
La mayoría de las conversaciones sobre IA hoy en día giran en torno a modelos que se vuelven más inteligentes, rápidos y autónomos. Pero hay una pregunta importante que aún se siente sin resolver en la industria: ¿quién realmente posee el valor creado detrás de los sistemas de IA?
Ahí es donde @OpenLedger ha comenzado a destacarse para mí.
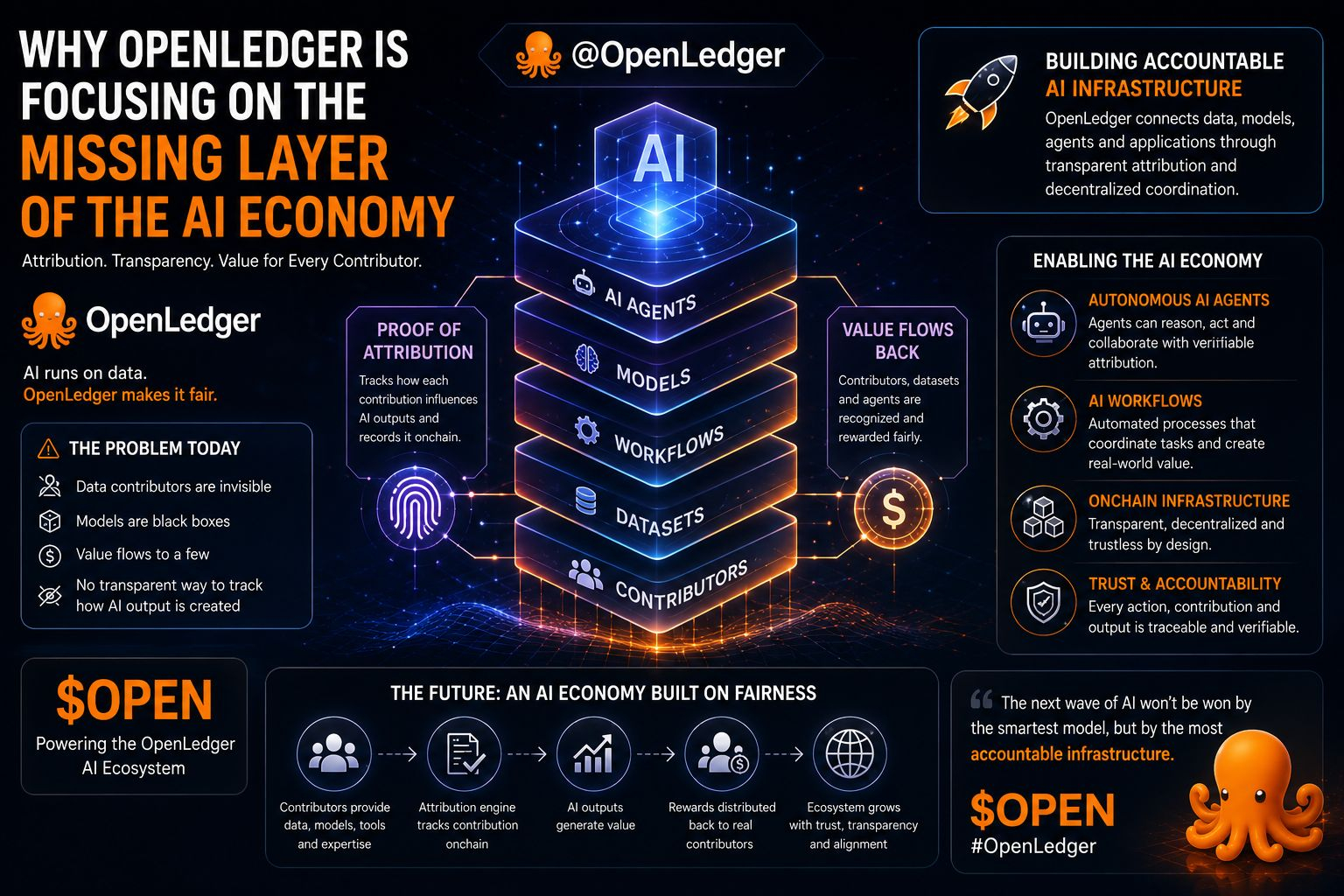
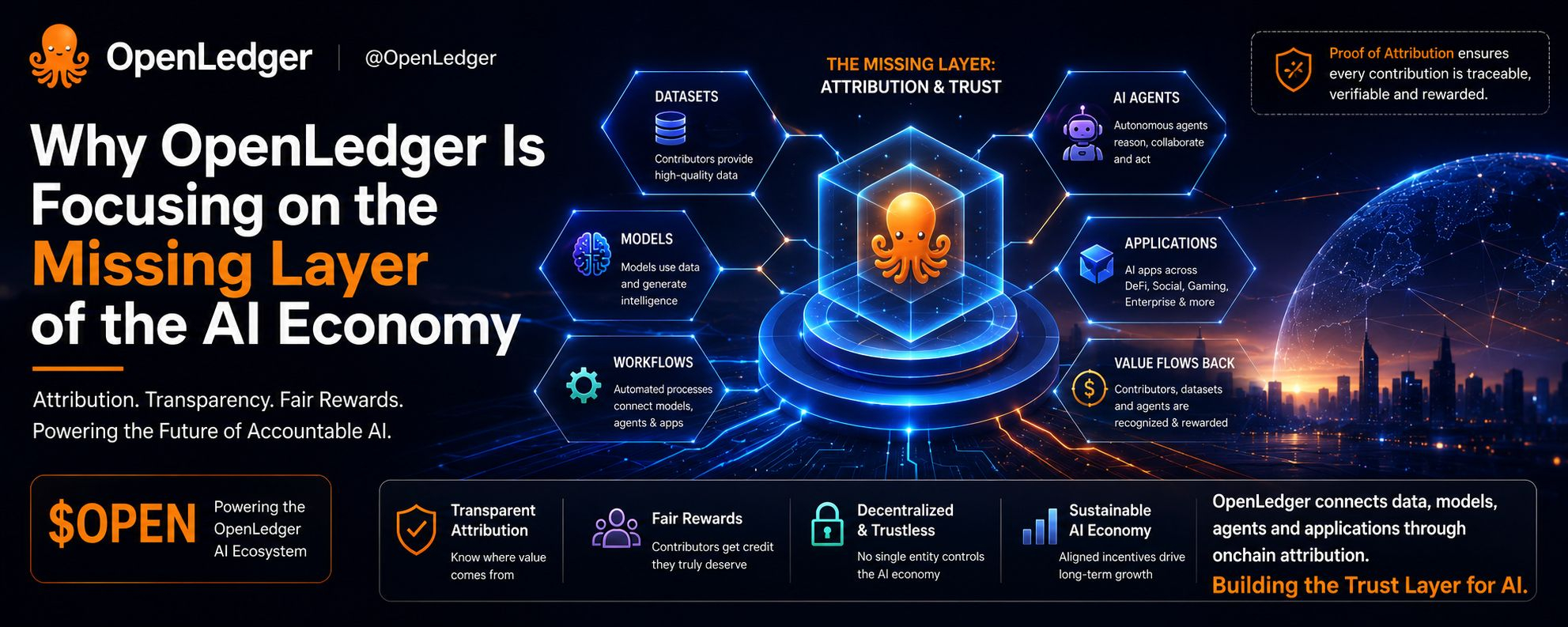
En lugar de tratar la IA como otra carrera de infraestructura cerrada, OpenLedger está construyendo en torno a la atribución, la transparencia y la coordinación entre conjuntos de datos, modelos, flujos de trabajo y agentes de IA. El proyecto sigue promoviendo la idea de que los contribuyentes no deberían desaparecer una vez que sus datos entran en el sistema.
Creo que esto importa más de lo que la gente se da cuenta.
La próxima fase de la IA probablemente no será solo humanos interactuando con chatbots. Incluirá agentes autónomos trabajando a través de aplicaciones, ejecutando flujos de trabajo, intercambiando información y generando actividad económica automáticamente. Una vez que eso suceda a gran escala, la atribución se convierte en un problema serio.
¿Cómo verificas qué datos influenciaron un resultado?
¿Cómo demuestran los desarrolladores su contribución?
¿Cómo coordinan los sistemas de IA de manera confiable sin depender del control centralizado?
OpenLedger parece estar enfocado en resolver esa capa a través de la Prueba de Atribución y la infraestructura de IA en cadena. En lugar de solo monetizar los resultados de IA, el sistema intenta conectar el valor de regreso a los contribuyentes, conjuntos de datos y agentes que participan dentro de la red.
Lo interesante es que esto se siente menos como una moda de IA a corto plazo y más como una infraestructura fundamental que se está construyendo temprano antes de que la economía de IA madure.
En este momento, la mayoría de la gente todavía se enfoca en productos de IA de front-end.
Pero con el tiempo, la capa de coordinación invisible debajo de la IA puede volverse aún más valiosa.