

Pensavo che la proprietà dei dati fosse una frase semplice fino a quando l'IA non l'ha resa scivolosa. Una foto ha un proprietario. Una frase ha un autore.
Un dataset non rimane semplice a lungo. Dopo essere stato pulito, etichettato, mescolato e utilizzato dall'IA, la sua fonte originale diventa sfocata. Quando appare la risposta finale, potrebbe non sembrare più il risultato di un singolo contributo. È qui che le vecchie idee di proprietà smettono di essere sufficienti. Si chiede, chi possiede il file? L'IA chiede qualcosa di più strano: chi ha plasmato il comportamento?
Questa è la tensione in cui OpenLedger sembra muoversi con Datanets e attribuzione. Non sta solo cercando di dire che le persone dovrebbero possedere i dati in un senso di proprietà privata. Sta cercando di rendere la proprietà più aperta rendendo il contributo visibile dopo che i dati escono dalle mani di qualcuno.
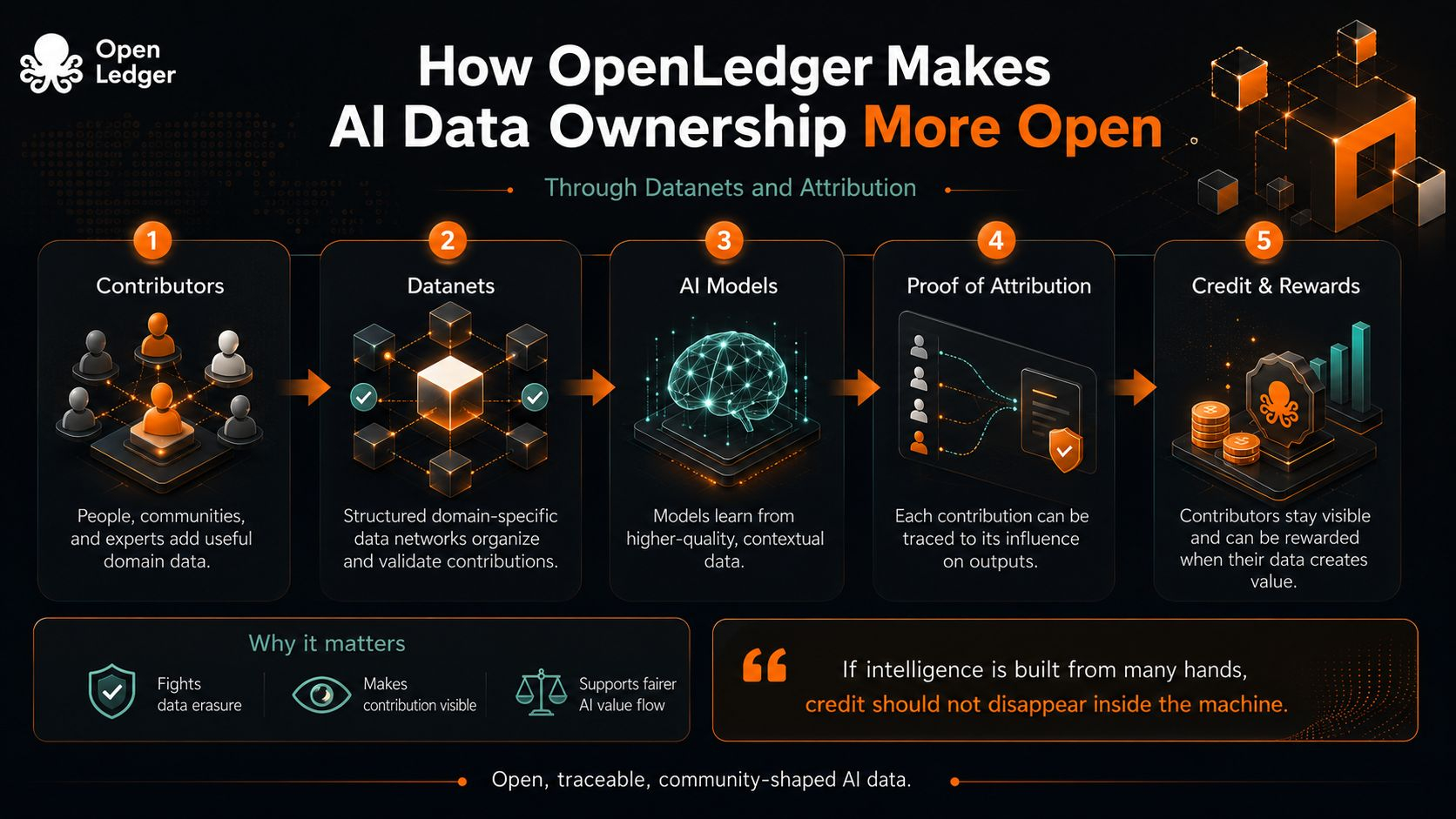
Trovo importante quella distinzione. Nella maggior parte dei sistemi AI, i dati entrano come una folla che entra in uno stadio. Una volta dentro, i volti scompaiono. Il modello finale si esibisce, l'app riceve attenzione e le persone che hanno fornito esempi utili diventano rumore di fondo. A volte erano ricercatori. A volte comunità. A volte utenti comuni la cui conoscenza aveva una struttura prima che un'azienda la trasformasse in carburante. Il default scomodo non è solo l'estrazione. È l'erosione.
