
Stavo scorrendo l'attività on-chain l'altra sera, senza cercare nulla di specifico, semplicemente osservando quanto tutto sembri ancora frammentato. Un wallet salta tra le catene, un altro interagisce con un modello, poi altrove un dataset viene riutilizzato senza che nessuno veda davvero dove sia finito il valore. Mi ha fatto fermare un attimo. Continuiamo a parlare di efficienza nel crypto, ma il flusso di contributo sembra ancora stranamente invisibile.
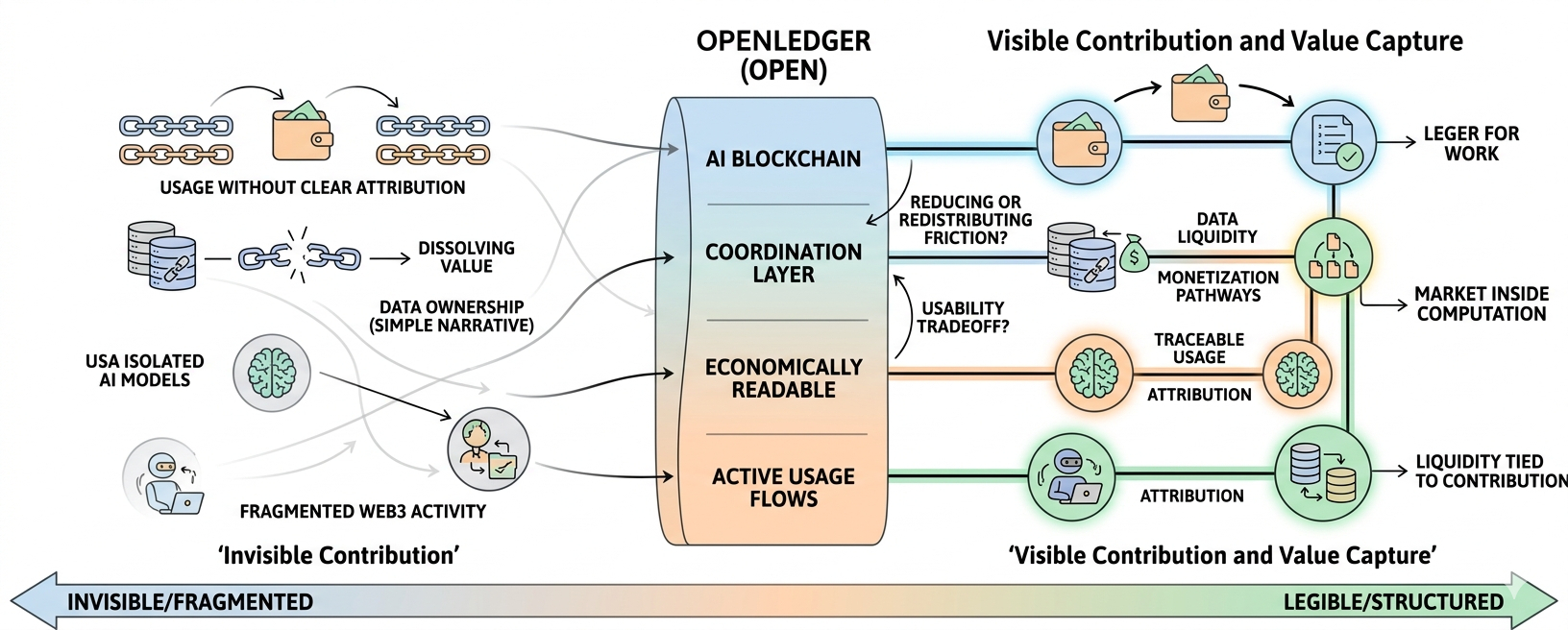
OpenLedger (OPEN) si trova in quel gap scomodo tra ciò che viene prodotto e ciò che viene effettivamente catturato. Un blockchain AI che cerca di rendere dati, modelli e agenti economicamente leggibili. Sto ancora cercando di decidere se questa impostazione abbia davvero senso nella pratica, o se suoni più pulita sulla carta rispetto a come si comporta nei sistemi reali.
