
Author: shew
Abstract
Welcome to the 'Tragedy of the Crypto Commons' series in the GCC Research column.
In this series, we will focus on those 'public goods' that are at critical nodes in the crypto world but are gradually losing their way. They are the infrastructure of the entire ecosystem but often face insufficient incentives, governance imbalances, and even the dilemma of gradual centralization. The ideals pursued by cryptographic technology and the redundancy stability in reality are undergoing severe tests in these corners.
In this issue, we focus on one of the most 'out-of-the-box' applications in the Ethereum ecosystem: Polymarket and its data indexing tools. Especially since this year, events surrounding Trump's election victory, the manipulation of oracles in Ukraine's rare earth trading, and the political bets on Zelensky's suit color have made Polymarket a focal point of public opinion, with its funding scale and market influence making these controversies impossible to ignore.
However, does this product representing 'decentralized prediction markets' truly achieve decentralization in its key foundational module – data indexing? Why has public infrastructure like The Graph failed to fulfill its expected role? What form should a truly usable and sustainable public good of data indexing take?
I. A chain reaction triggered by the failure of a centralized data platform.
In July 2024, Goldsky experienced a six-hour outage (Goldsky is a real-time blockchain data infrastructure platform for Web3 developers, providing indexing, subgraphs, and streaming data services to help quickly build data-driven decentralized applications), which caused a significant portion of projects in the Ethereum ecosystem to become paralyzed. For instance, DeFi frontends were unable to display user positions and balance data, and the prediction market Polymarket could not display accurate data, leading countless projects to appear completely unusable from the perspective of end-users.
This shouldn't happen in the world of decentralized applications. After all, the initial purpose of blockchain technology design is to eliminate single points of failure, right? The Goldsky incident exposed a disturbing fact: although the blockchain itself has achieved decentralization as much as possible, the infrastructure services used by applications built on it often include a significant amount of centralized services.
The reason is that blockchain data indexing and retrieval belong to 'non-excludable, non-competitive' digital public goods. Users often expect free or very low rates, but this requires continuous investment in high-intensity hardware, storage, bandwidth, and maintenance manpower. Without a sustainable profit model, a winner-takes-all centralized pattern will emerge: as long as one service provider gains a first-mover advantage in speed and capital, developers tend to direct all query traffic to that service, thus re-establishing a single-point dependency. Public welfare projects like Gitcoin have repeatedly emphasized that 'open-source infrastructure can create billions of dollars in value, but authors often cannot repay their mortgage from it.'
This warns us that the decentralized world urgently needs to enrich the diversity of Web3 infrastructure through public product funding, redistribution, or community-driven initiatives; otherwise, centralization problems will arise. We call on DApp developers to build local-first products and urge the tech community to consider the potential failure of data retrieval services in DApp design, ensuring that users can still interact with projects without data retrieval infrastructures.
II. Where does the data you see in Dapps come from?
To understand why events like Goldsky occur, we need to delve into the working mechanism behind DApps. For ordinary users, DApps typically consist of two parts: on-chain contracts and frontend pages. Most users have become accustomed to using tools like Etherscan to check the status of on-chain transactions and obtain necessary information from the frontend, while initiating transactions and interacting with contracts through the frontend. However, where does the data displayed on the user front end actually come from?
Indispensable data retrieval services.
Suppose the reader is building a lending protocol that requires displaying the user's position and the margin and debt status of each position. A simple idea is to read this data directly from the chain on the frontend. However, in practice, the contract for the lending protocol does not allow user addresses to query position data; the contract provides a function to query specific data using position IDs. Therefore, if we want to display the user's position on the frontend, we need to retrieve all positions in the current system and find those that belong to the current user. This is like asking someone to manually search millions of pages of ledgers to find specific information – technically feasible but extremely slow and inefficient. In fact, it's very difficult for the frontend to complete this retrieval process; large DeFi projects' retrieval tasks often take several hours even when directly relying on local nodes on the server.
Therefore, we must introduce infrastructure to accelerate data acquisition. Companies like Goldsky provide these data indexing services to users. The diagram below shows the types of data that data indexing services can provide for applications.

