Qualche giorno fa ho dato un'occhiata al whitepaper sulla prova di attribuzione, aspettandomi il solito inquadramento tecnico di alto livello che la maggior parte dei progetti blockchain AI usa per descrivere meccanismi che non hanno completamente implementato. È lo standard. Pubblica un whitepaper che accenna a una metodologia, lancia un prodotto che la approssima e spera che nessuno colga il divario tra i due. Il whitepaper di Openledger non è così. Descrive due approcci specifici all'attribuzione con una vera profondità tecnica: approssimazioni della funzione di influenza per modelli più piccoli e attribuzione dei token basata su array di suffissi per quelli più grandi. La metodologia è reale. Qualcuno ha pensato attentamente a questo.
Poi ho esaminato l'approccio dell'array di suffissi con più attenzione.
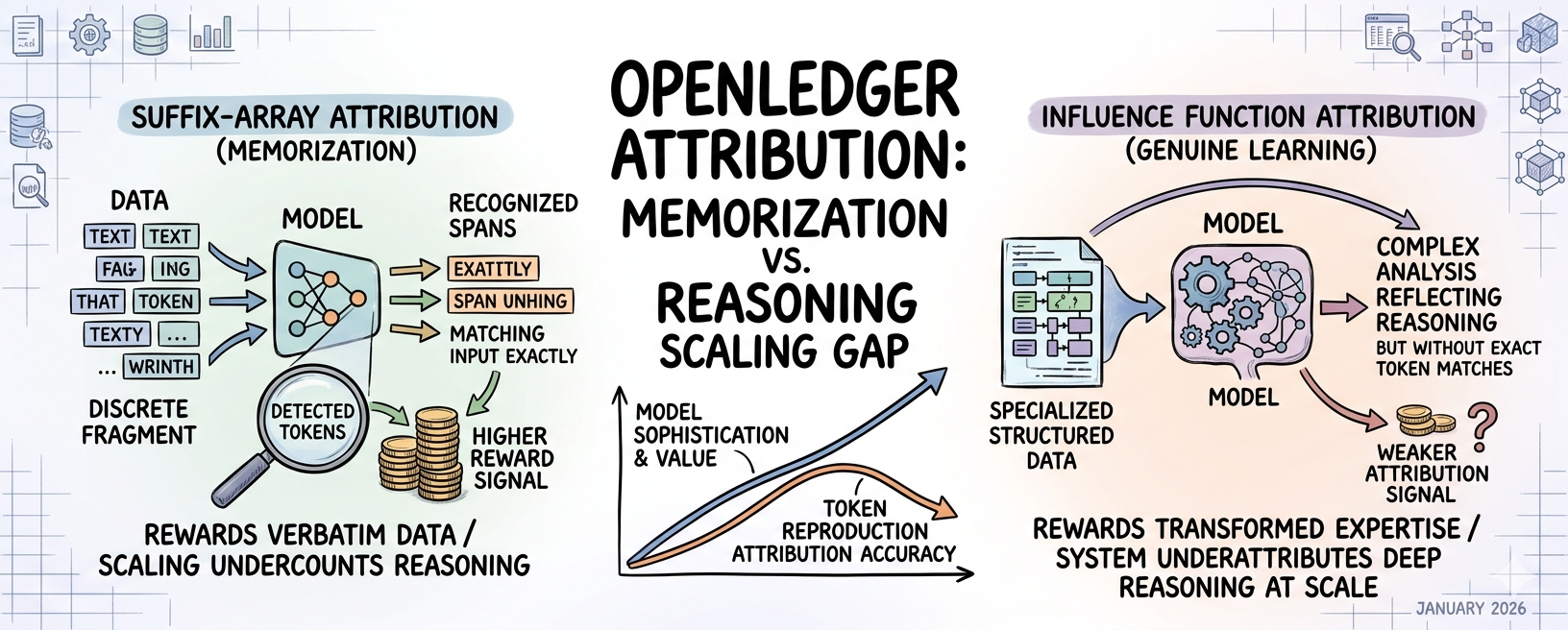
L'attribuzione tramite array di suffissi funziona comprimendo il corpus di addestramento e verificando se i token di output appaiono in intervalli memorizzati di quel corpus. L'idea è che se l'output di un modello contiene sequenze di token che corrispondono ai dati di addestramento compressi, puoi attribuire quella influenza a specifici contributori. È una tecnica legittima. Ma ha una proprietà di scalabilità specifica che il whitepaper riconosce in un modo che la maggior parte dei lettori probabilmente trascurerebbe senza fermarsi: l'approccio identifica gli intervalli memorizzati, non il ragionamento influenzato. Un modello che ha effettivamente appreso dall'esperienza nel dominio produrrà output che riflettono quella esperienza senza necessariamente riprodurre sequenze di token memorizzate. Il meccanismo di attribuzione premia l'influenza rilevabile dalla memorizzazione. Potrebbe contare sistematicamente meno il contributo dei dati che hanno insegnato al modello a ragionare piuttosto che i dati che il modello ha appreso a riprodurre. 🔍
Quella distinzione è estremamente importante per ciò che Openledger sta cercando di costruire. L'intera proposta di valore dei modelli linguistici specializzati, il motivo per cui esistono le datanet, il motivo per cui i contributori dovrebbero fornire dati rilevanti per il dominio piuttosto che testo estratto è che la vera esperienza nel dominio produce un ragionamento migliore, non solo una migliore memorizzazione. Un modello legale addestrato su un'analisi contrattuale strutturata dovrebbe produrre output che riflettono il ragionamento legale, non output che riproducono il linguaggio legale parola per parola. Ma l'attribuzione tramite array di suffissi misura il secondo tipo di influenza più affidabilmente del primo. Man mano che i modelli scalano e i loro output diventano meno simili ai dati di addestramento e più genuinamente trasformati da essi, il meccanismo di attribuzione potrebbe diventare progressivamente meno accurato proprio mentre i modelli diventano più sofisticati e più preziosi.