Ciò che ha catturato la mia attenzione non è solo l'angolo AI. È l'idea di liquidità legata al contributo. I dati vengono generati costantemente in Web3, i modelli vengono addestrati, gli agenti eseguono compiti, ma gran parte di esso si dissolve in utilizzo senza chiari strati di attribuzione. Forse sto esagerando, ma sembra che ci manchi un libro mastro per il lavoro che non è puramente finanziario.
Ricordo quando 'la proprietà dei dati' era il racconto principale. Quella fase sembrava più semplice, quasi troppo semplice con il senno di poi. Possedere dati non significava automaticamente che potevi canalizzare valore da essi. OpenLedger sembra spingere quella conversazione un livello più in profondità, verso percorsi di monetizzazione che non sono solo diritti di archiviazione ma flussi di utilizzo attivo.
C'è anche qualcosa di leggermente inquietante in questa direzione. Se tutto diventa monetizzabile a livello di modelli e agenti, guadagniamo davvero chiarezza o introduciamo solo un altro strato di astrazione? Non ho una risposta pulita per questo. Potrebbe andare in entrambi i modi a seconda di come è progettata l'attribuzione.
L'idea che gli agenti guadagnino o canalizzino valore in base all'esecuzione è interessante, ma solleva anche domande sulla granularità. A che punto il contributo diventa troppo frammentato per essere tracciato in modo significativo? Ho visto tentativi simili in altri sistemi dove la precisione aumenta, ma l'usabilità ne risente silenziosamente.
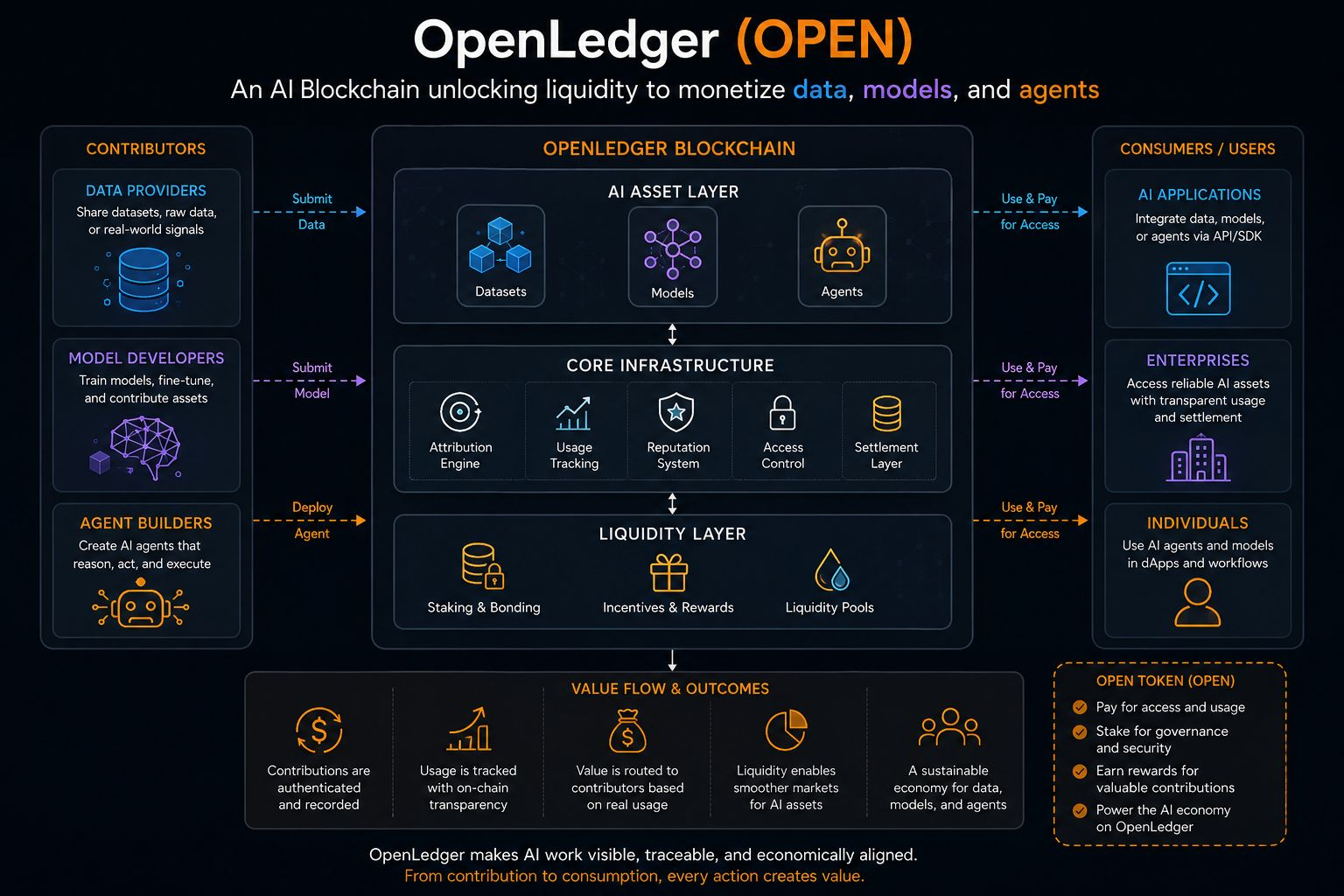
OpenLedger si posiziona come uno strato di coordinamento tra le uscite AI e il regolamento economico. Sembra interessante, ma nell'uso reale, gli strati di coordinamento tendono ad assorbire complessità piuttosto che eliminarla. Non sono sicuro se questo eviti quella trappola o semplicemente la sposti.
Eppure, c'è qualcosa di affascinante nel cercare di rendere tracciabile l'uso dei modelli. Nei sistemi AI tradizionali, tutto si mescola in inferenze da scatole nere. Qui, l'idea è più vicina a un'economia di interazioni. Ogni chiamata, ogni riutilizzo di dataset, ogni azione dell'agente porta potenzialmente peso. Sembra quasi un mercato che cerca di formarsi all'interno della computazione stessa.