At this point, some readers may wonder about the decentralized data retrieval platform TheGraph within the Ethereum ecosystem. What is its relationship with Goldsky, and why have so many DeFi projects not opted for a more decentralized TheGraph but rather used Goldsky as their data provider?
The relationship between TheGraph / Goldsky and SubGraph
To answer the above questions, we need to first understand some technical concepts.
SubGraph is a development framework that allows developers to write code to read and aggregate on-chain data and display this data on the frontend using certain methods.
TheGraph is one of the early decentralized data retrieval platforms, which developed the SubGraph framework using AssemblyScript. Developers can use the subgraph framework to write programs that capture contract events and write these contract events to the database. Users can then use GraphQL methods to read this data or directly use SQL code to read from the database.
We generally refer to service providers running SubGraph as SubGraph operators. Both TheGraph and Goldsky are actually custodians of SubGraph. Since SubGraph is just a development framework, the programs developed using this framework need to be run on servers. We can see that the Goldsky documentation contains the following content:
Some readers may wonder why there are multiple operators for SubGraph?
This is because the SubGraph framework only stipulates how data is read from blocks and written to the database.
How data flows into the SubGraph program and where the final output results are written to has not been implemented; these contents need to be implemented by the SubGraph operators themselves.
Generally, SubGraph operators will modify nodes to achieve faster speeds. Different operators (like TheGraph, Goldsky) have different strategies and technical solutions.
TheGraph currently uses the Firehouse technology solution, which, once introduced, allows TheGraph to achieve faster data retrieval than in the past, while Goldsky has not publicly open-sourced its core program for running SubGraph.
As mentioned above, TheGraph is a decentralized data retrieval platform. Taking the Uniswap v3 subgraph as an example, we can see that there are numerous operators providing data retrieval for Uniswap v3. Consequently, we can also regard TheGraph as an integrated platform for SubGraph operators, where users can send their written SubGraph code to TheGraph, and then some operators within TheGraph can assist users in retrieving data.
Goldsky's charging model
For centralized platforms like Goldsky, there is a simple billing standard based on resource usage, which is the most common billing method for SaaS platforms on the internet. Most technicians are very familiar with this method. The diagram below shows Goldsky's price calculator:
TheGraph's charging model
