

Not long ago, if an AI model topped a benchmark leaderboard, most people accepted it as proof of superiority. Higher score meant better model. Simple.
That assumption is becoming harder to trust.
The problem with any scoring system is that once enough money starts responding to it, the score itself becomes the target. We've seen this everywhere. Schools teach to tests. Companies optimize quarterly optics instead of long-term health. Markets cluster around visible liquidity because traders know everyone is watching the same levels.
AI is heading down a similar path.
Benchmarks appear objective from a distance. Clean rankings. Percentage improvements. Easy-to-share leaderboards. Investors love them. Enterprise buyers often rely on them. Media narratives are built around them.
But numbers can be deceptive.
The issue isn't that benchmark gaming exists. Of course it does. If developers understand exactly how evaluations work, know which behaviors are rewarded, and know what buyers are paying attention to, why wouldn't they optimize for those metrics?
That's not necessarily dishonest. Often it's simply rational behavior.
The real problem emerges when benchmark performance and real-world reliability begin to drift apart.
That gap matters more than most people realize.
Consider AI systems supporting hospital triage decisions or financial risk analysis. The people using these tools don't care who won a benchmark six months ago. They care whether the system performs consistently when mistakes become expensive.
Yet many purchasing decisions are influenced long before real-world performance is tested. Benchmark narratives shape attention, funding, and adoption.
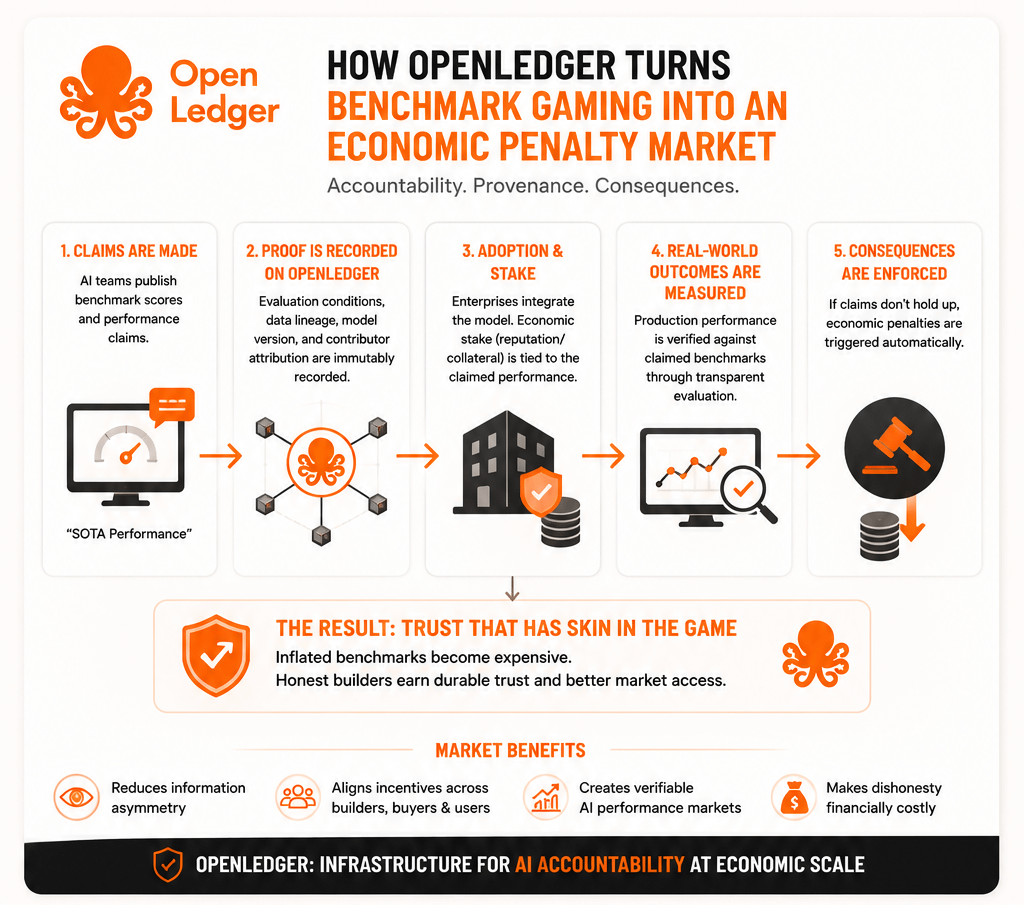
That's where the OpenLedger thesis becomes interesting.