Sono seduto su un'implicazione specifica di questa situazione che non riesco a risolvere completamente. I contributori che forniscono i dati più genuinamente preziosi, esperti del settore che offrono analisi strutturate ed esempi ragionati con cura piuttosto che testo grezzo, potrebbero essere sistematicamente sottovalutati rispetto ai contributori che forniscono grandi volumi di dati testuali pesanti contenenti sequenze di token memorabili. Entrambi i profili di contributori vedrebbero eventi di attribuzione. Ma l'influenza del contributore esperto, che opera attraverso la trasformazione del ragionamento piuttosto che la riproduzione dei token, genererebbe segnali di attribuzione più deboli sotto il matching dell'array di suffissi. La struttura di ricompensa sembra funzionare. La distribuzione delle ricompense all'interno di quella struttura potrebbe non corrispondere alla distribuzione del valore reale contribuito.
Ho visto qualcosa di strutturalmente simile accadere con gli algoritmi di ranking dei motori di ricerca nei primi anni 2010. Gli algoritmi misuravano ciò che potevano misurare: densità dei link, frequenza delle parole chiave, ripetizione del testo, perché quei segnali erano tecnicamente gestibili. Ciò che non potevano misurare direttamente era la cosa che volevano realmente misurare: la vera esperienza e la conoscenza autorevole. Il risultato è stato che i contenuti ottimizzati per segnali misurabili superavano i contenuti con esperienza genuina fino a quando gli algoritmi non sono diventati abbastanza sofisticati da colmare quel divario. L'ottimizzazione è avvenuta non perché i creatori di contenuti fossero maliziosi, ma perché la misurazione era sistematicamente sfasata dal valore sottostante. Il meccanismo di attribuzione di Openledger potrebbe trovarsi esattamente alla stessa fase iniziale dell'algoritmo, misurando un proxy gestibile per l'influenza piuttosto che l'influenza stessa, e premiando il proxy piuttosto che il valore.
L'elemento veramente forte qui è che il whitepaper riconosce le limitazioni della metodologia piuttosto che nasconderle. Quella trasparenza è più di quanto la maggior parte dei progetti AI blockchain offra e segnala che il team comprende che la misurazione è un'approssimazione. L'aggiornamento del motore di attribuzione di gennaio 2026 è stato specificamente progettato per mantenere i collegamenti tra dati e output mentre i modelli evolvono, il che suggerisce che il team ha identificato il problema di scalabilità come qualcosa che richiede un'attenzione ingegneristica attiva piuttosto che una preoccupazione teorica da annotare e dimenticare.
C'è una versione di questa situazione in cui mi sbaglio. Openledger potrebbe aver implementato un approccio ibrido di attribuzione in produzione che integra il matching dell'array di suffissi con il peso della funzione di influenza per modelli più grandi utilizzando il metodo più costoso in termini di calcolo ma più accurato, precisamente dove il metodo più economico diventa inaffidabile. Se quell'ibrido esiste e sta funzionando, l'accuratezza dell'attribuzione non degrada su scala e i contributori esperti vengono accreditati in modo appropriato. Quello che non sono riuscito a trovare nella documentazione pubblica era qualsiasi conferma che il sistema di produzione utilizzi un approccio diverso dalla descrizione principale del whitepaper per modelli grandi.
Quello che vorrei vedere non è un aggiornamento tecnico del whitepaper. Una vera e propria scomposizione pubblica della metodologia di attribuzione per dimensione del modello, specificamente, quale approccio di attribuzione sta funzionando su quali modelli attualmente distribuiti su mainnet, e se esiste un approccio ibrido o supplementare per i modelli sopra una soglia di parametri specifica. Quella divulgazione, apparendo in qualsiasi aggiornamento della documentazione da quando l'aggiornamento del motore di attribuzione è stato consegnato a gennaio, mi direbbe se la limitazione della scalabilità è un'approssimazione nota che il team sta affrontando attivamente o un divario non riconosciuto tra ciò che il whitepaper descrive e ciò che il sistema di produzione misura attualmente. La sua assenza significa che i contributori più precisi di Openledger, quelli la cui esperienza trasforma il ragionamento del modello piuttosto che il vocabolario del modello, potrebbero essere quelli che il sistema è meno attrezzato per accreditare. Che è una posizione strana per un protocollo la cui intera proposta di valore è che rende l'influenza del contributo verificabile piuttosto che presunta.
