今晚正和同事老詹在小区门口的便利店门口蹲着,俩人一人拿一瓶冰啤酒,聊得正起劲。
老詹是我发小,干IT的,平时最爱吹AI多牛逼。那天他手机里打开一个AI助手,想让它帮忙规划周末带娃去哪儿玩,结果AI直接给他整了个“亲子露营路线”,里面居然推荐去一个早就拆迁的旧公园,还说“根据网友真实反馈,这里风景绝佳,适合烧烤”。老詹看完直接笑喷了啤酒:“这玩意儿是认真的吗?它数据到底从哪儿扒的?老子去年刚去过,那儿现在全是工地!”
我接过话茬儿,吐槽道:“可不是嘛,上周我让AI帮我修个坏了的吸尘器,它让我拆电路板用胶带缠,说是‘民间高手分享’。我照着搞了两下,差点把家里保险丝烧了。我老婆在旁边骂了我半小时,说我信AI信得脑子进水了。”
我们俩你一言我一语,越聊越觉得AI这东西现在就像个爱吹牛的酒肉朋友,表面上啥都懂,背后数据来源一问三不知,谁贡献的、谁该负责,全是黑的。聊着聊着,我就想:要是AI的每一口“饭”都有 traceable 的账本,谁喂的料、谁出的力、赚了钱该怎么分,都清清楚楚,那该多好?
没想到,这么一吐槽,还真让我挖到了 OpenLedger 这个项目。
它@OpenLedger 跟市面上那些喊着“链游百倍”“AI+GameFi”的项目完全不是一路货色。这个项目有点轴,带着一股老派理想主义,想把AI世界里最糊涂的那本账——数据归属和价值分配——给彻底摊开算明白。
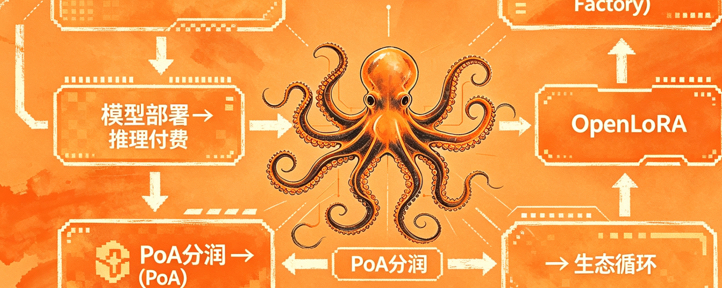
和其他项目最大的不同在于,它不靠你氪金抽卡、刷日常任务来维持热度,而是真把数据贡献当成核心价值。项目里有个叫Datanets的数据网络,想象成大家一起维护的一片共享菜园子。你可以把自己手头专业的东西上传上去,比如行业报告、交易记录、设计稿、维修经验、照片集等等。上传之后,社区的人一起验证、标注,谁干了什么、数据质量怎么样,全都明明白白记在区块链上。
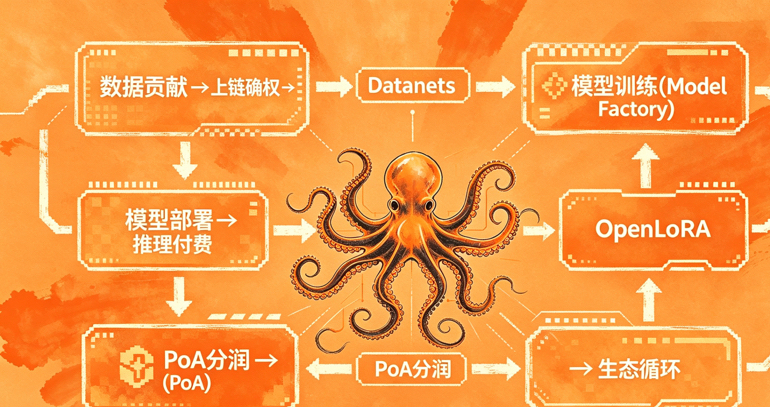
这些数据用来训练专用AI模型的时候,每一步,谁提供了原料、谁贡献了算力、谁调了参数——都有记录。模型跑起来之后,每次有人付费使用(他们叫 Payable AI),系统能自动追溯这个答案里有多少成分来自谁,然后把赚到的 OPEN 代币按比例分给贡献者。这套 Proof of Attribution(归因证明) 是它最特别的地方。别的AI项目大多还是训练在链下、概念在链上,数据来源永远雾里看花。这里却硬要把黑箱砸成玻璃箱,让普通人也能因为自己的知识或者数据真正拿到持续的分成。#OpenLedger
我自己去他们测试网溜达了一圈,上传数据还算简单,但后面验证和标注的过程确实有点磨人,像在群里跟人认真抬杠一样费劲。不过这也对,想把事情做扎实,哪有不费力的。
OPEN 代币是整个系统的血液,训练模型要付,使用AI要付,gas也要它,同时奖励也发它。总供应十亿,社区和生态占了大头,团队有锁仓安排。$OPEN 它不是纯空气治理币,而是真正在“谁养大了这个AI”这件事上尝试用代码来量化。这点让我挺有感触——我们以前给大厂AI白白当数据牛,现在至少理论上能反过来吃回点草。
项目从2024年开始启动,拿了 Polychain 等机构的支持,主网也已经上线。他们的愿景是做一个AI时代的底层可信账本,不是去取代 ChatGPT,而是让无数垂直、小而美的专用模型活下来,让普通人的专业能力和数据变成能持续生钱的资产。
我有时候会闪回那天和老王在便利店门口吹牛的场景,心想:要是当时我们用的AI背后有这种透明机制,说不定老王就不会被那个拆迁公园坑,我也不会差点把家里吸尘器搞报废。或者反过来,我自己这些年修各种家电攒的经验,也能被别人用、被分钱。这方向确实戳中我了,AI不该永远是少数巨头的狂欢。
当然,我也不是全盘接盘的粉丝,得泼点凉水。数据质量就是个大隐患,社区里什么人都有,垃圾数据很容易混进来把模型带歪。验证机制再牛,也难完全挡住劣币驱逐良币。目前生态还在早期,真实使用场景和模型数量还没那么爆炸,OPEN价格还是跟着大盘AI叙事一起晃荡。
另外有些技术细节我老实承认没完全搞懂,读白皮书的时候脑子偶尔会打结。竞争这么激烈,落地执行永远比画饼难得多,监管、隐私、解锁压力这些老风险也都在那儿摆着。$BTC
总的来说,OpenLedger是个有血有肉、缺点明显但内核挺实在的项目。它让我看到了一种可能:AI的糊涂账,或许真的能被慢慢算清楚。
我就是个普通吃瓜群众,边看边学,边吐槽边期待。生活里总得对那些试图把黑箱打开的家伙,保留点善意的怀疑和好奇。你要是感兴趣,也可以自己去转转,上传点自己的东西试试水。反正别all in,DYOR,玩得开心最重要。