he estado revisando la arquitectura de openledger últimamente, principalmente alrededor del sistema de atribución y los incentivos para contribuyentes
la mayoría de la gente piensa que openledger es solo otro token de AI más un token de cripto, pero honestamente, la parte más interesante es el intento de construir una capa de coordinación económica alrededor de los datos de AI mismos
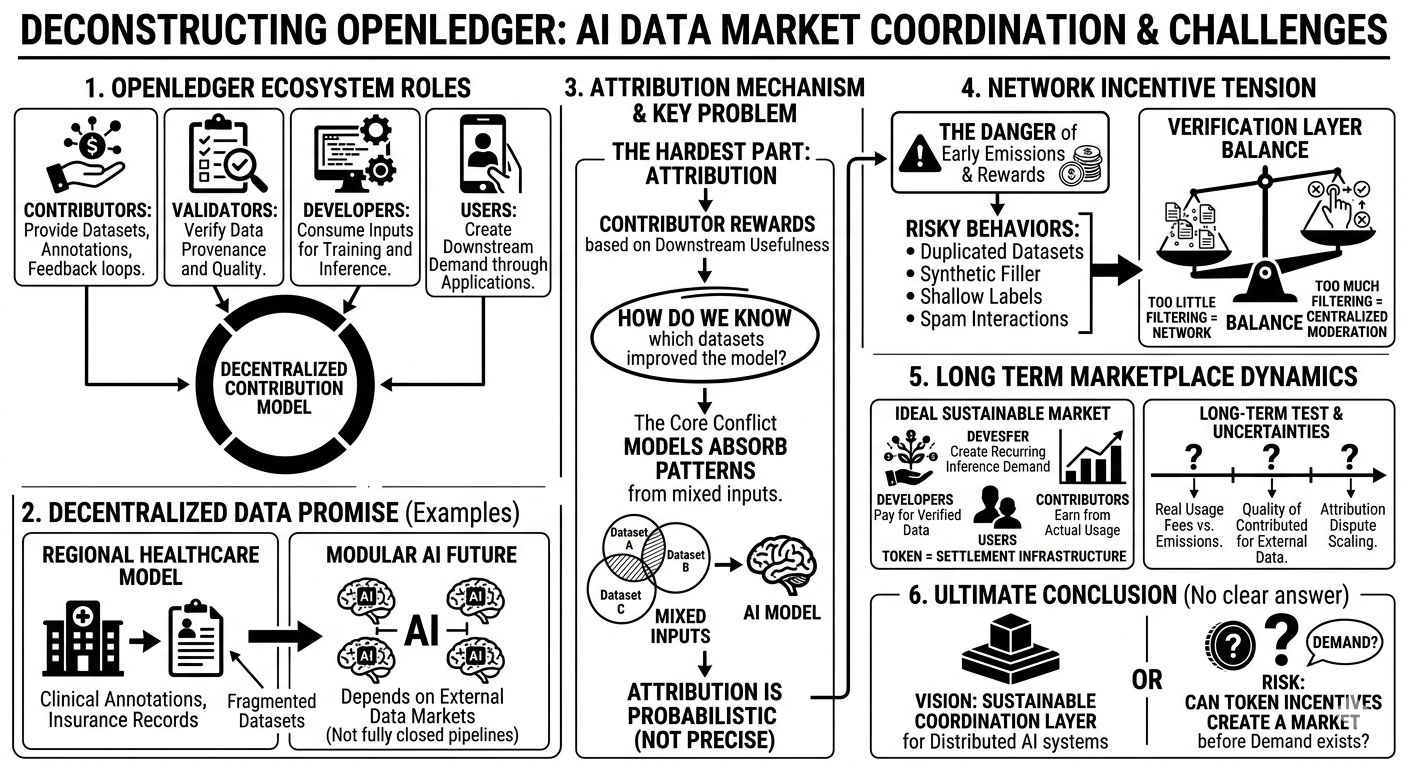
lo que llamó mi atención es cómo el protocolo intenta conectar a contribuyentes, validadores, desarrolladores y usuarios en un sistema compartido
los contribuyentes proporcionan anotaciones de conjuntos de datos y bucles de retroalimentación
los validadores verifican la procedencia y la calidad
los desarrolladores consumen esas entradas para entrenamiento e inferencia
los usuarios crean demanda descendente a través de aplicaciones
la capa de token se supone que coordina todo esto
el modelo de contribución descentralizada realmente tiene sentido en algunas situaciones
un modelo de salud entrenado en anotaciones clínicas regionales o registros de seguros probablemente necesite conjuntos de datos fragmentados que los sistemas centralizados no siempre priorizan recolectar
openledger parece estar diseñado en torno a la suposición de que los futuros sistemas de IA se vuelvan más modulares y dependan de mercados de datos externos en lugar de tuberías completamente cerradas
entonces está la atribución, que honestamente se siente como la parte más difícil de la arquitectura
si los contribuyentes son recompensados en función de la utilidad descendente, ¿cómo sabe el protocolo qué conjuntos de datos realmente mejoraron el modelo?
y esta es la parte en la que sigo pensando
los modelos de IA absorben patrones de entradas mixtas
un pequeño conjunto de datos de alta calidad puede mejorar los resultados más que millones de registros genéricos
así que la atribución se vuelve probabilística casi de inmediato
quizás eso sea aceptable
los contribuyentes probablemente no necesiten una precisión perfecta
solo necesitan un sistema que se sienta lo suficientemente creíble y resistente a la manipulación
pero una vez que las recompensas se vuelven significativas, la gente optimiza en torno a las métricas que mide la red
ahí es donde comienza a mostrarse la tensión de incentivos
si las emisiones dominan antes de que exista una demanda real, los contribuyentes pueden subir conjuntos de datos duplicados, rellenos sintéticos, etiquetas superficiales o interacciones de spam simplemente porque el protocolo recompensa la actividad
así que la capa de verificación importa tanto como la capa de contribución misma
openledger necesita seguimiento de procedencia, puntuación de calidad y filtrado escalable sin desviarse hacia una moderación centralizada disfrazada de descentralización
demasiado poco filtrado y la red se vuelve ruidosa
demasiado filtrado y la premisa descentralizada se debilita
la dinámica del mercado probablemente sea la verdadera prueba a largo plazo
idealmente, los desarrolladores pagan por conjuntos de datos verificados o acceso a modelos, los usuarios crean demanda de inferencia recurrente y los contribuyentes ganan por el uso real de la red en lugar de solo por emisiones
en esa versión, el token se convierte en infraestructura de liquidación en lugar de simple combustible de subsidio
pero toda la arquitectura depende de que la demanda de IA se fragmenta lo suficiente como para requerir este tipo de capa de coordinación
si las grandes plataformas continúan controlando el entrenamiento, la implementación y la retroalimentación del usuario internamente, los mercados de datos de IA descentralizados pueden seguir siendo relativamente estrechos
observando
tarifas de uso real versus emisiones
calidad de los conjuntos de datos contribuidos a lo largo del tiempo
demanda de desarrolladores por datos externos atribuibles
cómo escalan las disputas de atribución con la participación
aún no hay una conclusión clara
openledger podría estar construyendo una capa de coordinación sostenible para sistemas de IA distribuidos
o podría estar probando si los incentivos de token pueden crear un mercado antes de que el lado de la demanda exista completamente