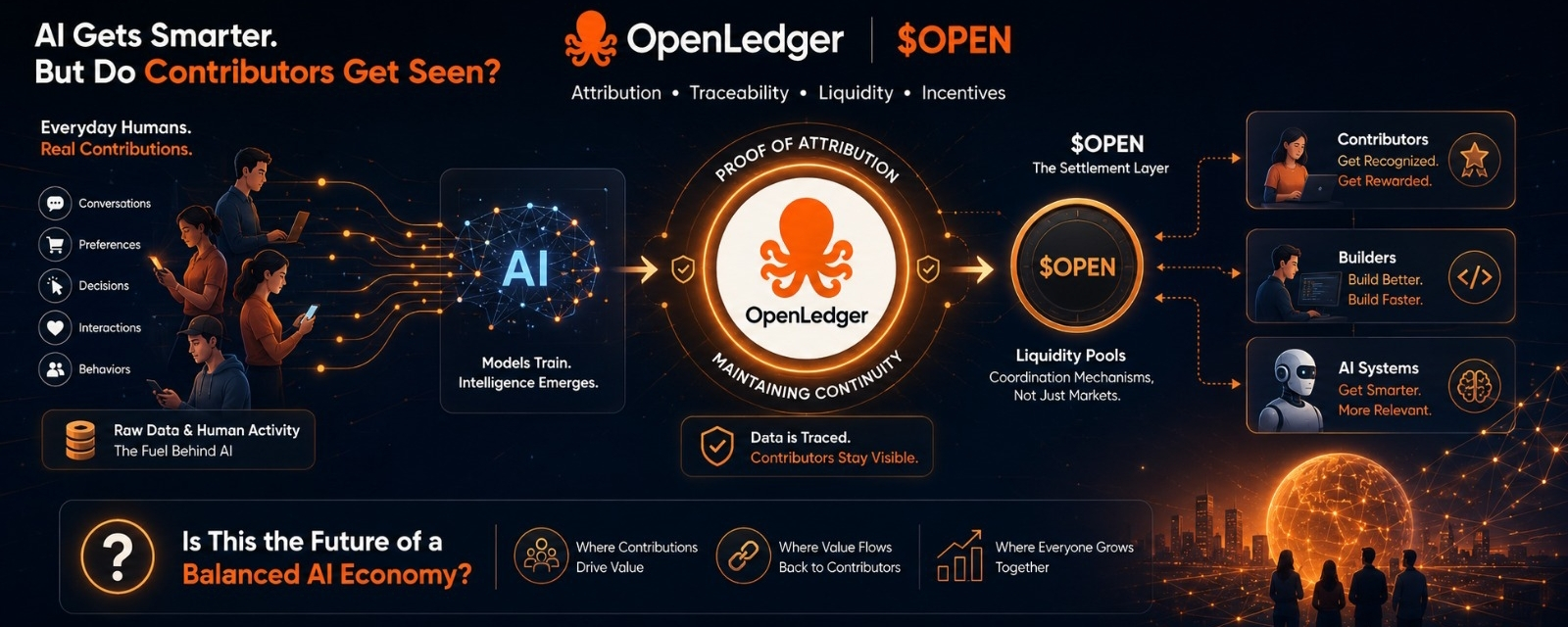
Każdy system AI oparty jest na danych. Nie tylko na zbiorach danych w technicznym sensie, ale także na fragmentach ludzkiej aktywności, rozmowach, decyzjach, preferencjach, nawykach i wzorcach, które ludzie tworzą każdego dnia. Gdy te informacje trafiają do systemu, są wchłaniane w procesy treningowe i przekształcane w wyniki. Efekty mogą być imponujące, ale gdzieś w tym wszystkim połączenie z pierwotnym źródłem często znika z pola widzenia.
To niekoniecznie wada. To po prostu sposób, w jaki większość systemów AI się rozwinęła.
Niemniej jednak nie mogę nie zauważyć, że przepływ wydaje się jednostronny. Ludzie wnoszą wartość poprzez swoje działania, dane są wydobywane z tych interakcji, a wynikająca inteligencja generuje jeszcze więcej wartości. Jednak droga powrotna do pierwotnych uczestników często jest trudna do zauważenia.
System działa. Co wydaje się brakować, to widoczność.
Dlatego projekty takie jak OpenLedger przykuły moją uwagę.
To, co mnie interesuje, to nie tylko sama technologia, ale idea stojąca za nią. Zamiast traktować dane jako coś, co znika w modelu na zawsze, OpenLedger wprowadza mechanizmy atrybucji zaprojektowane, aby śledzić, skąd pochodzą wkłady. Celem jest zachowanie rekordu uczestnictwa, nawet po tym, jak dane zostały przekształcone i użyte.
W tym sensie, dowód atrybucji wydaje się być czymś więcej niż narzędziem weryfikacyjnym. To próba utrzymania ciągłości.
Zamiast pozwalać danym zniknąć w czarnej skrzynce, system stara się zachować ślad ich podróży. Wkłady pozostają połączone z szerszą siecią, tworząc strukturę, w której uczestnictwo może być potencjalnie uznawane, zamiast stawać się niewidoczne.
Co sprawia, że to jeszcze bardziej interesujące, to rola płynności i zachęt.
W OpenLedger token nie jest przedstawiany tylko jako spekulatywny zasób. Przynajmniej w teorii, $OPEN funkcjonuje jako warstwa rozliczeniowa w ekosystemie. Tworzy sposób dla uczestników, twórców i systemów AI na interakcję w ramach tego samego ekosystemu ekonomicznego.
Z tej perspektywy pule płynności stają się czymś więcej niż rynkami.
Zaczynają wyglądać jak mechanizmy koordynacji. Miejsca, gdzie wartość przepływa między ludźmi dostarczającymi dane, deweloperami tworzącymi aplikacje i systemami generującymi inteligencję. To, co przemieszcza się przez te sieci, to nie tylko kapitał. To uwaga, użyteczność, istotność i zapotrzebowanie.
Ale to też tutaj zaczyna się moje największe pytanie.
Czy stworzenie możliwości śledzenia i atrybucji ekonomicznej naprawdę rozwiązuje nierówność, która istnieje w dzisiejszych systemach AI?
Czy po prostu ułatwia to pomiar tej nierówności?
Bo gdy dane, inteligencja i zachęty finansowe stają się ściśle powiązane, każda interakcja zaczyna nieść sygnał ekonomiczny. Uczestnictwo staje się czymś, co można śledzić, wyceniać i potencjalnie monetyzować na każdym etapie.
To może stworzyć sprawiedliwszy system.
To również może przekształcić nasze myślenie o samej inteligencji.
Im bardziej przyglądam się OpenLedger, tym bardziej czuję, że prawdziwa rozmowa nie dotyczy blockchaina czy tokenów. Chodzi o to, czy AI może ewoluować w system, w którym uczestnicy pozostają widoczni po tym, jak ich dane zostały przekształcone w inteligencję.
I to jest pytanie, do którego ciągle wracam:
Jeśli OpenLedger pozwala na śledzenie danych, nagradzanie i ciągłe łączenie z systemami AI za pośrednictwem $OPEN, czy tworzy to bardziej zrównoważony ekosystem dla uczestników?
Czy wchodzimy w przyszłość, w której każdy akt uczestnictwa staje się częścią większej sieci ekonomicznej, którą dopiero zaczynamy rozumieć?