I datanet, almeno come idea, si oppongono a quell'erosione dando ai dati un luogo per raccogliersi con contesto. Invece di trattare tutte le informazioni come un enorme mucchio, organizzano i contributi attorno a domini, scopi e comunità specifiche. Sembra piccolo, quasi amministrativo, ma cambia la forma morale del sistema. Un contributo non viene più semplicemente inghiottito da un modello. Entra in una rete dove la sua origine, uso e valore possono essere discussi.
L'attribuzione è la parte più difficile. È facile registrare che qualcuno ha caricato qualcosa. È molto più complicato dimostrare che quella cosa aveva importanza. La Proof of Attribution di OpenLedger punta proprio a quel secondo problema: non solo tracciare i dati, ma collegarli agli output dei modelli e ai flussi di ricompensa. Qui l'idea diventa interessante per me, perché tratta la proprietà meno come una scatola chiusa e più come una relazione viva. I tuoi dati contano se aiutano a plasmare la risposta. Il tuo credito non dovrebbe svanire solo perché il modello è diventato fluente.
Tuttavia, non voglio fingere che questo risolva tutto. L'attribuzione può diventare una burocrazia a sé stante. Dati scadenti possono essere tracciati con precisione. Contributi superficiali possono inseguire ricompense. Le comunità possono essere ridotte a classifiche se il design è sconsiderato. La vera prova non è se OpenLedger può descrivere un sistema più pulito. Molti progetti possono farlo. La prova è se il sistema può gestire il contributo umano disordinato senza appiattirlo in un altro gioco di punti.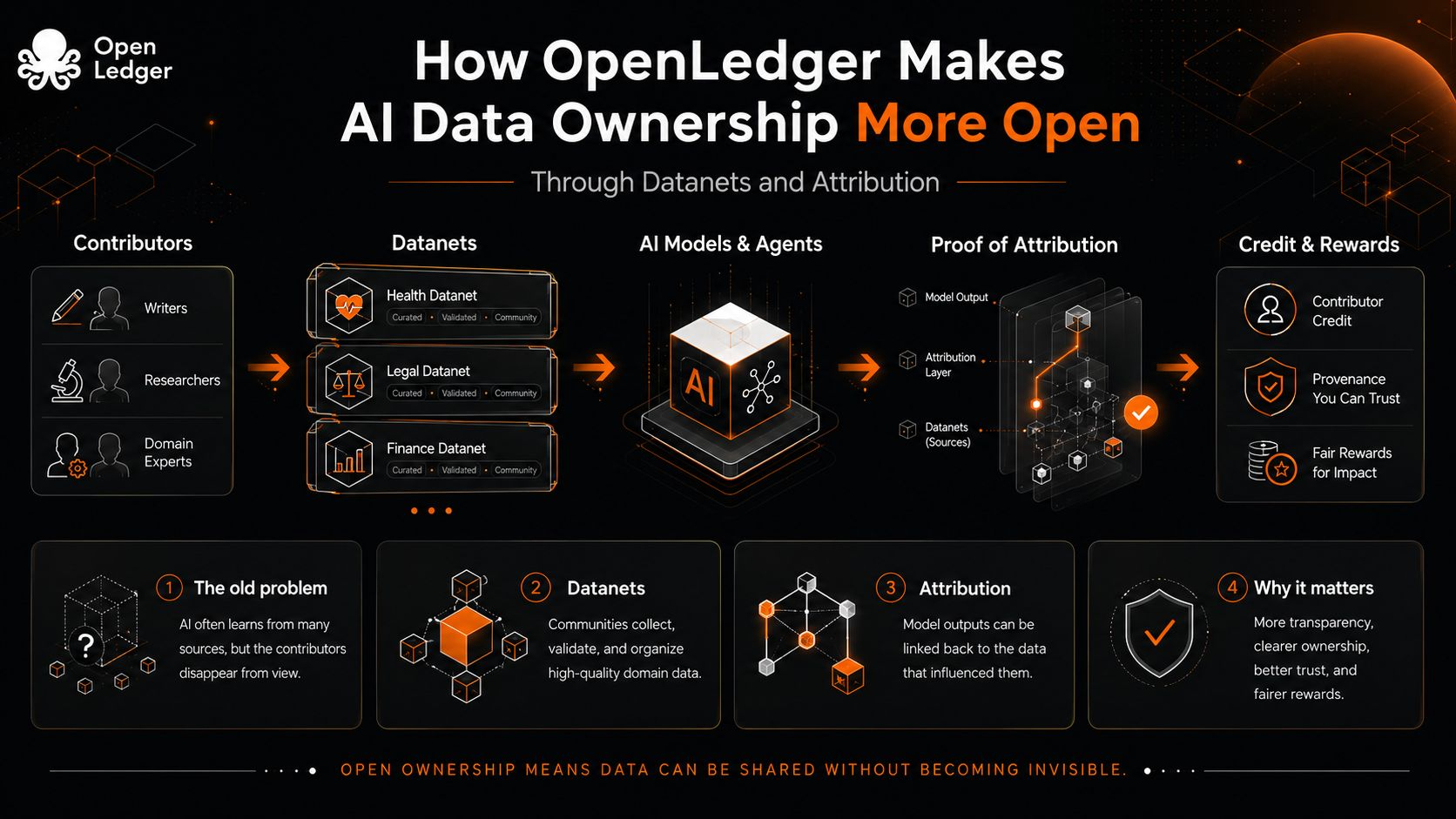
Ma la direzione conta. L'AI ha reso la proprietà stranamente chiusa, anche quando Internet sembra aperto. La conoscenza si muove ovunque, eppure il credito spesso non si muove da nessuna parte. I datanet e l'attribuzione suggeriscono un default diverso: i dati possono essere condivisi senza diventare privi di proprietario, utilizzati senza diventare invisibili e monetizzati senza pretendere che il modello abbia creato valore da solo.
Ecco perché vedo l'idea di OpenLedger meno come una risposta definitiva e più come una pressione esercitata sull'economia dell'AI. Pone una domanda semplice e difficile: se l'intelligenza è costruita da molte mani, perché solo la macchina finale dovrebbe avere un nome? Quella domanda sembra essersi fatta attendere, e forse è utile perché rifiuta di rimanere astratta.
