我第一次看到OpenLedger测试网早期的数据时,确实有点意外。那几百万笔交易居然集中在相对有限的几个地址上完成,而同期活跃参与的用户已经超过百万规模。对于任何一条新生的公链来说,这样的密度都让我不由得停下来多想几层。过去在链上项目里摸爬滚打这么久,我很清楚行业里常见的那些数据注水把戏,很多人为了积分反复操作,脚本跑得飞起。可真正用手指一点一点完成上万次交互的人,现实中恐怕寥寥无几。这让我对很多表面光鲜的二层网络数据始终保持一份警惕。
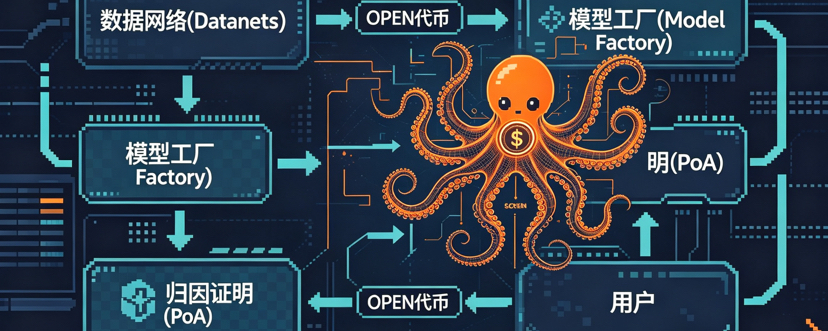
不过,OpenLedger的故事慢慢让我产生了不同的感受。它从设计之初就不是简单靠激励去堆交易量,而是试图构建一套有实际业务闭环的系统。数据提供者上传自己的资料,模型开发者基于这些资料进行训练,验证节点则通过一种归因机制来确认每一次推理的具体来源,最后由智能合约完成自动结算。每一步都对应着清晰的需求驱动,而不是单纯的循环自转。这一点,让我这个长期关注AI与区块链交叉领域的人,觉得它多了一层务实的底色。
@OpenLedger 在代币经济设计上,它也试图建立一种相对自洽的循环。数据贡献方和模型开发者用OPEN完成支付,验证者通过质押OPEN来获取手续费分成,普通持有者也能委托参与其中,分享网络收益。从测试网到主网,质押比例有明显提升,协议收入也逐步转化为对参与者的实际回馈。当然,我不会天真地认为所有收入都来自外部真实用户,还需要更长时间的链上观察才能确认比例。但整体架构避免了单纯依赖补贴的路径,这已经比一些早期项目多了一份稳健。#OpenLedger
我个人最欣赏的是它在产品层面的切入角度。AI领域里,数据确权和贡献追溯一直是个棘手的难题。大模型训练时数据来源混杂,创作者往往难以获得合理的回报,而每次模型调用背后的价值分配也缺乏透明机制。OpenLedger尝试把每一次数据使用和推理过程都记录在链上,并通过模块化的架构实现贡献的精确拆分与结算。它没有去硬拼底层算力,而是把重点放在“版权清算层”这个相对空白的位置上。这种模块化设计让我在实际测试中感受到明显的好处,不同角色可以相对独立地接入,开发者上手时不需要一次性掌握全部复杂度,迭代起来也更灵活。当然,上手门槛依然存在,尤其是对不熟悉链上工具的AI工程师来说,前期需要花些时间熟悉合约交互和验证流程。
风险当然摆在那里。类似领域已经有其他项目在探索分布式激励模式,OpenLedger的路径虽然更注重实际业务结算,但最终谁能真正形成网络效应,还需要时间验证。此外,数据确权涉及的法律与监管问题,在全球范围内都还处于探索阶段,不确定性不小。再看OPEN的价格表现,相比高点已经有了大幅回落,这也提醒我,故事再有说服力,最终还是要靠真实的用户粘性和开发者活跃度来支撑。$OPEN
经过一段时间的观察和小型测试,我已经把它列入自己的长期跟踪清单。接下来几个季度,我会重点留意节点稳定性、每日真实数据调用量,以及收入结构中跨链与数据服务各自的占比。这些指标会比任何白皮书都更诚实。只有当这些数字逐步稳定向上,我才会对它的长期价值更有信心。$BTC
说到底,这件事还是得自己亲手去验证。我不是在推荐什么,只是把一个实战开发者复盘时的真实思考分享出来。每一个决定都要基于自己的判断,毕竟钱包里的每一分都得自己负责。保持理性,慢慢来,或许我们能在AI与区块链的结合上,看到一些真正踏实的前进。