Ma poi mi chiedo, l'utente medio o il costruttore vuole davvero quel livello di visibilità? A volte i sistemi diventano più efficienti ma meno intuitivi. E nel crypto, quel compromesso di solito si manifesta più tardi, non immediatamente.
Da una prospettiva di mercato, le narrazioni attorno all'AI e all'infrastruttura tendono a cicli rapidi. Ciò che sopravvive di solito non è il framing più rumoroso, ma la parte che riduce effettivamente l'attrito. Continuo a chiedermi se OpenLedger stia riducendo l'attrito o redistribuendolo su uno stack più complesso.
C'è anche la questione della liquidità stessa. Spesso assumiamo che la liquidità riguardi token e profondità di trading, ma qui sembra estendersi in asset informativi. La liquidità dei dati suona utile, ma sono ancora incerto su come si traduca direttamente in cattura di valore sostenibile senza distorsioni.
Forse l'angolo più interessante non è affatto la monetizzazione, ma la visibilità. Se il contributo diventa leggibile attraverso i sistemi AI, anche in modo imperfetto, questo da solo potrebbe cambiare il comportamento dei costruttori. O forse crea solo nuove forme di ottimizzazione da gioco. Ho visto entrambi i risultati accadere in configurazioni simili.
Non penso che OpenLedger abbia ancora un chiaro endpoint, e forse va bene così. La maggior parte degli strati di infrastruttura iniziali non ce l'ha. Iniziano come esperimenti di coordinamento e lentamente si consolidano in qualcosa di più definito, oppure svaniscono assorbiti da stack più ampi.
Quello che mi rimane è l'idea che stiamo andando verso sistemi in cui il valore non è solo creato o trasferito, ma continuamente ricalcolato mentre si muove attraverso modelli e agenti. Non sono completamente convinto che siamo pronti per quel livello di granularità, ma sembra che la direzione si stia già formando, che noi lo siamo o meno.