TheGraph has a completely different fee structure from conventional billing methods, which is related to the token economics of GRT. The diagram below illustrates the overall token economics of GRT:
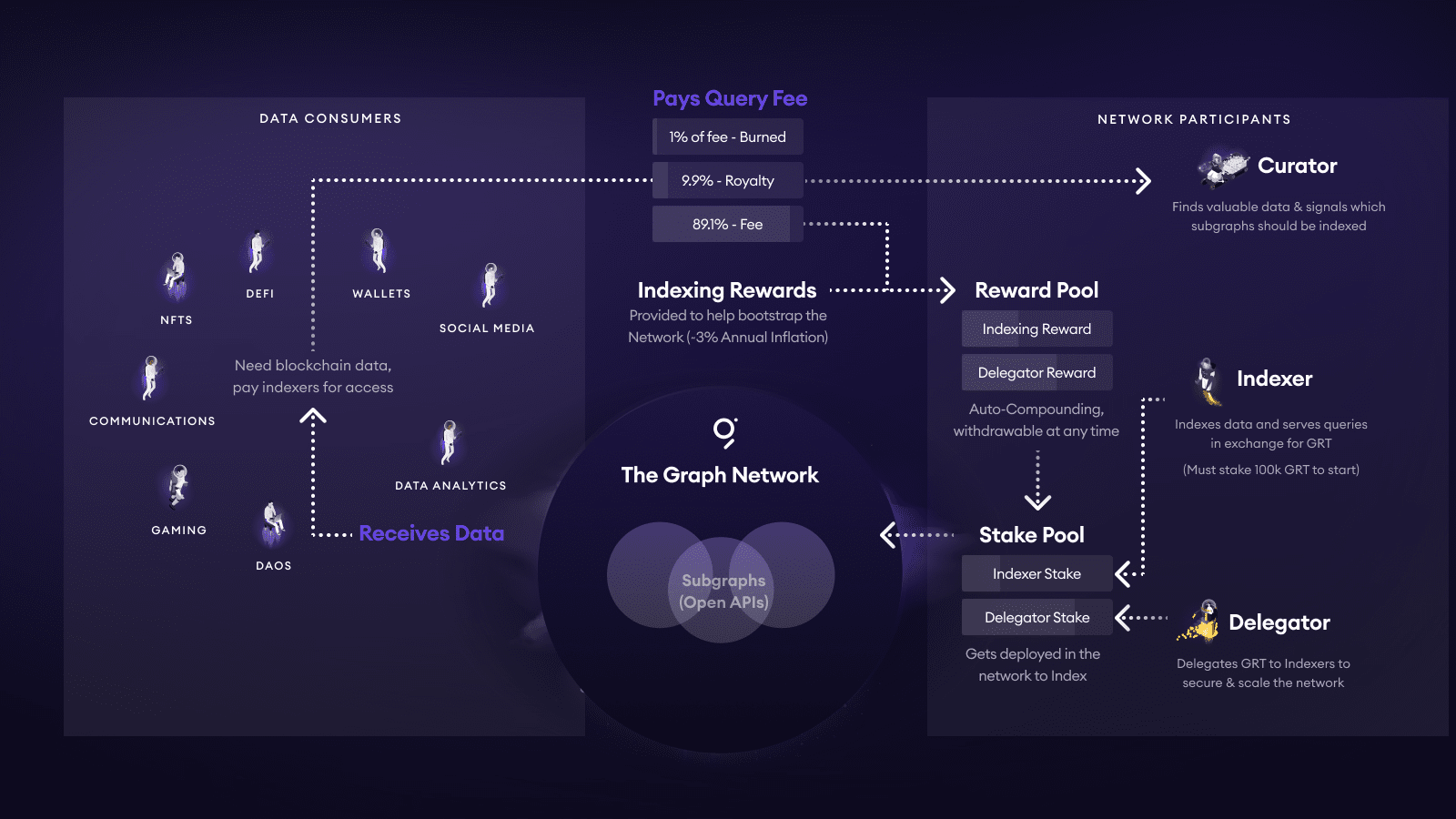
Whenever a DApp or wallet makes a request to a Subgraph, the Query Fee paid will be automatically split: 1% is burned, about 10% flows into the curation pool of that Subgraph (Curator / Developer), and the remaining ≈ 89% is distributed to the Indexer and their Delegator based on an exponential rebate mechanism.
Indexers must first self-stake ≥ 100k GRT to go live; if they return incorrect data, they will be penalized (slashing). Delegators delegate GRT to Indexers and proportionally share the aforementioned 89% chunk.
Curators (usually developers) stake GRT on their own Subgraph's bond curve through Signal; the higher the Signal number, the more they can attract Indexers to allocate resources. Community experience suggests self-staking 5k–10k GRT can ensure several Indexers take on requests. Meanwhile, curators can also receive that 10% Royalty.
The Graph's per-query fee:
Register an API KEY in TheGraph's backend and use that API KEY to request data retrieval from TheGraph's operators. This part of the request is charged according to the number of requests, and developers need to pre-load a certain amount of GRT tokens within the platform as the cost for API requests.
The Graph's Signal staking fee:
For the deployers of SubGraph, they need operators within TheGraph platform to help retrieve data. According to the revenue-sharing method mentioned above, they need to tell other participants that their query service is better and can obtain more money, which requires staking GRT, similar to advertising and guaranteeing their revenue, so that others will come.
During testing, developers can deploy SubGraph to TheGraph platform for free, during which TheGraph will assist users in some retrieval and provide a free quota for testing, which cannot be used in production environments. If developers find that the SubGraph runs well in TheGraph's official testing environment, they can publish it to the public network and wait for other operators to participate in retrieval. Developers cannot directly pay a specific operator for guaranteed retrieval; instead, they let multiple operators compete to provide services, avoiding single-point dependencies. This process requires using GRT tokens to curate (Curating) their own SubGraph (also known as Signal operations), meaning developers stake a certain number of GRT in the SubGraph they deployed, but operators only join the retrieval work of the SubGraph when the staked GRT reaches a certain amount (previously consulted data suggested 10,000 GRT).
Poor charging experience confuses developers and traditional accounting.