Most discussions around OpenLedger focus on decentralized AI, data attribution, contributor rewards, or agent infrastructure.
But the angle I keep coming back to is accountability.
Because benchmark manipulation isn't fundamentally a measurement problem.
It's an incentive problem.
Today, if a company aggressively markets benchmark performance and gains market share from it, what happens if those claims don't translate into real-world results?
Usually very little.
Maybe some reputational damage.
Maybe a contractual dispute.
Maybe nothing at all.
That feels incomplete.

Crypto, despite its flaws, introduced something valuable: systems where economic incentives and accountability are directly linked.
Validators can be slashed.
Collateral can be liquidated.
Rules are enforced through economic consequences rather than vague expectations.
AI doesn't need to copy crypto culture.
But some of the underlying incentive design is worth studying.
This is where OpenLedger's attribution infrastructure starts looking less like bookkeeping and more like accountability infrastructure.
Who supplied the data?
Which model lineage generated an output?
What evaluation environment was used?
Which performance claims influenced adoption decisions?
Those questions seem administrative until money starts being lost.
Today, benchmarks function largely as marketing assets.
Screenshots.
Press releases.
Sales decks.
Social proof.
But if performance claims become economically traceable, the entire dynamic changes.
That's the interesting part.
Maybe OpenLedger doesn't create better AI.
Maybe it makes misleading claims more expensive.
That's a completely different investment thesis.
Think about insurance.
Unsafe drivers eventually pay higher premiums.
Credit markets punish repeated poor behavior.
Exchanges quietly adjust trust based on operational history.
These systems don't eliminate bad behavior.
They simply make it less attractive.
AI benchmark inflation could eventually follow the same path.
If model providers carried persistent economic reputation tied to their claims, and buyers could verify provenance instead of relying solely on polished narratives, performance marketing becomes harder to abuse.
Not impossible.
Just more costly.
And that may be what AI infrastructure ultimately evolves toward.
Because today's obsession with benchmark scores feels strangely immature.
The assumption that bigger numbers automatically mean better systems works in hype cycles.
It works far less well in regulated environments.
We're already seeing signs of this shift.
As AI moves into healthcare, finance, government, and other regulated sectors, trust stops being a philosophical discussion.
It becomes audits.
Compliance.
Governance reviews.
Procurement requirements.
Accountability frameworks.
The conversation changes quickly.
Of course, there are challenges.
Who defines trustworthy benchmarks?
How much transparency is enough?
How do you balance accountability with privacy and competitive secrecy?
And from a crypto perspective, one question matters above all:
A useful protocol does not automatically create a valuable token.
If $OPEN becomes embedded in recurring verification and accountability processes, there may be durable demand behind the network.
If it remains infrastructure that everyone references but nobody economically relies on, the investment case becomes weaker.
There's also a risk worth acknowledging.
Penalty systems can encourage defensive behavior rather than better behavior.
Sometimes people optimize to avoid blame instead of improving outcomes.
Finance has experienced that dynamic many times before.
Still, I keep coming back to the same conclusion.
The market assumes AI competition is primarily about intelligence.
Faster models.
Smarter reasoning.
More impressive demos.
Maybe that's yesterday's narrative.
Maybe the real scarcity isn't intelligence.
Maybe it's credible accountability.
And if benchmark scores increasingly function as persuasion tools rather than objective measurements, infrastructure that makes credibility economically meaningful may end up being more valuable than another incremental model improvement.
That's a far more interesting story than another leaderboard screenshot.