Non stavo cercando niente di specifico. Ho visto $OPEN menzionato in un feed, ho cliccato, ho iniziato a leggere del sistema di Proof of Attribution — e poi sono rimasto lì più a lungo di quanto mi aspettassi.
Ecco la cosa che ha fatto cliccare.
Tutti inquadrano @OpenLedger come una storia di possesso dei dati. Carica i tuoi dati, possiedi il tuo contributo, guadagna dall'AI. Questo è il pitch. Questa è la narrazione attorno a cui si unisce tutta la community di #OpenLedger. E sulla superficie ha senso — finalmente, un sistema dove le persone che hanno realmente alimentato la macchina ricevono una parte.
Ma più leggo su come funziona meccanicamente il Proof of Attribution, più mi rendo conto che la cornice di proprietà è solo metà della storia. La parte che la gente continua a trascurare è quando si attiva effettivamente la ricompensa.
Non guadagni al caricamento. Guadagni all'inferenza.
Il pagamento avviene solo quando un modello viene interrogato — quando qualcuno lo esegue, lo utilizza, gli chiede qualcosa. I tuoi dati seduti in un Datanet, verificati, attribuiti, registrati on-chain? Rimangono ancora dormienti economicamente finché il modello di uno sviluppatore non viene effettivamente chiamato. La $OPEN distribuzione fluisce dalle commissioni di inferenza, suddivisa tra sviluppatori di modelli, staker e contributori di dati al momento dell'uso.
All'inizio pensavo fosse un dettaglio tecnico minore. Ma in realtà… cambia l'intera situazione.
Perché significa che il valore economico del tuo contributo non è determinato da ciò che metti dentro. È determinato da quanto spesso il modello costruito sopra il tuo contributo viene utilizzato. Non stai monetizzando i tuoi dati. Stai prendendo una partecipazione passiva nella curva di adozione del modello di qualcun altro. Queste sono cose molto diverse.
E non sono sicuro che la maggior parte delle persone che caricano su Datanets in questo momento capiscano questa distinzione.
Il contributore che beneficia di più non è necessariamente quello con i dati di qualità più alta. È quello i cui dati sono finiti in un modello che uno sviluppatore ha costruito bene e ha promosso abbastanza aggressivamente da generare un volume di inferenze costante. Questa è una scommessa molto diversa da "i miei dati sono preziosi, dovrei essere ricompensato."
Ma ecco la parte che ancora mi infastidisce.
Se il volume di inferenza è ciò che sblocca effettivamente l'economia — e in questo momento il volume di inferenza è scarso secondo qualsiasi misura onesta, la rete ha lanciato il mainnet solo nel novembre 2025 — allora la storia di monetizzazione equa è per lo più prospettica. È un design che funziona magnificamente quando c'è domanda. Ciò che non può fare è fabbricare quella domanda. Il motore di attribuzione è solido. La logica di pagamento è elegante. Ma se le richieste di inferenza non scorrono su larga scala, i contributori di dati seduti nei Datanet stanno solo… aspettando.
Continuavo a tornare su questo. Il meccanismo è reale. Il livello di equità è genuinamente innovativo. Ma la cosa che lo rende economicamente significativo — volume di query, uso costante del modello, sviluppatori che scelgono di costruire qui rispetto a ogni altra opzione di infrastruttura AI — quella parte non è garantita dal design. Deve essere guadagnata nel mercato.
Che è probabilmente ovvio con il senno di poi. Ma nel modo in cui viene presentato, penseresti che caricare buoni dati fosse sufficiente. Non lo è. È una condizione iniziale, non una sufficiente.
Comunque. Continuo a osservare come si sviluppa il lato dell'inferenza nel prossimo trimestre. Questo è il numero effettivo da tenere d'occhio — non il prezzo, non la dimensione della comunità. Quanti modelli vengono chiamati, e con quale frequenza.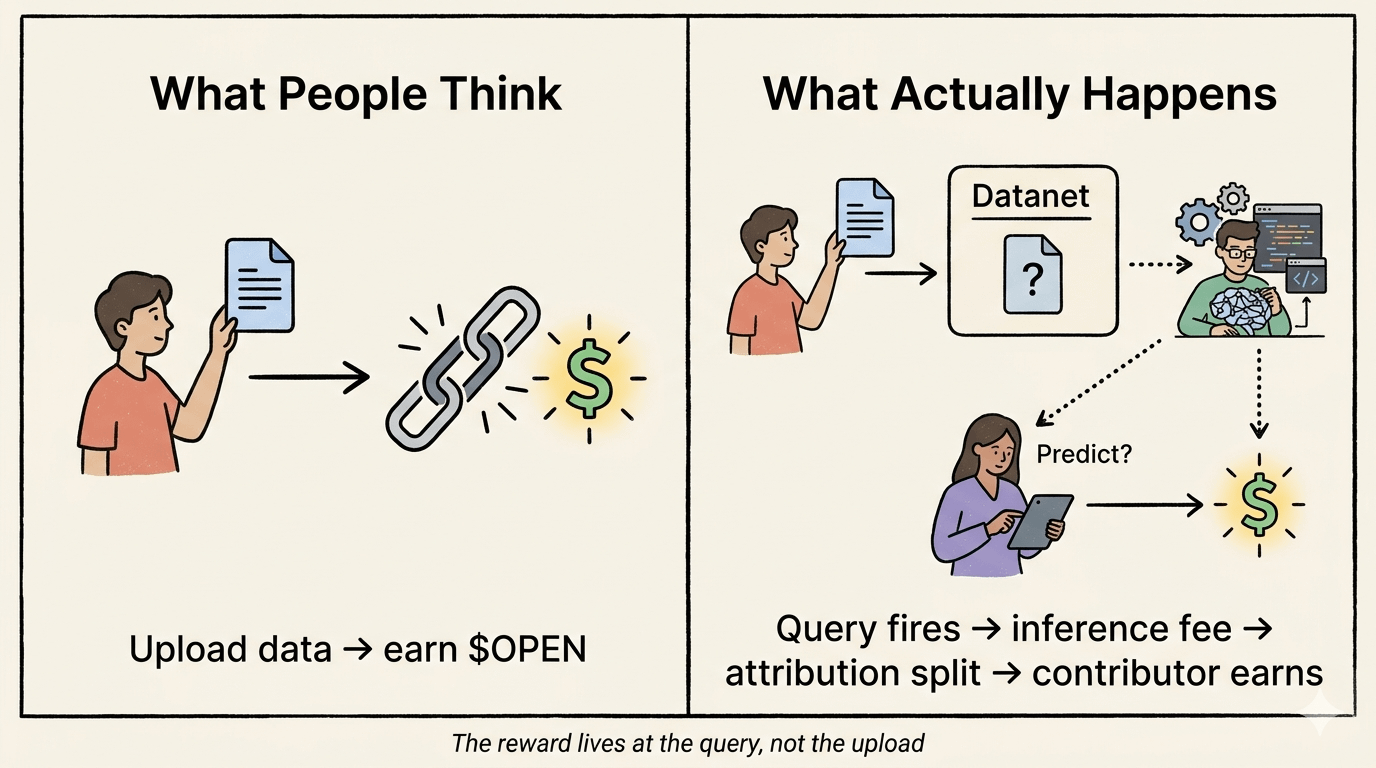
Tutto il resto è solo infrastruttura in attesa di una ragione per funzionare.