For most project developers, using TheGraph is actually a relatively troublesome thing. Purchasing GRT tokens is relatively easy for Web3 projects, but the process of curating an already deployed SubGraph while waiting for operators is quite inefficient. This stage presents at least two issues:
The uncertainty regarding the amount of GRT staked and the time required to attract operators. I directly consulted TheGraph's community ambassadors to determine the amount of GRT to stake during my past deployments of SubGraph, but for most developers, this data is not easy to obtain. Additionally, after staking sufficient GRT, it also takes some time for operators to get involved in retrieval.
The complexity of cost accounting and accounting. Since TheGraph uses a token economics mechanism to design its charging standards, this complicates cost calculations for most developers. More practically, if a company wants to account for this expenditure, accountants may also struggle to understand the components of this cost.
'Is it good or centralized?'
Clearly, for most developers, choosing Goldsky directly is a simpler matter. The billing method is easy for everyone to understand, and as long as they pay, it can be almost immediately available, significantly reducing uncertainty. This has also led to a reliance on a single product in blockchain data indexing and retrieval services.
Clearly, TheGraph's complex GRT token economics has affected its widespread application. Token economics can be complex, but these complexities should not be exposed to users; for instance, the curation staking mechanism of GRT should not be exposed to users. A better approach for TheGraph is to provide users with a simplified payment page directly.
The above criticism of TheGraph is not my personal opinion; well-known smart contract engineer and Sablier project founder Paul Razvan Berg has also expressed this perspective in a tweet. The tweet mentioned that the user experience of publishing SubGraph and GRT billing is extremely poor.
III. Some existing solutions
Regarding how to solve single-point failures in data retrieval, it has already been mentioned in the text that developers can consider using TheGraph services, although the process will be more complex. Developers need to buy GRT tokens for staking curation and to pay API fees.
Currently, there are many data retrieval software options within the EVM ecosystem. For specific references, check out Dune's 'The State of EVM Indexing' or rindexer's collection of EVM data retrieval software. Another newer discussion can be referred to in this tweet.
This article will not discuss the specific reasons for the emergence of Goldsky, as currently, according to the content of the Goldsky report, Goldsky knows the exact reasons but is only prepared to disclose them to enterprise-level users. This means that no third party can know what kind of failure Goldsky has encountered at this time. According to their report, it can be inferred that there may have been issues when writing back the retrieved data to the database, and in this brief report, Goldsky mentioned that the database could not be accessed normally and only obtained access to the database after cooperating with AWS.
In this section, we mainly introduce other solutions:
ponder is a simple data retrieval service software with a good development experience and easy deployment, allowing developers to rent servers for deployment.
Local-first is an interesting development philosophy that calls for developers to provide a good user experience even in the absence of a network. In the presence of blockchain, we can relax the limitations of local-first to some extent, ensuring that users can have a good experience when they can connect to the blockchain.
ponder
Here, I recommend using ponder instead of other software for the following reasons:
Ponder has no vendor dependencies. Originally, ponder was a project built by individual developers, so compared to other companies' data retrieval software, ponder only requires users to fill in the Ethereum RPC URL and Postgres database link.
Ponder offers a good development experience. I have used ponder for development multiple times in the past, and since ponder is written in TypeScript, with the core library mainly relying on viem, the development experience is excellent.
Ponder has higher performance.
Of course, there will be some issues as well. Currently, ponder is still in rapid development, and developers may encounter situations where previous projects cannot run due to version-breaking updates. Considering that this article is not a technical introductory piece, further discussion of ponder's development details will not be included; readers with technical backgrounds can refer to the documentation themselves.
A more interesting detail about ponder is that it has also begun some commercialization, but the commercialization path of ponder aligns very well with the 'isolation theory' discussed in the previous article.
Here, we briefly introduce the 'isolation theory.' We believe that the public nature of public goods allows them to serve any number of users, so charging for public goods will lead to some users discontinuing their use, which does not maximize social benefits (economically described as 'no longer Pareto optimal'). Theoretically, public goods can charge fees by offering differential pricing to each individual, but the costs of differential pricing are likely to exceed the surplus generated by it. Therefore, the reason public goods are open for free is not that they should be inherently free, but because any action of charging a fixed fee will harm social benefits, and currently, there is no cheap way to implement differential pricing for everyone. The isolation theory proposes a method for pricing within public goods: by isolating a homogeneous group through certain methods and charging this part of the homogeneous group. First, the isolation theory does not prevent everyone from enjoying public goods for free, but it does propose a method to charge certain groups.
ponder uses a method similar to the isolation theory:
Firstly, deploying ponder still requires certain knowledge, and developers need to provide external dependencies such as RPC and databases during the deployment process.
Moreover, after deployment is completed, developers need to continuously maintain the ponder application, such as using a proxy system for load balancing to avoid data requests affecting ponder's retrieval of on-chain data in the background thread. These can be somewhat complex for general developers.
Currently, ponder has an automated deployment service marble in internal testing, allowing users to deliver code to the platform for automatic deployment.
Clearly, this is an application of the 'isolation theory.' Developers who are unwilling to maintain the ponder service themselves are isolated, and they can pay to obtain a simplified deployment of the ponder service. Of course, the emergence of the marble platform does not affect other developers' ability to use the ponder framework for free and self-host their deployments.
What are the audiences of ponder and Goldsky?
Public goods like ponder, which have no vendor dependencies, are becoming more popular for developing small projects compared to other vendor-dependent data retrieval services.
Some developers with large projects may not necessarily choose the ponder framework because large projects often require retrieval services to have sufficient performance, and service providers like Goldsky often provide adequate availability guarantees.
Both have some risk points. From the recent Goldsky incident, developers would be better off maintaining their own ponder services to be prepared for potential third-party service outages. Additionally, when using ponder, one may need to consider the validity of the data returned by RPC; not long ago, Safe reported an incident where the retrieval crashed due to RPC returning erroneous data. Although there is no direct evidence indicating that the Goldsky incident was also related to RPC returning invalid data, I suspect that Goldsky may have encountered a similar situation.
local-first development philosophy
Local-first has been a topic of discussion for the past few years. Simply put, Local-first requires software to have the following functionalities:
Offline work
Cross-client collaboration
Currently, most discussions related to local-first technology involve CRDT (Conflict-free Replicated Data Type) technology. CRDT is a conflict-free data format that allows users to automatically merge conflicts when operating across multiple ends to maintain data integrity. One simple view is to consider CRDT as a data type with a simple consensus protocol; in distributed scenarios, CRDT can ensure data integrity and consistency.
However, in blockchain development, we can relax the aforementioned Local-first requirements for software. We only require that when there is no backend index data provided by project developers, users can still maintain a minimum level of usability on the frontend. Meanwhile, the local-first requirement for cross-client collaboration has actually been resolved by blockchain.
In the context of DApps, the local-first philosophy can be realized as follows:
Cache key data: The frontend should cache important user data, such as balances and position information, so that even if the indexing service is unavailable, users can still see the last known status.
Degrade functionality design: When the backend indexing service is unavailable, the DApp can provide basic functionality. For example, when the data retrieval service is unavailable, some data can consider using RPC to read on-chain data directly, ensuring that users see the latest status of existing data.
This local-first DApp design philosophy can significantly enhance the resilience of applications, avoiding situations where applications become unusable after the data retrieval service crashes. Without considering ease of use, the best local-first applications should require users to run nodes locally and then use tools like trueblocks to retrieve data locally. Discussions about decentralized retrieval or local retrieval can refer to the tweet 'Literally no one cares about decentralized frontends and indexers.'
IV. Conclusion
The six-hour Goldsky outage has sounded the alarm for the ecosystem. Although the blockchain itself has decentralized and anti-single-point-failure characteristics, the application ecosystem built on it still heavily relies on centralized infrastructure services. This dependency poses systemic risks to the entire ecosystem.
This article briefly introduces why the well-known decentralized retrieval service TheGraph is not widely used today, particularly discussing some complexities brought by GRT's token economics. Finally, the article discusses how to build a more robust data retrieval infrastructure, encouraging developers to use the self-hosted data retrieval development framework ponder as an emergency response option, while also introducing ponder's good commercialization path. Lastly, the article discusses the local-first development philosophy, encouraging developers to build applications that remain usable without data retrieval services.
Currently, many Web3 developers are aware of the single point of failure issue with data retrieval services. GCC hopes more developers will pay attention to this infrastructure and attempt to build decentralized data retrieval services or design a framework that allows DApp frontends to operate even without data retrieval services.


